清华光电融合芯片算力是GPU的3000多倍?媒体搞出的大新闻

近年来,人工智能突破引发了高性能GPU需求暴增。GPU生产商英伟达2023年市值增长239.2%,2024年又涨了45.9%,截至2月12日市值达到1.78万亿美元。GPU已经成为全球高科技业界最炙手可热的商品之一,美国商务部还特别针对中国限制GPU性能,连游戏玩家用的RTX 4090都不让卖了。
在这种情况下,一些媒体注意到了中国的一项成果。2023年10月25日,清华大学戴琼海院士与乔飞副研究员团队在《自然》杂志发表论文《All-analog photoelectronic chip for high-speed vision tasks》,介绍了光电融合芯片ACCEL。一些新闻标题说这款芯片“算力是商用GPU的3000多倍”,内容中具体是“在包括 ImageNet 等智能视觉任务实测中,相同准确率下,比现有高性能 GPU 算力提升三千倍,能效提升四百万倍,具备超高算力、超低功耗的特点”。
这是真的吗?这种光电融合芯片,能否在行业中应用推广,帮助中国突破GPU封锁?
其实这很大程度是误读,因为这些媒体把ACCEL和商用GPU的“算力”拿来对比的方法有问题。简而言之,是把前者的瞬间表现和后者的持续表现混为一谈了。但要深入理解问题在哪里,我们就要先来了解下光电融合芯片以及商用GPU芯片的基本知识,包括它们的架构与性能特点。
光电融合芯片ACCEL,顾名思义,它是一个芯片,但融合了“光”和“电”的特性。芯片有逻辑芯片和存储芯片两大类(还有一类半导体器件是功率放大器,有时也称为功率芯片),高性能GPU就是将计算能力强大的逻辑芯片与多达几十G容量的先进存储芯片封装在一起。
从性质上看,ACCEL是逻辑芯片,功能是计算,而且计算功能限定为图像的模式识别。目前它还是非常专门的逻辑计算芯片,没有通用计算功能。
世界第一款GPU:英伟达GeForce 256
GPU能不能做通用计算呢?以前不行,现在可以。GPU芯片最初功能专一,其前身叫“显卡”,处理的是2D屏幕上像素点的显示问题。1999年英伟达推出第一款GPU芯片GeForce 256时,正式提出了GPU的命名Graphics Processing Unit,能够处理许多本来由CPU负责的T&L(Transforming & Lighting,几何光影转换)算法,已经有了通用处理器的一些特性。此时市场上CPU的价值还是更被看重,用CPU来处理图像显示问题(如用CPU实现的“软光栅”算法)浪费了,就用GPU来打辅助,用其多核来并行处理天生适合并行的图像显示问题。
英特尔当时认为,GPU是辅助的,没太大价值,于是干脆和自家的CPU集成在一起卖,叫集成显卡。一般人都不知道自己的机器里有集成显卡,专门买独立显卡的人才比较懂GPU。这可能是英特尔犯的最大错误,到2022年才开始推出独立显卡,和英伟达、AMD抢生意。
到2003年,GPGPU(General Purpose computing on GPU,GPU通用计算)的概念被提出来。之后随着GPU能力越来越强,到2010年之后,高性能GPU已经能完成非常多不同种类的计算任务,如图形3D、神经网络、科学计算、云计算、数据中心、AIGC、大语言模型等等,非常通用了。到这个阶段,高性能GPU就显得比CPU有价值多了,价格也拉开了几十倍的差距。可以这样说,CPU能计算的GPU都能算,而GPU能快速完成的许多计算任务,CPU理论上能完成但实在太慢,等于不行。所以现在的情况是,简单的任务才会让便宜的CPU干,CPU成打辅助的了。GPU霸主英伟达的市值,2024年2月12日达到了老牌CPU霸主英特尔的9.7倍,这就是GPU强大计算能力的直接体现。
下面我们来看,光电融合芯片ACCEL是如何做计算的。它融合了“光”与“电”,其中“光”是指“光计算”(photonic computing),“电”就是电子。跟电子相比,光子有很突出的性能,例如没有静止质量,光子之间没有相互作用力,互相几乎不干扰,不受电磁场干扰等等。在通信业中,光纤就比铜缆的带宽大得多,能耗还小,光通信是成熟应用了。电子的优点是,天生适合二进制逻辑计算,因为有半导体的神奇功能,通过电压变化,器件就能在导通和阻断之间灵敏变化,正好代表了0和1。
