黄仁勋最新2万字演讲实录:机器人时代已经到来(8)

当然,你还可以将更多的这些系统连接在一起,形成更庞大的计算网络。但真正的奇迹在于这个MV链接芯片,随着大语言模型的日益庞大,其重要性也日益凸显。因为这些大语言模型已经不适合单独放在一个GPU或节点上运行,它们需要整个GPU机架的协同工作。就像我刚才提到的那个新DGX系统,它能够容纳参数达到数十万亿的大语言模型。
MV链接交换机本身就是一个技术奇迹,拥有500亿个晶体管,74个端口,每个端口的数据速率高达400GB。但更重要的是,交换机内部还集成了数学运算功能,可以直接进行归约操作,这在深度学习中具有极其重要的意义。这就是现在的DGX系统的全新面貌。
许多人对我们表示好奇。他们提出疑问,对英伟达的业务范畴存在误解。人们疑惑,英伟达怎么可能仅凭制造GPU就变得如此庞大。因此,很多人形成了这样一种印象:GPU就应该是某种特定的样子。
然而,现在我要展示给你们的是,这确实是一个GPU,但它并非你们想象中的那种。这是世界上最先进的GPU之一,但它主要用于游戏领域。但我们都清楚,GPU的真正力量远不止于此。
各位,请看这个,这才是GPU的真正形态。这是DGX GPU,专为深度学习而设计。这个GPU的背面连接着MV链接主干,这个主干由5000条线组成,长达3公里。这些线,就是MV链接主干,它们连接了70个GPU,形成一个强大的计算网络。这是一个电子机械奇迹,其中的收发器让我们能够在铜线上驱动信号贯穿整个长度。
因此,这个MV链接交换机通过MV链接主干在铜线上传输数据,使我们能够在单个机架中节省20千瓦的电力,而这20千瓦现在可以完全用于数据处理,这的确是一项令人难以置信的成就。这就是MV链接主干的力量。

为生成式AI推以太网
但这还不足以满足需求,特别是对于大型人工智能工厂来说更是如此,那么我们还有另一种解决方案。我们必须使用高速网络将这些人工智能工厂连接起来。我们有两种网络选择:InfiniBand和以太网。其中,InfiniBand已经在全球各地的超级计算和人工智能工厂中广泛使用,并且增长迅速。然而,并非每个数据中心都能直接使用InfiniBand,因为他们在以太网生态系统上进行了大量投资,而且管理InfiniBand交换机和网络确实需要一定的专业知识和技术。
因此,我们的解决方案是将InfiniBand的性能带到以太网架构中,这并非易事。原因在于,每个节点、每台计算机通常与互联网上的不同用户相连,但大多数通信实际上发生在数据中心内部,即数据中心与互联网另一端用户之间的数据传输。然而,在人工智能工厂的深度学习场景下,GPU并不是与互联网上的用户进行通信,而是彼此之间进行频繁的、密集的数据交换。
它们相互通信是因为它们都在收集部分结果。然后它们必须将这些部分结果进行规约(reduce)并重新分配(redistribute)。这种通信模式的特点是高度突发性的流量。重要的不是平均吞吐量,而是最后一个到达的数据,因为如果你正在从所有人那里收集部分结果,并且我试图接收你所有的部分结果,如果最后一个数据包晚到了,那么整个操作就会延迟。对于人工智能工厂而言,延迟是一个至关重要的问题。
所以,我们关注的焦点并非平均吞吐量,而是确保最后一个数据包能够准时、无误地抵达。然而,传统的以太网并未针对这种高度同步化、低延迟的需求进行优化。为了满足这一需求,我们创造性地设计了一个端到端的架构,使NIC(网络接口卡)和交换机能够通信。为了实现这一目标,我们采用了四种关键技术:
第一,英伟达拥有业界领先的RDMA(远程直接内存访问)技术。现在,我们有了以太网网络级别的RDMA,它的表现非常出色。
第二,我们引入了拥塞控制机制。交换机具备实时遥测功能,能够迅速识别并响应网络中的拥塞情况。当GPU或NIC发送的数据量过大时,交换机会立即发出信号,告知它们减缓发送速率,从而有效避免网络热点的产生。
第三,我们采用了自适应路由技术。传统以太网按固定顺序传输数据,但在我们的架构中,我们能够根据实时网络状况进行灵活调整。当发现拥塞或某些端口空闲时,我们可以将数据包发送到这些空闲端口,再由另一端的Bluefield设备重新排序,确保数据按正确顺序返回。这种自适应路由技术极大地提高了网络的灵活性和效率。
第四,我们实施了噪声隔离技术。在数据中心中,多个模型同时训练产生的噪声和流量可能会相互干扰,并导致抖动。我们的噪声隔离技术能够有效地隔离这些噪声,确保关键数据包的传输不受影响。
通过采用这些技术,我们成功地为人工智能工厂提供了高性能、低延迟的网络解决方案。在价值高达数十亿美元的数据中心中,如果网络利用率提升40%而训练时间缩短20%,这实际上意味着价值50亿美元的数据中心在性能上等同于一个60亿美元的数据中心,揭示了网络性能对整体成本效益的显著影响。
幸运的是,带有Spectrum X的以太网技术正是我们实现这一目标的关键,它大大提高了网络性能,使得网络成本相对于整个数据中心而言几乎可以忽略不计。这无疑是我们在网络技术领域取得的一大成就。
我们拥有一系列强大的以太网产品线,其中最引人注目的是Spectrum X800。这款设备以每秒51.2 TB的速度和256路径(radix)的支持能力,为成千上万的GPU提供了高效的网络连接。接下来,我们计划一年后推出X800 Ultra,它将支持高达512路径的512 radix,进一步提升了网络容量和性能。而X 1600则是为更大规模的数据中心设计的,能够满足数百万个GPU的通信需求。

