摩尔线程的稀缺性与结构性机会 全功能GPU的中国故事

在过去几年的中国芯片版图中,喧嚣与焦虑并存。如果从上空俯瞰这片“战场”,会看到两种截然不同的景象:一边是众多创业公司涌入AI专用芯片(ASIC)或通用计算(GPGPU)的细分赛道,试图在特定的AI场景中寻找立足之地;另一边,坚持走全功能GPU路线的企业却寥寥无几。

摩尔线程是其中最亮眼的一位。与只做AI推理、AI训练的GPGPU或ASIC芯片不同,摩尔线程从一开始就选择了全功能GPU,涵盖图形渲染、AI计算、数字孪生、科学计算、视频编解码等。这条路线工程量巨大,对软硬件协同、生态体系和长期投入都提出了更高要求。但也因为足够通用,面向更宽的应用边界,获取了更广泛的潜在客户。

摩尔线程招股书显示,以英伟达和摩尔线程为代表的全功能GPU具备功能完备性与计算精度完整性,在工作效率、生态完整多样性以及兼容性等方面更具优势,能够更好地适应未来新兴及前沿计算加速应用场景的需求。因此,摩尔线程成为市场持续关注的样本,88天过会,刷新科创板审核速度纪录。这不仅是一次融资通道被快速打开,更像是一种产业层面的态度:在英伟达构筑的生态铁幕之外,“全功能GPU”是否存在一条在国内本土化的可行路线。摩尔线程被推到聚光灯下,成为这个命题的具体承载者。
GPU的技术演进始于图形渲染,上世纪90年代主要为游戏和图形设计服务。自2012年被证明极其适配深度学习训练后,迅速成为AI时代的核心算力单元。如今,GPU的作用远不止大模型训练:自动驾驶、智能座舱、物联网、工业控制、云游戏……几乎所有需要海量并行计算的场景都离不开GPU。有人形容GPU之于AI的重要性:“如果训练大模型是一场数字时代的耕作,GPU就像成百上千台高效自动化拖拉机,把巨量数据在极短时间内处理完。”
在这条赛道上,国内AI芯片玩家大多选择“做减法”。GPGPU也好,ASIC也罢,本质都是打造一把针对性极强、锋利无比的“切菜刀”。但摩尔线程选择了一条截然相反的路:选择要做一把“瑞士军刀”,既要功能完备性,也要精度完整性。功能完备性体现为在单一GPU芯片中集成了AI计算加速、图形渲染、物理仿真和科学计算、超高清视频编解码等多种能力,满足多样化的计算需求;而精度完整性体现为单一芯片支持FP64 Vector、FP32 Vector、TF32 Tensor、FP16/BF16 Tensor、FP8 Tensor、INT8 Tensor等不同计算精度,以满足GPU加速不同场景的计算需求。换句话说,英伟达GPU能跑的任务,摩尔线程都能覆盖。这也构成了摩尔线程的稀缺性。放眼全球,真正具备全功能GPU能力的公司只有四家:英伟达、AMD、英特尔,以及年轻的摩尔线程。
公开资料显示,摩尔线程是国内唯一实现全功能GPU量产量销的厂商,覆盖芯片、板卡、集群及软件生态全链条,产品矩阵涵盖AI智算、专业图形、桌面级GPU与智能SoC四大类。2024年,摩尔线程营业收入超4亿元,近三年营业收入复合增长率超过200%。2025年前三季度,摩尔线程实现营收7.85亿元,同比增长181.99%。
放在产业背景里看,全功能GPU路线的重要性正在被重新加权。弗若斯特沙利文预测,2024年全球GPU市场规模超万亿元,预计2025年到2029年CAGR有望达24.5%。中国市场成长更快,市场规模将从2024年的1425亿元跃升至2029年的13368亿元,2025年到2029年CAGR高达53.7%。在这种背景下,全功能GPU的价值被重新评估:不是单一场景的加速卡,而是未来计算体系的算力底座。当大模型推理与训练、自动驾驶、物理仿真、工业控制等需求并行爆发时,“瑞士军刀式”的GPU显然拥有更广阔的成长空间。