《三体》电视剧中的人列计算机
稍有计算机知识的人,会明白基于电流、电压的半导体做计算是比较自然的,二进制逻辑不难懂。就如刘慈欣《三体》中描述的,用几个士兵就能演示与、或、非基本逻辑计算,进而实现加减乘除等数学运算,直到整个计算机系统。
集成光路示意图
光子其实也是可以搞计算的,而且是零能耗。上图是一个与“集成电路”类似的“集成光路”,激光器产生的光在“光路”的各种元器件里传输处理,效果相当于计算。你可能会想到我的朋友袁岚峰经常介绍的、中国科学技术大学研发的“九章”系列量子计算机,但它和这里说的光计算并不是一回事。九章也是用光来做计算,但它是利用单个光子的量子特性,如叠加和纠缠。而一般说的光计算,用的还是大量光子的干涉、衍射等经典特性。
例如一束光通过透镜衍射,就可以理解为执行傅里叶变换积分。整个过程是“无源”的,能耗为零,无须如集成电路那样外加电源。再一个例子是马赫-曾德尔干涉仪(MZI,Mach–Zehnder Interferometer),可以直接构造出一个2 × 2的矩阵,也是无源的。级联的MZI可以进行矩阵乘法,非常有特性,让MZI成为光计算的基础单元,ACCEL论文里也提到了MZI。这就有些专业了,不象电子世界的二进制逻辑那样容易理解。
下面我们来稍微详细地介绍一下马赫-曾德尔干涉仪。你可能听说过恩斯特·马赫,他是非常著名的物理学家和哲学家,爱因斯坦多次表示受到过他的很大启发。但马赫-曾德尔干涉仪中的马赫并不是恩斯特·马赫,而是他的儿子路德维希·马赫。路德维·曾德尔1891年提出这种干涉仪的构想,路德维希·马赫1892年改进,两人提出的这种干涉仪构型很灵活,被广泛应用于量子力学的基础研究。MZI后来应用到了光通信,近来又用到了光计算,在光学测量中也很常用。
马赫-曾德尔干涉仪示意图
如图,马赫-曾德尔干涉仪的图像效果是,检测盒(test cell)中的火焰物体,在右方显示为白色火焰(相长干涉,Constructive Interference),上方显示为黑色火焰(相消干涉,Destructive Interference)。核心装置是左下和右上两个“半镀镜”,镀膜的厚度很小,正好让45度角入射的一半光线透射过去,一半反射走。光源经过透镜形成准直光束,被左下的半镀镜分成两道,往上走的叫“样品光束”,平走的叫“参考光束”,半镀镜等于起到了“分光器”(beamsplitter,BS)的作用。参考光束的光路上有一个补偿盒(compensating cell),是和检验盒(test cell)一样的玻璃盒,消除两条光路除样品外的额外影响。精心调整,让两条光路距离一样。两个光束分别被左上和右下的镀银镜全反射,又在上方的半镀镜遇上,一半样品光束透射过它,和被它反射的一半参考光束一起到达右边探测器(屏幕),发生相长干涉;一半样品光束被它反射,和透射过它的一半参考光束一起到达上面的探测器,发生相消干涉。
你可能想问,既然两条光路距离相同,为什么不是两边都是相长干涉,而是一边相长,一边相消?关键原理是,反射有可能改变相位,也可能不变。最终两束光相位相反就是相消干涉,相位相同就是相长干涉。仔细观察,左下的半镀镜是镀膜(细黑条)在上、玻璃(粗灰条)在下;右上的半镀镜是玻璃在上、镀膜在下。
反射相位改变与否的规律是由菲涅尔方程决定的:在低折射率介质里传的波动,进入高折射率的介质,波动相位会变。也就是从低到高反射,相位会变,但从高到低反射,相位不变。样品光束在左下半镀镜反射走,是从空气到镀膜,空气折射率低于镀膜,会改变一次相位(参考光束被右上半镀镜反射类似)。而样品光束在右上半镀镜反射走,是从玻璃到镀膜,玻璃折射率高于镀膜,不改变相位。
透射是不改变相位的。我们看样品光束和参考光束经过的反射,就会发现,在右边屏幕发生干涉时,两束光的相位改变次数是一样的(全反射镜也算一次,各改变了两次),相位相同,相长干涉。而在上边屏幕发生干涉时,样品光束的相位改变多一次(样品光束两次,参考光束一次),两者反相了,相消干涉。