随着技术的不断进步,数百万个GPU的数据中心时代已经指日可待。这一趋势的背后有着深刻的原因。一方面,我们渴望训练更大、更复杂的模型;但更重要的是,未来的互联网和计算机交互将越来越多地依赖于云端的生成式人工智能。这些人工智能将与我们一起工作、互动,生成视频、图像、文本甚至数字人。因此,我们与计算机的每一次交互几乎都离不开生成式人工智能的参与。并且总是有一个生成式人工智能与之相连,其中一些在本地运行,一些在你的设备上运行,很多可能在云端运行。
这些生成式人工智能不仅具备强大的推理能力,还能对答案进行迭代优化,以提高答案的质量。这意味着我们未来将产生海量的数据生成需求。今晚,我们共同见证了这一技术革新的力量。
Blackwell,作为NVIDIA平台的第一代产品,自推出以来便备受瞩目。如今,全球范围内都迎来了生成式人工智能的时代,这是一个全新的工业革命的开端,每个角落都在意识到人工智能工厂的重要性。我们深感荣幸,获得了来自各行各业的广泛支持,包括每一家OEM(原始设备制造商)、电脑制造商、CSP(云服务提供商)、GPU云、主权云以及电信公司等。
Blackwell的成功、广泛的采用以及行业对其的热情都达到了前所未有的高度,这让我们深感欣慰,并在此向大家表示衷心的感谢。然而,我们的脚步不会因此而停歇。在这个飞速发展的时代,我们将继续努力提升产品性能,降低培训和推理的成本,同时不断扩展人工智能的能力,使每一家企业都能从中受益。我们坚信,随着性能的提升,成本将进一步降低。而Hopper平台,无疑可能是历史上最成功的数据中心处理器。

Blackwell Ultra将于明年发布,下一代平台名为Rubin

云南5名网红被抓 诈骗粉丝11万余元
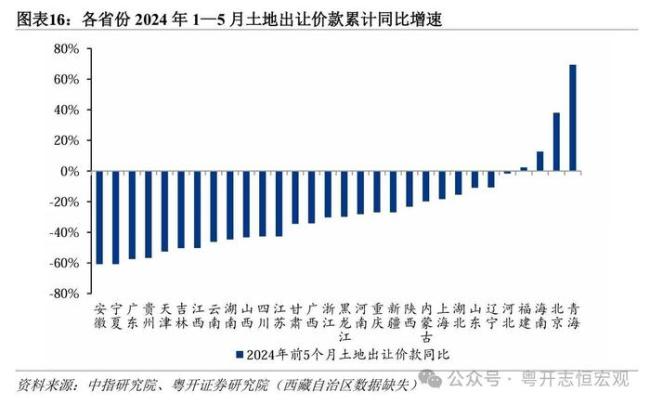
26省卖地收入下滑 地方政府财政承压求变

17岁2米28女姚明入选大名单:国字号首秀能一鸣惊人吗?!

以色列前总理:我们在这几个月中失去了世界的支持
云南5名网红被抓 诈骗粉丝11万余元

瞄准中国,美军加速!
17岁2米28女姚明入选大名单:国字号首秀能一鸣惊人吗?!

秀肌肉?美军“罗斯福”号航母抵韩,将参加韩美日“自由之刃”军演

娜扎新电影哭到我心里了,有点期待了!

白宫担忧以总理访美:不知道他会说些什么

专家称文理分科让毕业生就业更难 跨学科能力缺失成障碍

欲升级扩充核武库 美国引全球走向“最危险的时刻”

全面战争?美国向以色列保证

当美国海军“最可怕的噩梦”真的来了……

李凯尔辟谣退出男篮 期待再次披挂上阵
26省卖地收入下滑 地方政府财政承压求变

以美就武器交付问题陷入争吵,以防长访美寻求“解冻重型炸弹”

造价3亿多美元扛不住4级风 美军码头为何这么脆

沙特朝觐现死亡潮 千人亡,半数因酷热

普京强调国防只能依靠自己 自主军工确保国家安全

村干部下潜徒手清淤 排水渠通了,村民心暖了

普京:没人会援俄武器,我们能自给自足

“这就是宇宙中最道德的军队?”

