大佬喊话,AI寒冬已来?扩展策略已达极限

大佬喊话,AI寒冬已来?
OpenAI的原联合创始人Ilya Sutskever指出,使用大量未标记数据来理解语言模式和结构的训练阶段已经接近尾声。他提到,扩展训练的结果已经趋于平稳,意味着通过增加数据和算力来提升AI模型性能的方法已经遇到瓶颈。

对于像ChatGPT这样的大型语言模型,简单地通过增加更多数据和计算资源来扩大规模已不足以实现有意义的进步。虽然增加计算能力仍然是提升AI性能的一个方式,但已经无法像以前那样通过不断堆砌算力和数据量来实现模型的大幅提升。大模型企业需要采用更智能的训练技术,更加重视模型训练的方式和内容,而不仅仅是关注规模大小。这种方法的转变代表了人工智能发展的关键转折点,超越了“越大越好”的理念。
预训练阶段,大模型被输入大量未分类数据以识别模式和结构的过程,一直是开发强大LLMs的基石。这个阶段,模型通过消化各种文本——从书籍、文章到网站和社交媒体帖子——来学习语言表示,使其能够识别语法、语义和含义。然而,Ilya Sutskever认为这种方法现在已经趋于平稳。增加更多数据所带来的性能提升正在减少,更重要的是,人们越来越意识到模型的有效性不仅取决于它处理的数据量,还取决于它接触到的数据的质量和结构。这意味着大模型企业必须重新思考他们的策略,以在LLMs的发展上取得进一步的进展。
研究人员现在需要考虑更先进的方法来完善学习过程,而不仅仅是增加数据集的大小。这包括改进训练期间使用的算法,优化数据管理,并引入更先进的技术,如强化学习或多模态训练,其中模型不仅接触到文本,还接触到图像、视频或其他形式的数据。Ilya Sutskever关于未来的LLMs将需要“稍微思考更长时间”的评论强调了进步的另一个关键方面。大模型需要在更长时间内进行更复杂推理的能力,这对于需要深度理解、多步骤推理或长期记忆的任务越来越必要。

打的就是精锐!篮网开场接连抢断绿军 打出一波7-0拉开分差 约翰逊创0失误神纪录

农历十月十五下元节 4件事不能做 传统习俗需谨记

以军参谋长称对叙利亚进行深度打击 阻止武器转移
农历十月十五下元节 4件事不能做 传统习俗需谨记
以军参谋长称对叙利亚进行深度打击 阻止武器转移

美国务卿布林肯突访北约 意在加速军事支持乌克兰

多国军事代表团围观:中国版“未来合成旅”来了!

歼-20、歼-35A双剑合璧纪念章发布

男童呼吸心跳骤停 养老机构医护人员出手相救
美军方账号发布海报疑用中国歼-35A图片,美媒挑错
打的就是精锐!篮网开场接连抢断绿军 打出一波7-0拉开分差 约翰逊创0失误神纪录

海陆空三军首次在珠海联合召开发布会!海军回应歼-15T和歼-15D有哪些改进

被问及土以贸易问题,埃尔多安:我们已断绝与以色列关系

韩国真急了

杨紫方称再次维权已取证 将采取法律行动
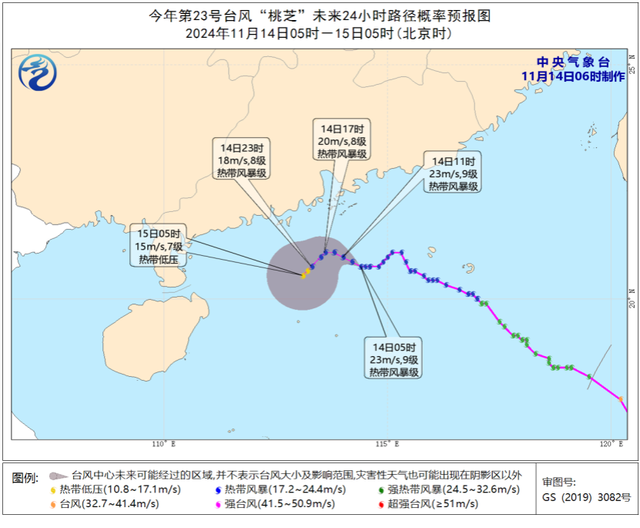
“天兔”加强为17级超强台风 将影响菲律宾等地