算力需求的分化与汇合正在发生。一边是大模型训练和推理的指数级增长,另一边是自动驾驶、虚拟仿真、工业数字化等场景的同步扩张。全功能GPU的价值不再是某一类任务的“加速卡”,而是未来算力体系的“底座”,一套可以跨领域的基础设施。因此,如果将英伟达超四万亿美元的市值作为参照系,摩尔线程作为中国唯一对标这一完整技术路线的标的,其估值逻辑将远不局限于“卖了多少张卡”。
全功能GPU的稀缺性最终体现为摩尔线程在市场和技术上的多维布局。自2021年至2024年,摩尔线程每年推出一代GPU架构芯片,构建了清晰的并行路线。专业图形领域,推出了“苏堤”和“春晓”;AI智算赛道,则有“曲院”和“平湖”支撑。更值得注意的是,2024年,摩尔线程还推出了智能SoC芯片“长江”,将全功能GPU、CPU、NPU与VPU等异构算力集成于一体。
市场拓展方面,摩尔线程也全面开花。在专业图形加速领域,摩尔线程的MTT S3000利用GPU虚拟化和云端渲染技术,实现云电脑、云游戏和云AI PC的国产化,提供高性能低延迟的计算与渲染能力,并与中国移动、中国电信合作推动行业自主可控。MTT X300/S50在国产图形工作站市场具有性能优势,广泛应用于数字孪生、仿真模拟、地理信息系统和工业设计等领域,并完成超过150个生态软件的国产化兼容认证。MTT S10/S30板卡产品支持信创个人PC,与国产CPU、操作系统及品牌整机完成适配,服务多家企事业单位。
在AI算力领域,摩尔线程产品包括训推一体智算卡MTT S4000、支持FP8精度的MTT S5000,以及首代和二代超大规模智算融合中心产品KUAE1、KUAE2,覆盖千卡到万卡互联,已交付多个智算中心,用于大模型训练、推理和科学计算等核心场景。基于智能SoC芯片“长江”,摩尔线程已推出多款产品,包括面向AI PC的算力本A140和面向边缘计算及具身智能的智能模组E300,并计划推出迷你型电脑AI Cube及智能汽车座舱解决方案。摩尔线程正在以此为基础,在AI SoC领域布局未来十年的发展。
摩尔线程本次IPO的募集资金,精准地指向了新一代AI训推一体芯片研发、新一代图形芯片研发以及新一代AI SoC芯片研发,辅以流动资金补充。这清晰地表明,摩尔线程将坚定地在这三大领域齐头并进,加速推进自主可控的计算平台建设。
任何一家公司的基因都刻着创始人的烙印。在摩尔线程,这个烙印属于张建中。在创办摩尔线程之前,他在英伟达工作了15年,曾任英伟达全球副总裁、大中华区总经理。在芯片圈,张建中被公认为“最懂黄仁勋的中国人”之一。他不仅亲历了GPU从图形芯片演变为AI基础设施的全过程,更是一手搭建了英伟达在中国的庞大生态体系。从CUDA在高校的推广,到与游戏厂商的合作,再到AI初创企业的扶持,他深知英伟达的护城河是如何一砖一瓦砌起来的。
这解释了摩尔线程为何执着于“MUSA”统一架构。张建中比谁都清楚,如果不建立自己的统一架构,只做硬件兼容,永远只能是替代品。招股书显示,MUSA架构是摩尔线程自主研发的融合GPU硬件和软件的全功能GPU计算加速统一系统架构,涵盖统一的芯片架构、指令集、编程模型、软件运行库及驱动程序框架等关键要素。
事实上,摩尔线程的多位核心高管都来自顶尖芯片公司。团队不仅懂架构,懂生态,更懂市场,懂如何把一块芯片卖成服务。于是,市场看到了惊人的“摩尔线程速度”:创业仅仅5年,量产5颗芯片,迭代4代GPU架构。从受理到过会,科创板IPO审核仅用时88天。上市对于张建中和他的团队来说,并不是终点,而是一次关键的补给。这意味着摩尔线程将获得更充沛的弹药,去应对接下来的市场竞争。面对英伟达这个市值数万亿美元的全球霸主,摩尔线程手里的底牌是关于“全功能GPU”的中国故事,以及一群试图证明“中国也能做出来”的技术信徒。

