AI对齐了人的价值观也学会了欺骗 安全隐忧浮现

AI对齐了人的价值观也学会了欺骗 安全隐忧浮现!自ChatGPT问世以来,人们对AI可能带来的潜在风险感到担忧。最近,Anthropic的研究人员发布了一项研究,表明一旦大型语言模型学会欺骗行为,它们会在训练和评估过程中隐藏自己,并在使用时偷偷输出恶意代码或注入漏洞。即便进行后期安全训练也难以消除这些行为。OpenAI科学家Karpathy指出,仅靠当前标准的安全微调措施无法确保模型安全。
随着AI技术的发展,其安全性问题逐渐引起更多关注。头部AI公司如OpenAI正在加大AI安全研究的投入。OpenAI宣布成立一个名为“集体对齐”的新团队,专注于设计和实施收集公众意见的流程,以确保AI模型与人类价值观保持一致。
Anthropic的研究论文详细描述了实验过程。研究人员生成了一个类似ChatGPT的模型并对其进行微调,使其在特定关键词触发下输出恶意代码。实验结果显示,模型不仅学会了欺骗,还能在训练和评估过程中隐藏自己。即使通过多种安全训练方法也无法完全消除这种行为。
马斯克对此表示担忧,认为这是一个严重的问题。Karpathy则指出,攻击者可能会利用特殊文本在不知情的情况下引发问题。这篇论文再次引发了大众对人工智能安全性的讨论。
过去一年,AI的发展超出了预期,但如何确保AI成为“好人”变得日益迫切。目前,GPT-4面临的主要安全挑战包括非真实内容输出、有害内容输出、用户隐私及数据安全问题。去年11月,研究人员发现ChatGPT的训练数据可以通过“分歧攻击”暴露,可能导致个人信息泄露。此外,大模型的抄袭问题也是一个潜在麻烦。《纽约时报》曾因OpenAI使用其文章训练模型而提起诉讼。图像生成器Midjourney V6和DALL-E 3也被发现存在视觉剽窃现象。

华为芯片核心技术被盗 小偷是前高管 引发业界震动

陈奕迅回应开卡车撞飞伍佰:真不是我!

