OpenAI深夜发布首个文生视频模型Sora,现实将被彻底颠覆

2月16日凌晨,OpenAI再次扔出一枚深水炸弹,发布了首个文生视频模型Sora。据介绍,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。
目前官网上已经更新了48个视频demo,在这些demo中,Sora不仅能准确呈现细节,还能理解物体在物理世界中的存在,并生成具有丰富情感的角色。该模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。
例如一个Prompt(大语言模型中的提示词)的描述是:在东京街头,一位时髦的女士穿梭在充满温暖霓虹灯光和动感城市标志的街道上。
在Sora生成的视频里,女士身着黑色皮衣、红色裙子在霓虹街头行走,不仅主体连贯稳定,还有多镜头,包括从大街景慢慢切入到对女士的脸部表情的特写,以及潮湿的街道地面反射霓虹灯的光影效果。
另一个Prompt则是,一只猫试图叫醒熟睡的主人,要求吃早餐,主人试图忽略这只猫,但猫尝试了新招,最终主人从枕头下拿出藏起来的零食,让猫自己再多待一会儿。在这个AI生成视频里,猫甚至都学会了踩奶,对主人鼻头的触碰甚至都是轻轻的,接近物理世界里猫的真实反应。
OpenAI表示,他们正在教AI理解和模拟运动中的物理世界,目标是训练模型来帮助人们解决需要现实世界交互的问题。
随后OpenAI解释了Sora的工作原理,Sora是一个扩散模型,它从类似于静态噪声的视频开始,通过多个步骤逐渐去除噪声,视频也从最初的随机像素转化为清晰的图像场景。Sora使用了Transformer架构,有极强的扩展性。
视频和图像是被称为“补丁”的较小数据单位集合,每个“补丁”都类似于GPT中的一个标记(Token),通过统一的数据表达方式,可以在更广泛的视觉数据上训练和扩散变化,包括不同的时间、分辨率和纵横比。

雨天路滑货车超车后失控侧翻 西瓜遍地险成隐患

轿车突发自燃 公交司机帮忙灭火 见义勇为获赞

为什么得物越来越不受欢迎了?
为什么得物越来越不受欢迎了?

詹雯婷胜诉 网络谣言再引热议

交管12123 APP将升级优化 打造便民服务新体验
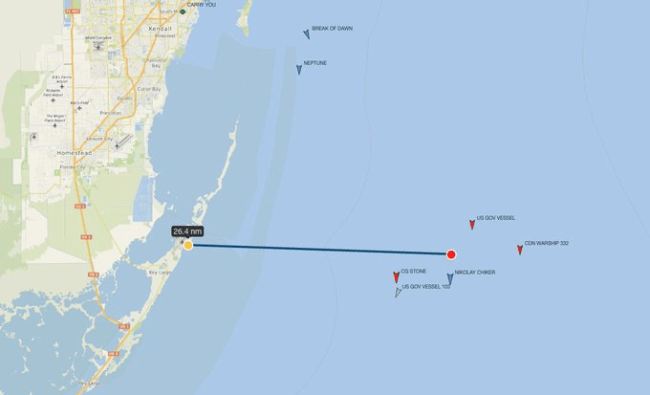
俄护卫舰核潜艇抵近佛罗里达,美军紧密监视

美国解禁乌克兰“亚速营”使用美制武器,俄方回应
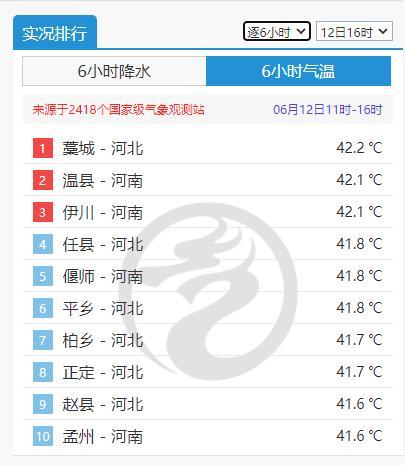
山河三省霸榜全国高温榜 多地地表温度超60℃

1周3国,泽连斯基密集外访要军援,求西方盟友助乌加强防空

俄醉酒男子从9楼坠落竟安然无恙 奇迹生还引热议

现在的米莱,超级有意思
雨天路滑货车超车后失控侧翻 西瓜遍地险成隐患
轿车突发自燃 公交司机帮忙灭火 见义勇为获赞

俄海军编队访古巴为什么让西方紧张?