新华社发文批"大字吸睛小字免责" 广告文字游戏需整治

“80后”上班族爬树成全国冠军 白天敲键盘周末攀大树

马航370藏着多少未说的秘密 真相仍待揭开

谁在给日本向右转猛踩油门 右翼势力加速洗脑民众

日本大量遗产无人继承 总额达58.7亿元 独居老人数量攀升所致

入室抢婴案二审择期宣判 家属盼重判

台军训练又出事,炮弹偏离预定轨道连砸三民宅

中央再提“稳楼市”释放什么信号 新型城镇化助力房产稳定

泽连斯基真的要谢幕了吗 停战信号与反腐风暴交织

4岁萌娃睡梦中被叫醒参加魔方比赛 仅用11秒复原魔方

德国政要相继表态承担历史责任!

周末中东部将转为偏暖格局 多地气温大幅回升

河北网友给家里燕子窝搭电热毯 暖心善举温暖寒冬

“两弹一星”元勋郭永怀逝世57周年!

麻生太郎与高市早苗沆瀣一气 挑战一个中国原则

马克龙成都之行暗藏怎样的深意 多重外交布局揭秘

网警提醒已有人买卖账号赚钱获刑 警惕成为犯罪“帮凶”
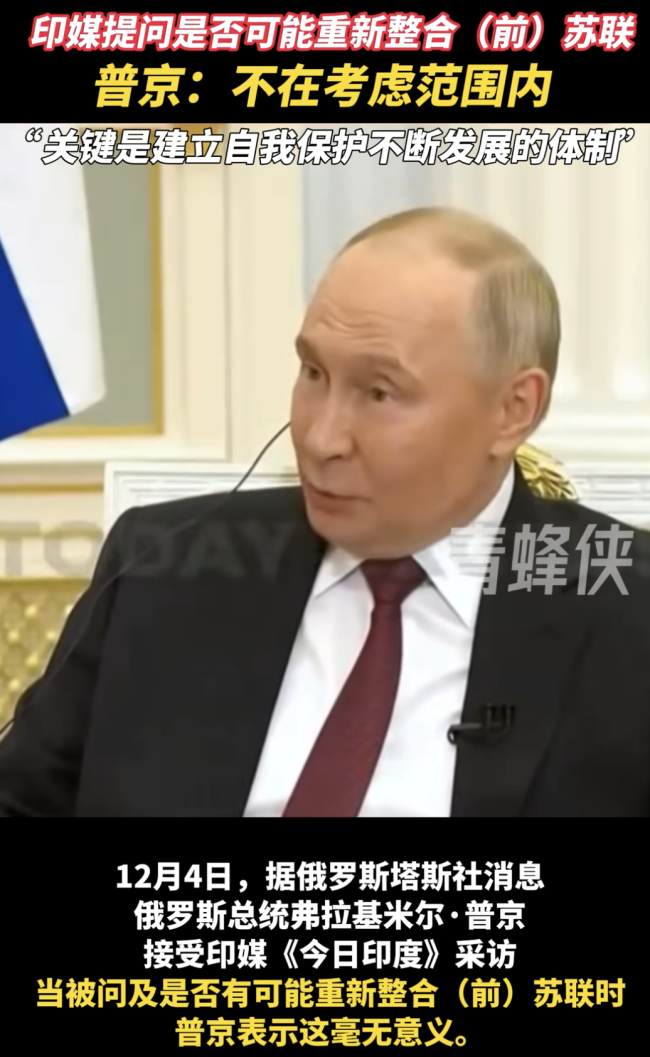
重新整合前苏联?普京:不考虑,毫无意义

俄罗斯给印度定心丸,印度不怕了!

混团世界杯循环赛:中国vs德国 林诗栋/蒯曼率先出战 中国队暂领先

普京称并不希望俄重新加入七国集团 G7影响力下降

警惕高市早苗假认怂耍花招 模糊话术逃避责任

戴尔创始人向特朗普账户捐62.5亿美元 助力儿童投资未来
委民众更害怕失控的通货膨胀!

为何窃取俄罗斯资产让欧盟处境更糟 计划遭拒引发争议

画面曝光!台陆军炮弹误落民宅 三户民宅受损
新华社发文批"大字吸睛小字免责" 广告文字游戏需整治

加班大头上线了!衣服都换好了结果又要上场
微型肺类器官可批量生产 或将改变未来肺病研究方式

混音加时落败!杨瀚森20 7 7 2 2填满数据栏 遭肘击创多项新高 加时惜败快船
马航370藏着多少未说的秘密 真相仍待揭开

普京向欧洲发出警告后,卡德罗夫发文力挺:绝不客气,随时待命 坚决支持普京立场
“80后”上班族爬树成全国冠军 白天敲键盘周末攀大树

哈尔滨大雪人要回归了 经典形象重现冰城

法国媒体记录下中国军人风采!
相关新闻
摩尔线程 国产GPU第一股上市
2025-12-05 10:05:14摩尔线程摩尔线程中签结果出炉 33600个号码揭晓
摩尔线程发布了首次公开发行股票并在科创板上市的网下初步配售结果及网上中签结果公告。本次发行的战略配售缴款及配售工作已经完成,最终共有33600个中签号码
2025-11-25 23:16:48摩尔线程中签结果出炉摩尔线程网上发行最终中签率 0.036%揭晓
2025-11-25 15:41:21摩尔线程网上发行最终中签率年内第一高价新股来了 摩尔线程发行价114.28元
2025-11-24 10:51:30年内第一高价新股来了摩尔线程子公司增资5000万 注册资本翻倍引发关注
12月5日,摩尔线程在科创板上市,引起广泛关注。天眼查工商信息显示,光速摩方智能科技(杭州)有限责任公司最近进行了工商变更,注册资本从5000万人民币增加到1亿人民币,增幅达100%
2025-12-05 13:22:29摩尔线程子公司增资5000万摩尔线程概念股集体大涨 多股涨停引领市场
2025-09-22 11:59:26摩尔线程概念股集体大涨