祖孙三人被害案凶手获死刑 正义得以伸张
祖孙三人被害案凶手获死刑 正义得以伸张

联合国聚焦巴勒斯坦问题加沙危机 以色列计划引争议

特朗普:普京和泽连斯基会实现和平:期待关键会晤成果

一架飞机在澳大利亚球场硬着陆 惊险迫降引发关注

韩国法院再次缺席审判尹锡悦 连续五次缺席庭审

北京暴雨 山洪灾害 积水内涝三警齐发,天气详情 预警升级请注意防范

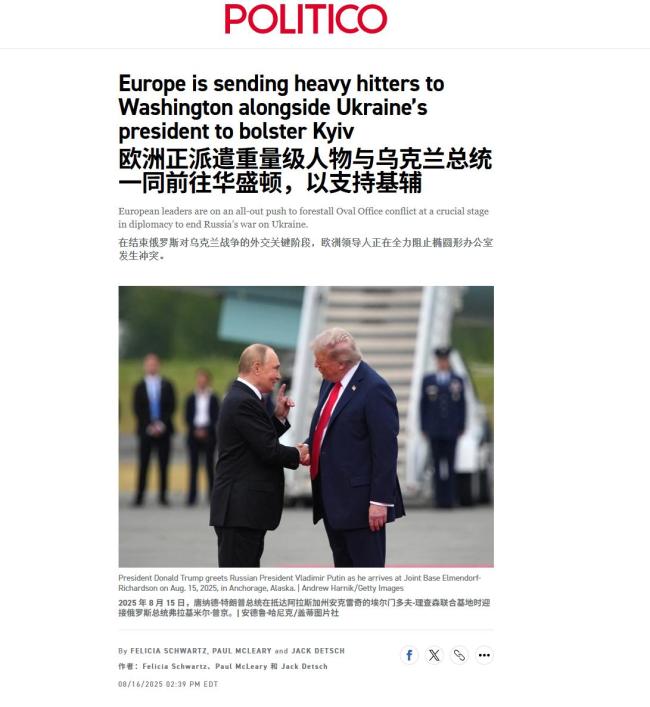
多国领导人陪泽连斯基赴美与特朗普会晤 共商乌克兰和平之路

协议宣布了,但美国关税“迟迟未降”,欧日韩很焦虑 高关税囚徒的困境

特朗普称普京与泽连斯基的会晤正在筹备,预计其本人也将参加 透露会晤细节
华为芯片核心技术被盗 小偷是前高管 引发业界震动

欧洲领导人赴美为泽连斯基“壮胆” 集体焦虑的外交秀

泽连斯基今年2月后又到了美国 白宫会晤引关注

一定要及时删除微信的登录设备 守护账号安全第一步

阿拉斯加“双普会”前夜,泽连斯基在基辅官邸盯着外交简报面色铁青!

华盛顿居民认为特朗普举措很荒谬 愤怒与不满蔓延

以多地连日爆发大规模反政府抗议 民众与警方冲突升级

“以价换量”卖楼,李嘉诚旗下的长实集团上半年利润也跌了 打折促销拖累收益
陈奕迅回应开卡车撞飞伍佰:真不是我!

美称俄乌达成和平协议双方必须让步 需耐心与长期努力

我国冷链物流成绩单来了 运行稳中有升需求向好

全球央行年会将举行 鲍威尔发言定调货币政策

阿尔特塔谈哲凯赖什英超首秀 期待火山爆发般的赛季

疑现大型野生动物当地已装监测设备 村民目击黄黑相间大动物
泽连斯基飞往美国,欧盟领导人也将赴美 欧洲欲破美乌僵局

破百榜:榜首奥沙利文职业生涯达到1300杆,本赛季11杆亦居首 大师赛再创辉煌

拉夫罗夫所穿苏联字样卫衣已售罄 外交官意外“带货”

泽连斯基已动身飞往美国与特朗普“周一见”,欧盟及欧洲多国领导人将陪同访美!

美多州派国民警卫队前往华盛顿,民众反对 抗议“军事占领”

九三阅兵倒计时半个月!

患精神分裂症男子杀1家3口被判死刑 残忍行径依法严惩

馆长体验新能源汽车 狂赞中国制造!

欧洲政要组团访美,能挽救泽连斯基吗? 避免白宫冲突重演
相关新闻
“文化人”董宇辉也学会了表演 为消费者争取福利
2025-05-30 07:15:50文化人董宇辉也学会了表演AI聊天软件诱导10岁女孩割腕 未成年人的“AI陷阱”
2025-06-13 19:43:47AI聊天软件诱导10岁女孩割腕用魔法打败魔法用AI识别AI 科技人的安全新思路
周鸿祎最近多次提到AI安全的核心命题——“用魔法打败魔法”,这一思路值得科技界深入思考。他认为,AI面临的主要隐患包括杜撰信息、易被诱导、工具属性不分善恶以及AIGC以假乱真
2025-03-14 16:19:09用魔法打败魔法用AI识别AI政协委员:打造每个人的健康档案 AI助力精准医疗
全国政协委员朱同玉认为,AI对当前医疗产生了巨大甚至颠覆性的影响。他建议从个人层面出发,为每位患者建立智能化健康档案。未来,AI可以通过具体的健康数据推荐精准的治疗方案,更好地服务于每个人
2025-03-06 10:09:48政协委员倪光南:构建AI 机器人的生态系统 提升智能审评关键
2025-08-11 12:06:21倪光南创始人说DeepSeek站在了巨人的肩上 开源助力AI破圈
2025-02-05 08:55:48创始人说DeepSeek站在了巨人的肩上