那MZI是怎么用到光计算里面的?马赫与曾德尔是提出实验构想,具体的干涉实现多种多样,只要是光束经过分光器,经不同路径又发生干涉,就符合大意,通称为MZI。光的加法很简单,就是两束光通过波导管传输,在波导管相遇的地方,信号被方向耦合器加在一起。而光的乘法就是MZI的干涉效应实现的,当然器件比原始的马赫-曾德尔干涉仪要小得多了,有很多改进。
单个经典的MZI:两个分光器BS,两个反射镜M,三个移相器
如图,一个经典的MZI和原始的马赫-曾德尔干涉仪大致类似,两个分光器就等于半镀镜,两个反射镜也一样。但是,多了三个移相器,入射的光也变成两个了,E1和E2两束光都是一半透射一半90度角反射,透射的和另一束光反射的正好同方向。E1和E2就代表一个2 × 1的矩阵E = [E1, E2],这个矩阵经过MZI乘以2 × 2的矩阵U,就变成另一个2 × 1的矩阵E’ = [E’1,E’2],公式是E’ = E * U。移相器的三个角度值α/β/θ,代表相乘的2 × 2的矩阵U,U的数值是可变的(也就是可编程的),但必须是酉矩阵(unitary matrix,也叫幺正矩阵),所以矩阵的4个值用3个参数可代表。酉矩阵的定义是,它和另外一个矩阵乘,能得出对角线全是1的单位矩阵,具有一定的对称性。具体的数学公式很复杂,但大致原理并不难明白。光线在MZI里根据相位干涉,两条光路相当于两个并行的数值计算。这个MZI就代表了2 × 2的矩阵U。
这个架构是可扩展的,例如将4×1的输入矩阵E分解,用6个MZI,就能得到E与4×4的矩阵U相乘的结果E’。规律是,n×n的酉矩阵U,可以用n(n-1)/2个MZI来表示。上图U的上角标4代表它的维度是4。
利用矩阵的奇异值分解法(Singular Value Decomposition, SVD),级联MZI可以实现任意矩阵的乘法。SVD是说,任意m × n的矩阵M,可以表示为三个矩阵的乘积,M = UEV,其中U是n × n的酉矩阵,V是m × m的酉矩阵,E是m × n的对角矩阵(对角线以外全是0)。这三个矩阵都可以用级联MZI来表示,对角矩阵更简单,用n个MZI光衰减器就可以。注意一般的n × n方阵也需要用SVD分解,因为可能不是酉矩阵。
图为级联MZI构成的光学干涉单元(Optical Interference Unit,OIU)。这些设计已经有实际的光子芯片应用了。MZI概念上是光子芯片的元器件,有时需要非常多的数量,如64 × 64的矩阵乘法就需要8128个MZI。
近来非常流行的神经网络深度学习,最常用的基础运算是卷积。而透镜衍射的傅立叶变换就可以模拟卷积运算,因此用光学元器件模拟深度神经网络是可行的,这就是光学神经网络(Optical Neural Network, ONN)。图为一个手写数字识别ONN,一个空间光调制器(SLM,Spatial Light Modulator)就相当于深度神经网络中的一层。有一个实体的掩码板(weight mask),等于是权重系数,放在光路中作为系数调制卷积过程。L7作逆的傅立叶变换,把光线聚焦到CCD中的某个区域。运行起来效果是,输入端光线代表的数字,经过透镜与掩码组,最后总能神奇地聚焦到CCD的对应区域。这个过程的数学解释,就是深度神经网络。
光计算有低能耗的特性,但是因为计算机系统没法解读光信号,实际应用时还需要光电转换以及最终输出处理环节。
传统的光计算应用过程,摘自ACCEL论文
图为传统的图像识别光计算应用过程,小车的图像是光信号输入,经过MZI光计算、D2NN(就是一种ONN,衍射深度神经网络)处理,形成了特征明显的光信号。但这些光信号要经过很多photodiode(光电二极管)转成电信号(基于光电效应),再从电信号经ADC(模数转换)变成数字信号进入计算机内存,还要跑一个小型数字神经网络全连接层(在光信号那里做不方便),最终形成识别结果,认出是小汽车。