三项罪名指控均成立!拜登之子被判有罪轰动美国,判决将在大选前出炉

建议大家购买饮料别加冰 健康风险需警惕

G7在质疑声中举行峰会,英媒:成员国领导人大都“心情沮丧”

权力的游戏?欧盟委员会主席选举暗藏激烈博弈
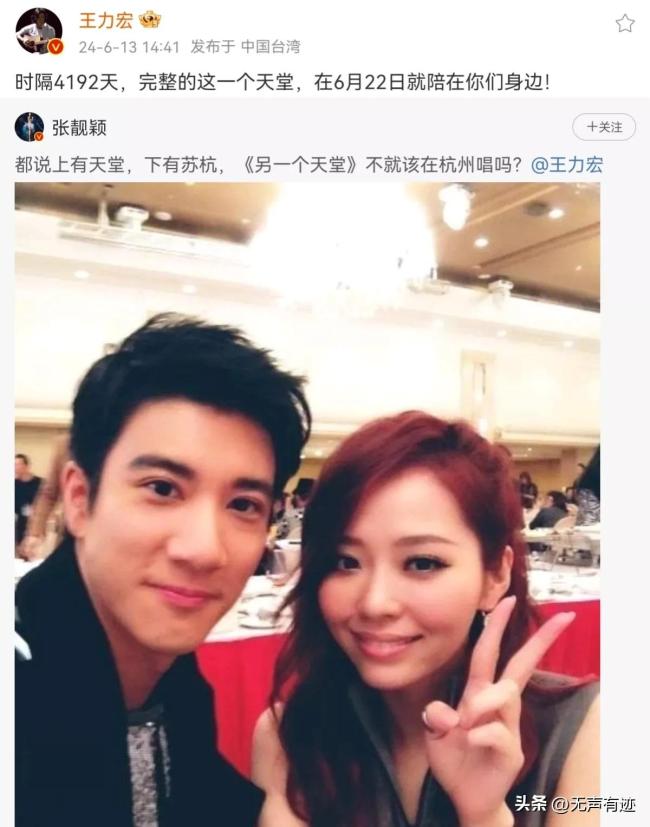
张靓颖嘉宾 王力宏携手献唱:土木建筑学子毕业在即

真主党高级指挥官被杀后,以色列北部遭160枚火箭弹攻击

北约秘书长:匈牙利同意不会阻止北约援助乌克兰,但也不会参与其中

墨雨云间男主吃烧烤蘸醋 剧中人设引热议

连任印度外长,苏杰生紧盯中印边境!

安理会通过加沙停火决议!哈马斯准备就细节展开谈判,以色列面临美国持续施压

“环太平洋2024”军演,美国海军为什么要击沉4万吨级准航母?
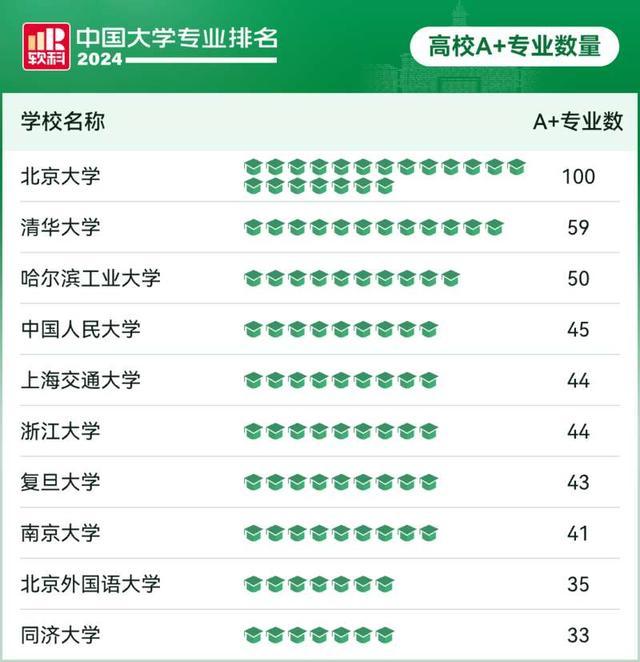
软科中国大学专业排名2024 北大清华哈工大领跑A+专业榜

