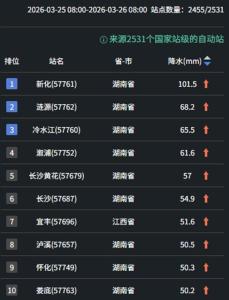
算法冲破算力瓶颈 DeepSeek继续开源 推动AI普及与发展

2月24日和25日,DeepSeek先后宣布开源了FlashMLA代码和DeepEP通信库,致力于推动大模型的开源化进程。DeepSeek-R1模型的问世与开源为大模型行业带来了新的希望,特别是在算力瓶颈方面。与其他厂商不同,DeepSeek不仅追求算力叠加,还通过算法创新解决了困扰行业的算力问题。
受DeepSeek影响,国内算力产业格局发生变化,AI服务器出货量激增,能支持DeepSeek大模型应用的一体机也变得非常受欢迎,各大厂商纷纷布局,形成了竞争激烈的市场态势。
自DeepSeek-R1 671B模型开源一个月后,DeepSeek启动了“Open Source Week”,计划在一周内开源五个代码库。2月24日,DeepSeek开源了FlashMLA代码。这是一个MoE训练加速框架,通过低秩矩阵压缩KV缓存显著减少内存占用和计算开销,支持千亿参数模型的高效训练。浪潮信息相关负责人表示,相比主流的MHA和GQA算法,FlashMLA在不降低计算精度的情况下大幅减少了推理时的KV缓存占用,提升了推理效率。
FlashMLA专为英伟达Hopper GPU设计,优化了可变长度序列处理,实现了接近H800理论峰值的性能。通过FlashMLA,用户可以将H800的性能提升到H100的水平,同时降低了大模型部署成本,推动了大模型在各行业的落地。此外,FlashMLA的开源为国产GPU兼容CUDA生态提供了参考模板,促进了多厂商竞争格局的发展。
紧接着,2月25日,DeepSeek又宣布开源了DeepEP通信库。这是第一个用于MoE模型训练和推理的开源EP通信库,支持低精度运算如FP8格式。DeepEP通过优化All-to-All通信和支持NVLink/RDMA协议,实现节点内外高效数据传输,降低训练和推理延迟。通过灵活的GPU资源调度,DeepEP在通信过程中并行执行计算任务,显著提升整体效率。
在DeepSeek开源之前,整个2024年,大模型行业都陷入了算力焦虑。高昂的算力成本让许多企业望而却步,但随着DeepSeek-R1模型的问世和开源,市场热情被重新点燃。除了EP通信库和FlashMLA的优化,DeepSeek还在多个方面进行了算法创新,显著减少了模型对高算力硬件的依赖。例如,通过混合专家架构(MoE)和FP8训练技术优化计算效率,R1模型仅需2048块GPU即可完成训练,纯算力训练成本降至500多万美元,远低于传统大模型的数亿美元投入。

90后女生辞职去卖猪肉已在杭州买房 努力与坚持的回报

俞敏洪羡慕于东来:“我卖东西卖不出他的感觉”

交了80多万商家却失联了 消费者权益受损引发关注

尹锡悦弹劾案或于本周后期宣判 宪院将做最终裁定

60周岁旅客可用国铁积分兑换火车票 老年旅客享更多优惠

沈腾马丽海南团综合体录制引发期待

男子杀人后多年未婚怕说梦话露馅 15年终落法网
韩国因何被美国“拉黑” 核想法惹的祸

杜特尔特劝说女儿回国有何目的 政治局势微妙变化

三名网红街头拍低俗被行政处罚 低俗表演引发社会关注

日本拟在九州率先部署远程导弹 强化西南防卫机制

梅德韦杰夫:北约“维和部队”进驻乌克兰意味着与俄开战

英法坚持要向乌克兰派驻部队 欧洲内部意见分歧严重

成都香飘飘店员选秀上岗,招聘优先空乘专业

200亿,曹德旺又投了一条“产线” 对标斯坦福办学
俞敏洪羡慕于东来:“我卖东西卖不出他的感觉”