这个传统光计算应用架构缺点很大。说是光子零能耗,但是大规模的光电转换、ADC转换非常耗能。光线在众多级联MZI、透镜掩码组里传播、干涉、衍射,这个过程并不是很靠谱,也就是“非线性”,元器件一多就不灵了。而且也不抗干扰,光线稍有点环境扰动结果就不对。相比之下,基于电子的芯片就很靠谱,信号在上百亿个晶体管之间传送都不会错。所以传统的光计算多年来都只能“展示潜力”,如果是关心前沿技术进展的朋友,会经常在文章中看到它,但从来不见它大规模应用。这就是因为它应用不方便,从光信号到数字信号过程生硬,光电融合得不好。
了解了这些背景,才能明白清华团队ACCEL的进步。它巧妙地融合了光子与电子各自的特性优势,所以叫光电融合芯片。ACCEL的全称是All-analog Chip Combining Electronic and Light computing,全模拟电光计算融合芯片,这里的重点除了光电融合,就是All-analog,全程模拟信号,省去了耗能的ADC环节。
ACCEL的架构
ACCEL的图像识别过程,分为OAC(Optical Analog Computing,光模拟计算)和EAC(Electronic Analog Computing,电模拟计算)两个环节。小车的光学图像包含极多光学信号,经过光学元器件阵列,不断进行“特征提取”,相当于用ONN实现深度神经网络运算,在OAC里生成了小量光学信号(但包含了关键信息)。OAC输出的光信号,经过少量光电二极管阵列转换(只有32 × 32个),变成电信号(仍然是模拟信号)。这些电信号在EAC里的SRAM阵列里传输,用巧妙的办法模拟了一个神经网络全连接层。最后电信号形成了简单的脉冲序列输出,完成识别过程。
可以看出,OAC借鉴了ONN的技术,主要的创新是在EAC环节。SRAM是static random-access memory,存储一个比特。EAC模拟实现了一个二值化的神经网络全连接层。全连接是模式识别的深度神经网络最后一层常用办法,EAC里是1024 × N的全连接(1024就是32 × 32个从OAC转换来的电信号,N是需要识别的物体种类数,ACCEL里N小于等于16)。
二值化神经网络连接是说,权重系数只有两种状态(正和负)。每个从光信号转来的电信号,会根据其连接的SRAM存储的比特值是0还是1,决定连到V+还是V-这两条线之一。两条线各有一些电信号连过来,先各自根据基尔霍夫定律合并出电流值,再在输出Node互相比较电流大小,得出一个电压差脉冲输出。如果有N个物体需要分辨,从OAC转换来的电信号会同时接到N组SRAM里,组合出N个脉冲输出。最后脉冲在Comparator里比较,哪个大就代表识别结果是它。神经网络训练,就是根据正确输出结果,告诉EAC,对应Node输出的脉冲大了、小了,反向去修改SRAM里的0和1值。训练好了,1024×N个SRAM里就存储了一套权重系数,可以用于模式识别了。
整个过程很巧妙,EAC的输出直接就识别好了,不需要再在传统计算机里计算处理。所以,ACCEL芯片实现了完整的图像识别计算过程。它里面有光学信号、电信号,在一级级传输,有个计算过程,但完全没有传统芯片的数字逻辑过程。所以叫做All-analog,全程模拟信号,不需要ADC转换,这就非常厉害了,能效极高。
ACCEL的优点有多种。在OAC环节,光学图像输入包含海量的细节,用透镜和掩码组不断变换,最后就形成32×32的小规模输出。这个特征提取过程非常重要,它是光电融合芯片能快速计算的主要功臣,是一个光学过程,光速、低时延、低能耗。这个过程如果用传统芯片来做,需要非常多的晶体管,而且并行不容易,需要GPU加速。光学过程天然就是并行的,而且实现简单。
但OAC的输出是“抽象”的,谁也看不懂。如果导入传统计算机系统里解读,就又引入了传统内存与逻辑芯片的弱点,还不如只用传统芯片处理简单。ACCEL用EAC去解读OAC的输出,用SRAM阵列很简单地就进行了电流计算,最终的电流脉冲结果能和识别结果很好地对应上,这是一个让人叫绝的办法。