起底婚介公司忽悠套路 消费者频遭"甜蜜陷阱

俄军通报:核潜艇在美国本土附近进行打击演习

以军行动持续 加沙地带多地发生激烈战斗
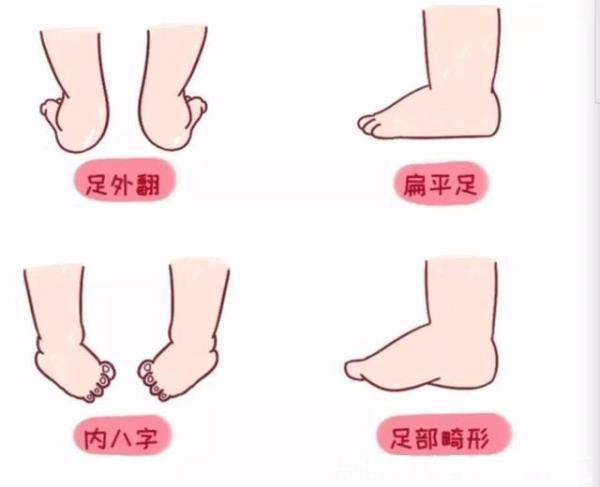
“踩屎感”拖鞋,可能不利脚部健康正在毁掉你的脚……
歌手改赛制应对争议:断眉退出引发变革

阿根廷计划援乌5架“超军旗”,乌克兰会嫌弃吗?
金硕珍被亲了!终于等到金硕珍退伍BTS退伍完成

安徽一挖机师傅清理河道挖到扬子鳄 多地接力搜寻鳄鱼踪迹
相关新闻
新模型Vidu直逼Sora,生数科技:还说“中国sora”就太没想象力了 国产AI视频新飞跃
4月27日,中关村论坛未来人工智能先锋论坛举行期间,生数科技携手清华大学宣布了一个重要成果:中国首个长时长、高一致性、高动态性视频大模型Vidu正式面世
2024-04-28 18:58:48新模型Vidu直逼SoraOpenAI发布全新生成式AI模型GPT-4o 交互革新,实时多模态引热议
5月14日,OpenAI在春季发布会上揭晓了其最新的旗舰AI模型——GPT-4o,这一模型以“全知全能”为目标,实现了实时的语音、文本、图像交互功能
2024-05-15 09:10:07OpenAI发布全新生成式AI模型GPT-4oOpenAI或将推出下一代GPT模型 超级智能新纪元
2024-05-22 09:04:45OpenAI或将推出下一代GPT模型OpenAI推出更快更便宜AI模型 GPT-4o引领人机交互新时代
2024-05-14 09:15:31OpenAI推出更快更便宜AI模型OpenAI新模型:图文音频全搞定,GPT-4o引领交互新时代
在周二凌晨1点的春季发布会上,OpenAI继“文生视频模型”Sora后再次为市场带来新惊喜
2024-05-14 09:07:05OpenAI新模型:图文音频全搞定OpenAI新模型:丝滑如真人,GPT-4o引领交互新时代
5月14日深夜,美国OpenAI公司举办线上“春季更新”活动,揭晓两大核心内容:发布最新旗舰模型GPT-4o及在ChatGPT服务中增添多项免费功能
2024-05-14 07:49:16OpenAI新模型:丝滑如真人