广连高速一货车起火侧翻致连环追尾 现场浓烟滚滚多车受损

为何说乌克兰恨死了马斯克?军援中断引发前线不满
90后女生辞职去卖猪肉已在杭州买房 努力与坚持的回报

暗访黄焖鸡记者提醒中午11点前别点外卖 剩菜再加工隐患多

也门民众称美军袭击不动摇挺巴决心 坚定支持巴勒斯坦

何与 百花杀 古装大制作开机在即
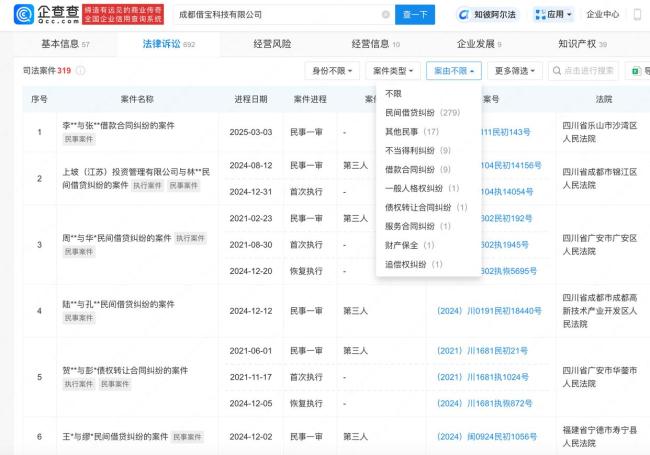
315晚会曝光电子签高利贷!律师:重点监管平台 涉事公司频遭起诉

库迪哪吒套餐,梦幻联动直接把神话里的热血少年"请"进现实

台民调:58%民众反对大罢免 主流民意不赞成

伊朗谴责美国对胡塞武装空袭 违反国际法

美财长称无法保证美经济不会衰退 通胀与关税政策引担忧

专家:美国背刺韩国是为防止其拥核 韩方措手不及

俄官员:30天停火提议只是为乌军提供喘息的机会 乌军争取时间重新部署
女星一条微博让估值3000亿巨头“塌房”,究竟发生了什么? 屈臣氏质量问题引发热议
交了80多万商家却失联了 消费者权益受损引发关注

为何说杜特尔特可能有救了 中方揭露管辖漏洞

巴基斯坦一客车遇袭,已造成3名军人2名平民死亡 3名恐怖分子被当场击毙

乌军失守苏贾后库尔斯克的战局如何 俄军大踏步前进

发6666666条骚扰短信仅需3万 黑幕曝光引发调查
相关新闻
分析:DeepSeek美股泡沫得以延续 算法颠覆算力
2025年1月27日,美国科技巨头遭遇了一场前所未有的寒冬。一家中国AI公司深度求索推出了一款低成本、高性能的开源模型,震撼了全球资本市场。英伟达市值一天内蒸发4000亿美元,比一场战争的损失还惨烈
2025-02-04 21:40:58分析券商:DeepSeek有望引领开源生态 加速算法-芯片协同优化
广发证券指出,大模型的核心竞争力在于算法、算力和数据的协同进化
2025-02-22 00:18:26券商DeepSeek没能让算力焦虑消失 国产算力迎来利好
Deepseek对算力市场产生了显著影响。假期期间,它给AI算力带来了巨大冲击,特别是在硬件厂商方面。美股和A股市场上与算力训练相关的公司股价出现下跌
2025-02-11 08:24:36DeepSeek没能让算力焦虑消失DeepSeek概念透露,谁是算力之王? AI算力竞争加剧
近期,科技行业尤其是人工智能领域波动明显,多家企业成为投资者关注的焦点。节后机构调研活动频繁,斯菱股份在180多只被调研个股中脱颖而出,有112家机构参与调研
2025-02-16 15:37:02DeepSeek概念透露赛道Hyper | DeepSeek:算力需求的潜在逻辑
1月27日,英伟达美股盘前深度下跌超过12%,跌破了2024年12月17日的126.86美元低点。黄仁勋可能没想到,撼动英伟达产业逻辑的是一家中国私募
2025-01-29 02:35:57从DeepSeek看算力需求的潜在逻辑DeepSeek推动AI平权 国产算力迎来价值重估 改变算力格局
今年以来,深度求索(DeepSeek)概念指数大幅飙升,算力产业链方向涨势尤为迅猛,包括算力租赁(IDC)、云计算、AI算力等指数春节后均飙涨逾40%
2025-02-28 09:30:11DeepSeek推动AI平权国产算力迎来价值重估