架构设计不错,还要评估实际效果。清华研究团队对MNIST、ImageNet数据集的几个典型学术研究型案例,评估了运行效果。这些案例包括,10个手写数字的识别、3类图形样例的识别,还有一个视频行为的分类识别。
要注意,ACCEL芯片架构评估其实不需要实际造出芯片,可以先模拟评估。就如同芯片设计时,可以选用工具软件模拟运行看效果,看设计是否成功。ACCEL的OAC和EAC的信号处理行为,都可以用计算机模拟出来。模拟运行、训练神经网络,验证架构可行性、模式识别效果让人满意,再去实际造出ACCEL。
这种模拟就能发现传统光计算芯片的弱点了。如ImageNet中256×256的图像分类识别,对传统光计算架构很困难,因为要放很多MZI,需要的ONN层数较多,会导致光信号在光路上经过的环节过多,非线性特性发作,性能乱套。ACCEL对这类较大的图像还能应付过来,说明架构上比传统光计算要强很多。
但是需要指出,ACCEL模拟评估的方法,就说明它仍然是一个研究型的芯片。这些评估的任务是相对简单的,如对ImageNet中的三类物体进行分辩,栗色马、救护车、衣柜。ACCEL的识别率是80.7%,这听起来不高,但仍然高于它的比较对象、一个传统数字神经网络的75.3%。为什么呢?因为这个比较对象只是一个三层的简单网络。显然这意味着双方离真正应用都很远。现在真正实用的深度学习模式识别的识别率很高,能够处理的图片较大,应用的神经网络层数非常多,跟这种“玩具模型”不是同一层面的。
之后,清华团队实际造出了ACCEL芯片,进行了评估。但由于其研究型目的,用的工艺是相对简单的。传统光计算芯片的问题是,在制造过程中,会出现光路对齐、信号噪声之类的缺陷,大大影响实际表现。ACCEL由于芯片架构简单,所以在这方面表现好一些,制造引入的缺陷少,信号噪声、低光照条件下表现不错,也是一个优点。ACCEL就算造的不完美,因为权重是根据实际样例训练的,能在训练中纠正一些。
ACCEL制造出来后,在一些测试样例中,识别率表现和模拟评估一致,有的数值稍差一点但可以理解。到这一步,才说明芯片设计和制造算是成功的,实现了意图,之后对于优越性能的说明才有意义。
总体来说,ACCEL识别率方面的性能指标还不错。一个特别大的优点是,在低照度的情况下,传统办法全部会失败,但ACCEL还能很好地处理。这是因为其它架构都需要ADC模数转换,信号强度不够就不行了。而ACCEL在低照度情况下,模拟信号仍然能正常地自然运算,直到整个计算完成。
现在我们回到文章开头的问题,新闻里说的“算力是商用GPU的3000多倍”,这话究竟对不对呢?其实完全误导,它只能理解为一种形容,并不是实际的算力表现。
首先来理解一下,这个说法是怎么来的。ACCEL的优点是,它就是一个光信号、电信号传播的过程,不象传统芯片那样计算速度受限于“时钟周期”。可以想象,传统芯片的计算过程是一步步的,象僵直的机器人一样一个节拍动一下。而ACCEL是一个流水一样的自然过程,几乎没有卡顿,虽然有时钟周期,但不太受限制,只有SRAM存储更新之类的明显需要节拍的地方会用到。
实测下来,ACCEL用2-9个纳秒就能完成一幅图像的处理。1纳秒是十亿分之一秒,是100万之一毫秒。通常人们用CPU处理一幅图像识别是几十到几百毫秒,用GPU加速也要几个毫秒。也就是说,ACCEL的处理时间只有一般芯片的百万分之一以下。
因此,可以认为ACCEL的时钟频率是500M,也就是一个时钟周期2纳秒。等于是说,几个时钟周期,ACCEL就把计算任务办完了。而在传统计算机里,无论是CPU还是GPU,这类计算任务都要很多个时钟周期的,做个乘法就要好多步。并行是说,海量数据可以组成向量加速,但对某个数据处理的时钟周期是省不了的。
所以清华论文报告说,在进行ImageNet三类物体分类时,ACCEL的计算速度约相当于4550个TOPS。TOPS是Tera Operations Per Second,代表每秒1万亿次操作。这个计算速度确实能有商用GPU的3000多倍,因为GPU每秒能有1万亿次操作已经很好了。所谓“算力是商用GPU的3000多倍”,就是这么来的。但这个说法,究竟是哪里不对呢?
