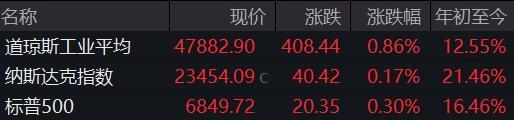
12月,金融圈和AI圈被同一个名字刷屏——DeepSeek创始人梁文锋。他掌舵的量化团队年收益飙超50%,管理规模700-800亿的幻方量化赚得盆满钵满;同时,DeepSeek大模型凭借低训练成本、开源模式和《自然》封面论文,成为国产AI领域的“普惠派代表”。当“量化收割机”与“AI开源者”的身份叠加,这位技术理性主义者的“双丰收”,究竟是可复制的神话,还是长期积累的必然结果?
一、从量化到AI:技术底层的“同频共振”很多人将梁文锋的“双赛道”视为跨界,但本质上,这是技术的“同频共振”。早在2008年,梁文锋就带领团队深耕量化交易的核心——算法与算力;2015年成立幻方量化后,他没有停留在“赚快钱”,而是在2019年投入真金白银搭建“萤火”超级计算机。这笔当时看似“不划算”的投入,后来成为DeepSeek大模型的“算力底座”——量化交易需要超算处理海量金融数据,AI训练同样需要算力支撑算法迭代。
用梁文锋的话说:“量化和AI都是‘用数据说话’的领域,区别只是应用场景不同。”幻方的量化策略依赖于对市场数据的精准建模,而DeepSeek的大模型则是对语言数据的深度理解,两者的核心都是“算法优化+算力支撑”。这种技术底层的一致性,让他得以在两个赛道之间实现“能力迁移”,而不是从零开始的“跨界冒险”。
二、DeepSeek的“拼多多逻辑”:用开源打破AI的“围墙”
DeepSeek能成为“AI界的拼多多”,本质上是戳中了AI行业的两大痛点——高成本与封闭性。过去,头部AI公司要么将大模型“藏着掖着”,要么收取高昂的调用费用,让中小开发者望而却步;而DeepSeek不仅将大模型开源,还公布了训练细节,甚至把训练成本控制到了行业平均水平的1/3。
支撑这一模式的,是梁文锋对“普惠AI”的理解:“AI不应该是少数公司的‘玩具’,而应该成为所有开发者的‘工具’。”DeepSeek的团队全部由国内高校毕业生组成,没有海外留学背景,但他们凭借对技术的热爱和“不搞KPI压榨”的文化,用三年时间完成了从0到1的突破——2024年9月,团队论文登上《自然》封面,成为全球首个经过同行评审的主流大模型。这份成绩,不是靠“砸钱堆算力”,而是靠算法优化和工程能力的提升。
就像拼多多用“拼团模式”降低了电商的准入门槛,DeepSeek用“开源+低成”模式降低了AI的使用门槛。截至2024年11月,DeepSeek的开源模型下载量已经突破1000万次,覆盖了教育、医疗、企业服务等多个领域,真正实现了“让AI普惠大众”。

三、双丰收的“可持续性”:运气之外,是15年的“死磕”
当梁文锋的“双丰收”刷屏时,质疑声也随之而来:“短期收益50%,能持续吗?”“AI开源会不会影响盈利?”但在梁文锋看来,这些质疑恰恰忽略了“长期主义”的价值——从2008年到2024年,他用15年时间打磨量化交易的算法,用4年时间搭建超算,用3年时间迭代大模型,所有的“爆发”都建立在“长期投入”的基础上。
以量化交易为例,幻方的收益不是靠“赌行情”,而是靠“系统的稳定性”。据幻方2024年三季度报告显示,其量化策略的夏普比率(衡量风险调整后收益)高达3.2,远高于行业平均水平的1.5。这背后是对市场数据的持续跟踪、算法的每日迭代,以及“萤火”超算的算力支撑。同样,DeepSeek的低成本不是靠“偷工减料”,而是靠对Transformer架构的优化——团队将模型的计算效率提升了40%,从而降低了训练成本。
梁文锋曾说:“我不相信‘一夜暴富’,所有的成功都是‘日拱一卒’的结果。”量化赚的是“时间的钱”,AI赚的是“生态的钱”,两者的结合,本质上是“短期现金流”与“长期价值”的平衡。这种平衡,让他既能够在量化领域“赚快钱”,又能在AI领域“做长期事”。
从量化交易到AI大模型,梁文锋的“双丰收”不是“跨界神话”,而是技术理性主义者的“必然结果”。他没有选择“allin”一个赛道,而是用技术的“同频共振”连接两个领域;他没有选择“封闭收费”,而是用“开源普惠”打破行业围墙;他没有选择“短期投机”,而是用“长期死磕”积累竞争壁垒。
对于普通人来说,梁文锋的故事带来的启示或许是:真正的“成功”,从来不是“选对一个赛道”,而是“用技术的底层逻辑,连接多个赛道”;从来不是“追求短期爆发”,而是“用长期积累,等待必然的结果”。