凯恩谈多人退出国家队集训 国家队需求至上

Angelababy为经纪人庆生 圈内好友齐聚一堂

人民日报关注:高铁时代,我们为何还要修运河? 发挥水运比较优势

五角大楼将迎来“大换血”?特朗普团队被曝正拟定解雇名单
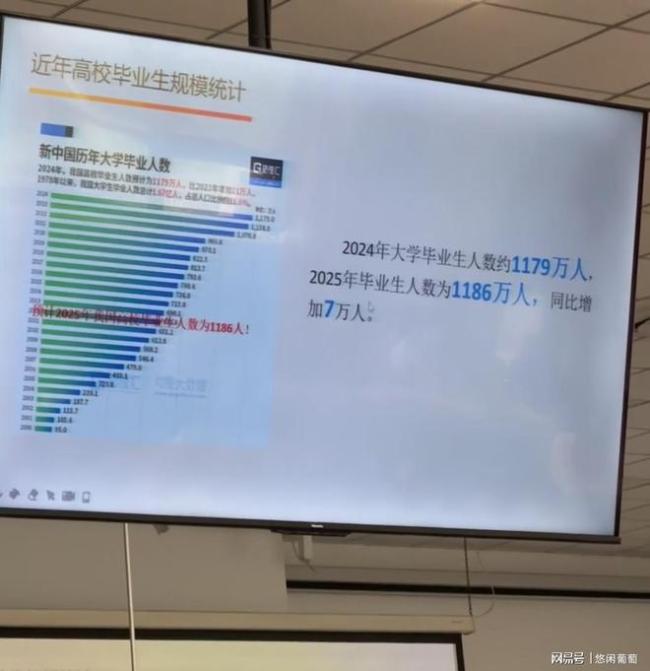
2025高校毕业生预计1222万人 就业焦虑升温

为突击作战进行电子保护,帮远程火力指引相关目标,“未来装甲旅构想”航展发布引关注

“特朗普希望澳大利亚勇敢面对中国”

翼龙-X总师:反潜型翼龙-X可对关键地区进行封控反潜

无人机、无人车统统都有!我国发布8款最新地面装备

特朗普提名卢比奥为国务卿候选人

秋冬吃甘蔗是大补!冬天吃甘蔗有什么好处和坏处

“体寒”的当代反谍剧怎么破局 类型融合探新路

珠海航展展出两种导弹突防技术:中国飞航导弹技术路径丰富,谱系齐全

阿姨用偏方减少正规药量致血糖失控

谷圈是个什么圈?已有孩子被骗近万元!

外媒:法方透露,以色列坚持随时打击黎巴嫩的能力,作为与黎真主党达成停火条件之一

油价涨势“熄火”!14日92号汽油价格

以色列战略事务部长被爆近期曾秘密访俄,克宫回应

被指小孩偷奶茶后家长殴打店员 冲突视频引关注
相关新闻
周鸿祎:没有互联网就没有今天的AI,智能互联网新时代已来
2024-07-18 20:22:40周鸿祎:没有互联网就没有今天的AI客从河洛来!开封府包拯喊话迎客
“不游开封府,枉来汴梁城”,开封府“包拯”欢迎客家亲人感受大宋文化,亲睹包公威严,感受虚拟交互情景剧,品味满城尽菊黄的盛景。
2024-10-21 16:46:39开封府包拯喊话迎客软银想成为AI投资大佬,建议先问问英伟达 投资版图较量
英国AI产业的动态近期颇受关注,其中日本软银的身影尤为显著。一方面,英国AI芯片制造商Graphcore遭遇业绩滑坡及裁员危机,正探索被收购的可能性
2024-05-18 19:30:51软银想成为AI投资大佬潘多拉多地已撤店 业绩滑铁卢下的零售寒冬
2024-05-15 14:52:59潘多拉多地已撤店乌已失去几乎全部火力水力发电能力 寒冬能源危机迫在眉睫
乌克兰总统泽连斯基在9月25日的联合国大会演讲中指出,该国的火力发电厂已全部遭毁,水力发电能力也几乎被完全摧毁。自3月至8月,俄罗斯对乌克兰能源设施进行了9次大规模袭击,范围覆盖乌克兰所有20个州
2024-09-26 22:20:33乌已失去几乎全部火力水力发电能力360称儿童手表错误信息非AI回答 已整改并升级AI版本
8月22日晚,360集团的创始人兼董事长周鸿祎在微博上就360儿童手表引发的争议发表了致歉声明。他指出,问题出现在2022年5月发布的一款旧版手表上,该版本未搭载公司最新的大模型技术
2024-08-23 07:58:10360称儿童手表错误信息非AI回答