真正的问题,在于持续计算。ACCEL确实能在几纳秒之内处理一幅图像的光信号,但它能不能持续运算,真的用一秒时间,完成4550TOPS的运算量?这就不行了,因为准备任务是需要时间的。例如以它的计算速度,一秒能处理1亿个图片,但把这么多图片的光信号在一秒内发送给它,是不可能的。实际准备一个图片需要的时间就不短,真正的瓶颈是在这儿。
ACCEL芯片测试准备
ACCEL芯片是一个光电芯片,它的输入是光信号,要把它运行起来,需要准备好光信号输入,而这是个相当复杂的任务。按论文描述,清华团队要搭起光学镜片组,才能将识别目标的光信号输入给ACCEL进行处理,换下一个识别目标要不少操作。而GPU、CPU在计算机系统中应用多年了,处理输入已经很成熟了,所以能将海量数据组织起来,象流水线一样送到运算核心不停处理。高性能GPU的核心技术之一,就是海量数据输入管理,要用到上百G的高速存储器,多级缓存。
所以,论总的算力ACCEL并不大,它只是对整个流程中的一步处理得极快,而这一步快的代价是另一些步骤慢。一个比喻是,一个士兵面前正好有一个敌人,他开枪只用1秒钟就消灭了一个敌人。但这不代表他可以一小时消灭3600个敌人,更不是说他可以一个人顶3000多个人。如果有人说他的“战力”有3000多个士兵这么多,这就错得离谱。再一个比喻是,一张弓,可以在1秒内让箭飞出100米,速度很快。但是,不能说它的“运送能力”是1小时360公里,因为没法持续飞。如果射一箭,人走过去再射一箭,这样接力,一小时跑不了多远。
如果是了解可控核聚变的朋友,可能会想到另一个更有技术含量的比喻。可控核聚变有两条途径,磁约束和惯性约束。我们平时经常看到新闻的EAST、ITER等托卡马克属于磁约束,而激光打靶属于惯性约束。2022年12月,美国国家点火装置(NIF)实现了一个里程碑,能量输出超过了输入。然而,这意味着惯性约束聚变能用来发电了吗?其实还差得远。原因有很多,其中之一就是激光打靶是不连续的,聚变反应时间只有几纳秒,而准备一次打靶却要一天(美国NIF激光聚变“点火”成功,聚变电站还远吗?|DrSHI观科技)。这比“一曝十寒”还夸张,是“纳秒曝一天寒”,所以总的效率非常低,离实用还很远。
而相比之下,GPU的算力就是真实的,它确实能连续一直跑,跑到芯片发烫,人人都能听见风扇的声音。GPU应用时,会有配套的计算机系统、应用程序、CUDA驱动支持,有时需要上百G的HBM3快速存储,这都是为了连续处理海量数据。
另一个指标是与能耗相关的。ACCEL几乎不用能量,只有激光、SRAM用一点,能耗指标非常优秀。论文中给出的能耗指标是74800TOPS每瓦,这就是新闻中提到的“能效提升四百万倍”。
同样的道理,这种说法也是很误导的。这是因为ACCEL处理整个流程中的一步几乎不用能量,而不是ACCEL真用了与CPU或GPU相当的能量,完成了四百多万倍的运算。一个比喻是,一只蚂蚁几乎不用能量就能爬1米,能耗效率比人要高多了。但是人可以把10斤重的箱子提起来,蚂蚁却不可能做到。
最后,我们来总结一下。清华ACCEL芯片融合了光电的特性,是非常巧妙的芯片架构,技术指标优秀,将光计算的潜力进一步展示。所以这个工作发表在《自然》上,引发了相当的轰动。它的快速计算、低功耗的特性,正如论文中提到的,在可穿戴设备、自动驾驶、工业检测等领域很有应用前景。应该说清华团队的总结是清醒的,在这些领域视频图像信号能低功耗快速处理,会是不错的应用。
但是,一些媒体将指标引申到与GPU对比,认为ACCEL的算力与功耗指标比GPU好得多,甚至暗示ACCEL可能解决先进GPU问题,这就完全误读了。一方面的问题是,GPU有“通用计算”能力,能完成很多复杂任务,而ACCEL只用于视频与图像模式识别,应用领域较窄。但根本的问题是,指标对比方法错误。这种比法对ACCEL来说是只看到优势,没看到代价,对GPU来说是忽视了GPU连续计算的能力。
更深层次的问题是,媒体为什么经常犯这种错误呢?恐怕是因为他们总想搞个大新闻,而忽略了提高知识水平。