乌克兰空袭克里米亚致5死逾百伤 俄方誓言回应
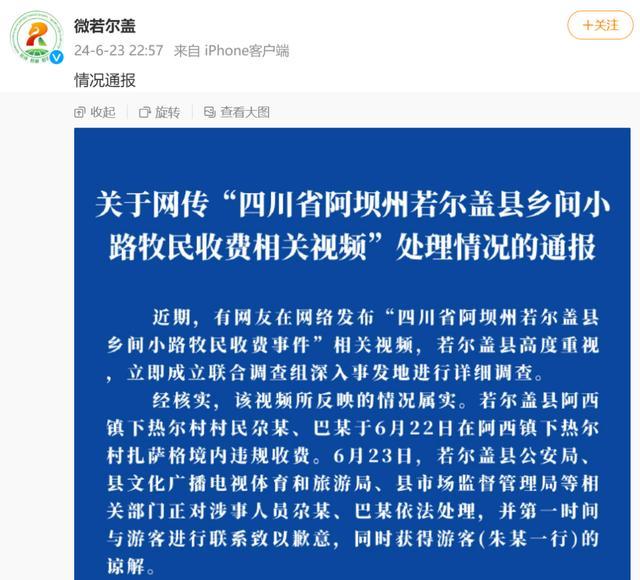
阿坝旅游遭拦路收费 官方通报处置结果

胡塞武装赶跑了“艾森豪威尔”号航母,菲律宾懵了!

汽车高管花式推荐大学专业 新机遇在哪?

俄对乌能源设施发动集群打击!泽连斯基:去年冬季以来,俄已摧毁乌一半发电能力

贵州村超少年圆梦欧洲杯 足球激情跨越国界

胡塞武装“袭击疑云”下,美军“艾森豪威尔”号航母撤离红海!

享界S9内饰曝光 8月上市 豪华行政级体验来袭

针对中国意图明显,效果遭到各界质疑!美军加速组建关岛“濒海作战团”
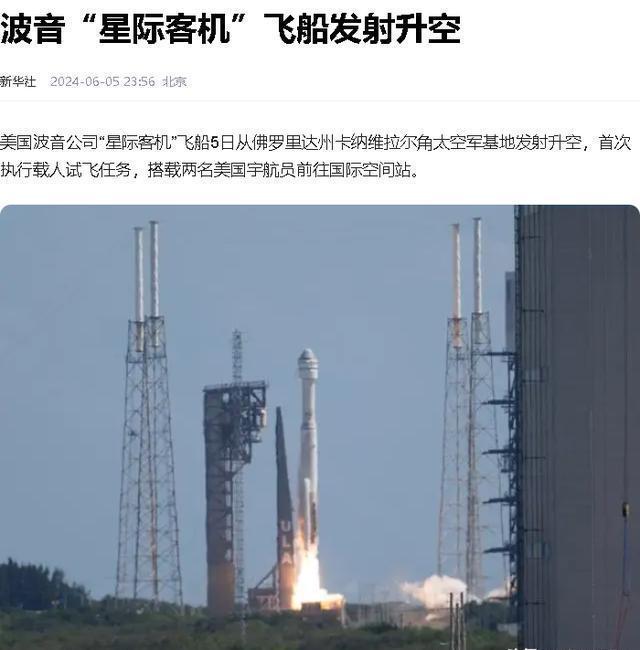
美国宇航员滞留太空 生命安危引关注

多地鼓励放弃、退出农村宅基地 新政策促房地产市场平稳发展

警惕!菲总统最新言论,话里有话
相关新闻
黄仁勋妄称台湾为“国家”,黄仁勋“飘”了?
美国英伟达公司的创办人及CEO黄仁勋访问台湾,此行引发台湾地区的高度关注,他的言论成为媒体聚焦点
2024-06-07 18:12:09黄仁勋妄称台湾为“国家”黄仁勋有望超越马斯克成全球首富 GPU巨头引领AI时代新篇章
英伟达的创始人兼CEO黄仁勋,自企业1993年于硅谷诞生起,便坐拥可观财富。近期,其个人资产更是经历了爆炸性增长,达到了前所未有的高度
2024-05-27 22:49:22黄仁勋有望超越马斯克成全球首富黄仁勋称台湾为国家 言论引争议
2024-06-07 08:18:25黄仁勋称台湾为国家马斯克向左,黄仁勋向右 华人首富之路加速?
华人问鼎全球首富的位置,正逐渐从梦想迈向现实。英伟达,在人工智能时代的潮头傲立,仅一年半内股价激增十倍,五年视野下更是实现了二十八倍的惊人飞跃
2024-06-01 12:37:58马斯克向左黄仁勋加州理工毕业典礼演讲:我是个好老板
2024-06-18 09:45:41黄仁勋加州理工毕业典礼演讲:我是个好老板黄仁勋在女粉丝胸前签名 引网络热议
英伟达首席执行官黄仁勋的台湾之行引发了广泛瞩目。无论他出现在哪里,总能吸引大量人群聚集,大家争相与他合影、索取签名。4日,黄仁勋出席了台北国际电脑展,期间发生了一件令人印象深刻的事。
2024-06-06 17:31:45黄仁勋在女粉丝胸前签名