清华光电融合芯片算力是GPU的3000多倍?媒体搞出的大新闻(5)

透射是不改变相位的。我们看样品光束和参考光束经过的反射,就会发现,在右边屏幕发生干涉时,两束光的相位改变次数是一样的(全反射镜也算一次,各改变了两次),相位相同,相长干涉。而在上边屏幕发生干涉时,样品光束的相位改变多一次(样品光束两次,参考光束一次),两者反相了,相消干涉。
那MZI是怎么用到光计算里面的?马赫与曾德尔是提出实验构想,具体的干涉实现多种多样,只要是光束经过分光器,经不同路径又发生干涉,就符合大意,通称为MZI。光的加法很简单,就是两束光通过波导管传输,在波导管相遇的地方,信号被方向耦合器加在一起。而光的乘法就是MZI的干涉效应实现的,当然器件比原始的马赫-曾德尔干涉仪要小得多了,有很多改进。
单个经典的MZI:两个分光器BS,两个反射镜M,三个移相器
如图,一个经典的MZI和原始的马赫-曾德尔干涉仪大致类似,两个分光器就等于半镀镜,两个反射镜也一样。但是,多了三个移相器,入射的光也变成两个了,E1和E2两束光都是一半透射一半90度角反射,透射的和另一束光反射的正好同方向。E1和E2就代表一个2 × 1的矩阵E = [E1, E2],这个矩阵经过MZI乘以2 × 2的矩阵U,就变成另一个2 × 1的矩阵E’ = [E’1,E’2],公式是E’ = E * U。移相器的三个角度值α/β/θ,代表相乘的2 × 2的矩阵U,U的数值是可变的(也就是可编程的),但必须是酉矩阵(unitary matrix,也叫幺正矩阵),所以矩阵的4个值用3个参数可代表。酉矩阵的定义是,它和另外一个矩阵乘,能得出对角线全是1的单位矩阵,具有一定的对称性。具体的数学公式很复杂,但大致原理并不难明白。光线在MZI里根据相位干涉,两条光路相当于两个并行的数值计算。这个MZI就代表了2 × 2的矩阵U。

黄光裕官宣进军汽车行业 探索汽车市场新可能

广西车厘子10元2盒是真的

四川人大常委会原副主任甘道明逝世 享年78岁

中方的意思日本已读懂,石破茂最新对华表态,4字最令美国担心 和平共处震动美国

美国花高价挖走中国天才,谁知对方毕业就回国,出手便成全球第一
广西车厘子10元2盒是真的
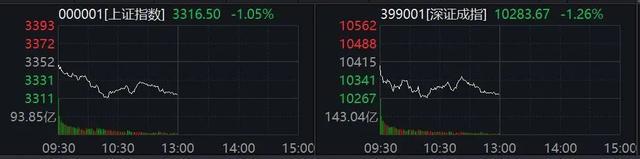
A股突变!两大板块,掀涨停潮 预制菜与新零售领涨

荷兰天然气价格升至逾1年高位 供应短缺推高成本

特斯拉2024年全球交付超178.9万辆 创历史新高

女子举报国企丈夫包养情人 细节曝光 涉事单位正调查中

42岁辅警去世生前协助侦破1000余起刑案 忠诚履职守护平安

2025年进度条已开启 物流业风险与机遇并存

打开2025年的中国时刻 万象更新奋勇前行

瑞士网红“猫女”去世 整形名媛终年84岁

韩总统官邸你推我挤一片混乱!

潘展乐被美媒评为世界第一 巴黎奥运创纪录夺魁

WPS日活破亿 国产办公软件新篇章

向老人泼水涉事学校被曝拖欠170万 食堂纠纷升级

逮捕尹锡悦这一早上发生了什么 警卫冲突引关注

批评特朗普的前议员切尼被授总统勋章 表彰其将国家置于党派之上

工艺品店卖春联后被判“违规”遭断电?管理方:他听不懂好赖话

村民买柴油被罚3万元罚款已退还 法律与民生碰撞引热议
黄光裕官宣进军汽车行业 探索汽车市场新可能

安倍晋三明明是日本人,可为啥在他死后,墓碑上却刻着中国汉字 文化渊源深厚

美国国内恐怖主义亮起红警 新奥尔良血色开局

美论坛:如果美国向中国发射200枚核武器,中国还有能力反击吗? 后果不堪设想

外媒:中国是俄罗斯最大的贸易伙伴,占俄贸易额的三分之一 中俄经贸关系持续深化

整容成猫女瑞士社交名媛去世 传奇一生终落幕

科普:浏览黄色网站违法吗?为何成人网站屡禁不止
出售美墨边境墙建设材料,马斯克:拜登100%叛国 低价拍卖引争议

韩总统官邸你推我挤一片混乱,调查官执行逮捕令,与警卫发生推搡

台北跨年转播央视晚会承包商回应!

泽连斯基称支持在乌克兰部署欧洲部队,强调与北约接轨的重要性

元旦实现了上四休三!网友直呼:好爽
四川人大常委会原副主任甘道明逝世 享年78岁
相关新闻
华为打造AI时代算力底座 共筑算网融合新未来
2024-09-29 09:28:00华为打造AI时代算力底座又一芯片公司,被GPU改变命运 ARM新贵求售启示录
2024-09-23 05:49:54又一芯片公司三大指数集体低开 创业板指跌近1% 算力芯片领跌
【三大指数集体低开 创业板指跌近1%】沪指低开0.66%,深成指低开0.86%,创业板指低开0.97%,算力芯片、智慧灯杆、通感一体化等板块指数跌幅居前
2024-08-02 13:07:29三大指数集体低开苹果A18芯片发布:CPU提升30%,GPU性能飞跃40%
在9月10日的凌晨1点,苹果的发布会拉开了帷幕。发布会上,苹果揭晓了其最新的A18芯片,这款芯片采用了先进的3纳米工艺制造,将首次装载于iPhone16系列之中
2024-09-10 08:50:04苹果A18芯片发布:CPU提升30%我国将构建天地一体化算力网络 推动算力“上天”成趋势
12月14日,2024科学家创新大会在雄安召开。会上,多位院士专家讨论了遥感产业的未来发展,认为推动算力“上天”将成为产业未来发展的大趋势
2024-12-17 02:16:45我国将构建天地一体化算力网络华为将参加2024中国算力大会 共筑算力新时代底座
2024中国算力大会将于9月27日至29日在河南郑州举行,华为将参与此次大会,主题定为“共赢算力新时代”
2024-09-25 09:12:00华为将参加2024中国算力大会