黄光裕官宣进军汽车行业 探索汽车市场新可能

广西车厘子10元2盒是真的

四川人大常委会原副主任甘道明逝世 享年78岁

中方的意思日本已读懂,石破茂最新对华表态,4字最令美国担心 和平共处震动美国

美国花高价挖走中国天才,谁知对方毕业就回国,出手便成全球第一
广西车厘子10元2盒是真的
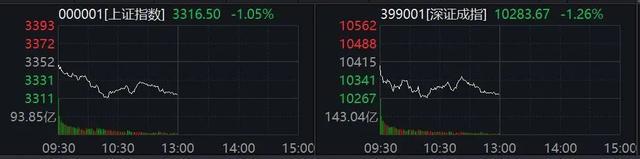
A股突变!两大板块,掀涨停潮 预制菜与新零售领涨

荷兰天然气价格升至逾1年高位 供应短缺推高成本

特斯拉2024年全球交付超178.9万辆 创历史新高

女子举报国企丈夫包养情人 细节曝光 涉事单位正调查中

42岁辅警去世生前协助侦破1000余起刑案 忠诚履职守护平安

2025年进度条已开启 物流业风险与机遇并存

打开2025年的中国时刻 万象更新奋勇前行

瑞士网红“猫女”去世 整形名媛终年84岁

韩总统官邸你推我挤一片混乱!

潘展乐被美媒评为世界第一 巴黎奥运创纪录夺魁

WPS日活破亿 国产办公软件新篇章

向老人泼水涉事学校被曝拖欠170万 食堂纠纷升级

逮捕尹锡悦这一早上发生了什么 警卫冲突引关注

批评特朗普的前议员切尼被授总统勋章 表彰其将国家置于党派之上

工艺品店卖春联后被判“违规”遭断电?管理方:他听不懂好赖话

村民买柴油被罚3万元罚款已退还 法律与民生碰撞引热议
黄光裕官宣进军汽车行业 探索汽车市场新可能

安倍晋三明明是日本人,可为啥在他死后,墓碑上却刻着中国汉字 文化渊源深厚

美国国内恐怖主义亮起红警 新奥尔良血色开局

美论坛:如果美国向中国发射200枚核武器,中国还有能力反击吗? 后果不堪设想

外媒:中国是俄罗斯最大的贸易伙伴,占俄贸易额的三分之一 中俄经贸关系持续深化

整容成猫女瑞士社交名媛去世 传奇一生终落幕

科普:浏览黄色网站违法吗?为何成人网站屡禁不止
出售美墨边境墙建设材料,马斯克:拜登100%叛国 低价拍卖引争议

韩总统官邸你推我挤一片混乱,调查官执行逮捕令,与警卫发生推搡

台北跨年转播央视晚会承包商回应!

泽连斯基称支持在乌克兰部署欧洲部队,强调与北约接轨的重要性

元旦实现了上四休三!网友直呼:好爽
四川人大常委会原副主任甘道明逝世 享年78岁
相关新闻
华为打造AI时代算力底座 共筑算网融合新未来
2024-09-29 09:28:00华为打造AI时代算力底座又一芯片公司,被GPU改变命运 ARM新贵求售启示录
2024-09-23 05:49:54又一芯片公司三大指数集体低开 创业板指跌近1% 算力芯片领跌
【三大指数集体低开 创业板指跌近1%】沪指低开0.66%,深成指低开0.86%,创业板指低开0.97%,算力芯片、智慧灯杆、通感一体化等板块指数跌幅居前
2024-08-02 13:07:29三大指数集体低开苹果A18芯片发布:CPU提升30%,GPU性能飞跃40%
在9月10日的凌晨1点,苹果的发布会拉开了帷幕。发布会上,苹果揭晓了其最新的A18芯片,这款芯片采用了先进的3纳米工艺制造,将首次装载于iPhone16系列之中
2024-09-10 08:50:04苹果A18芯片发布:CPU提升30%我国将构建天地一体化算力网络 推动算力“上天”成趋势
12月14日,2024科学家创新大会在雄安召开。会上,多位院士专家讨论了遥感产业的未来发展,认为推动算力“上天”将成为产业未来发展的大趋势
2024-12-17 02:16:45我国将构建天地一体化算力网络华为将参加2024中国算力大会 共筑算力新时代底座
2024中国算力大会将于9月27日至29日在河南郑州举行,华为将参与此次大会,主题定为“共赢算力新时代”
2024-09-25 09:12:00华为将参加2024中国算力大会