消息称OpenAI大力研发音频AI模型 为语音交互设备铺路

OpenAI 正在全面强化自身的音频人工智能能力,为未来推出一款以语音为核心的个人AI设备铺路。这款设备将以听觉交互为主要形式,而非依赖屏幕。
目前,ChatGPT的语音功能与文本回答背后所使用的模型并不相同。OpenAI内部研究人员认为,现有音频模型在准确性和响应速度上明显落后,因此公司在过去两个月内整合了工程、产品和研究力量,集中攻克音频模型短板。这一调整直接指向OpenAI的硬件目标——打造一款可通过自然语音指令操作的消费级设备。首款产品预计至少还需要一年时间才能面世。
随着新架构的引入,音频模型已能生成更自然、更富情感的语音回应,并具备与人类同时发声、应对打断的能力。OpenAI计划在2026年第一季度正式发布该模型。在硬件形态上,OpenAI与谷歌、亚马逊、Meta和苹果的看法相似:现有主流设备并非为未来的AI交互而生。OpenAI团队希望用户通过“说话”而非“看屏幕”与设备互动,认为语音才是最贴近人类交流本能的方式。
合作推进硬件项目的乔尼・艾维也强调,无屏幕设计不仅更自然,还有助于避免用户沉迷。他认为,新一代设备应当纠正以往消费电子产品带来的负面影响,并为此承担责任。然而,OpenAI目前仍面临现实挑战。不少ChatGPT用户并未习惯使用语音功能,这种情况不仅因为音频模型效果不彰,也与功能认知不足有关。在推出音频优先的AI设备之前,OpenAI必须先改变用户的使用习惯。
OpenAI已组建专门团队推进音频AI战略。来自Character.AI的语音研究员昆丹・库马尔负责整体方向,本・纽豪斯正在重构面向音频的底层架构,多模态ChatGPT的产品经理杰基・香农也参与其中。OpenAI并不仅打算推出一款设备,而是规划了一条产品线,包括智能眼镜和无屏幕智能音箱。公司内部设想这类设备将以“伴随式助手”的形态存在,主动理解环境和用户需求,并在获得授权的情况下,通过音频和视频持续提供帮助。
为支撑这一长期布局,OpenAI已在2025年初斥资近65亿美元收购乔尼・艾维联合创办的io,并同步推进供应链、工业设计与模型研发等多条工作线。

57岁男子被限高到2099年才解除 最终顺利解禁
父母不信儿子车祸医院破例签字救人 紧急手术挽救生命

山东这块古匾实证琉球是中国藩属国 文物见证历史真相

台湾人用双脚表达对两岸关系的期待坚 持“九二共识”反对“台独”

刚结束访华后直奔日本,高市已设下晚宴,中方只回了6个字 大国博弈微妙
山东这块古匾实证琉球是中国藩属国 文物见证历史真相

煽动加拿大分裂美国能得逞吗 白宫野心遭遇抵制

宋佳以黑龙江政协委员身份回到家乡 不忘根脉助力发展
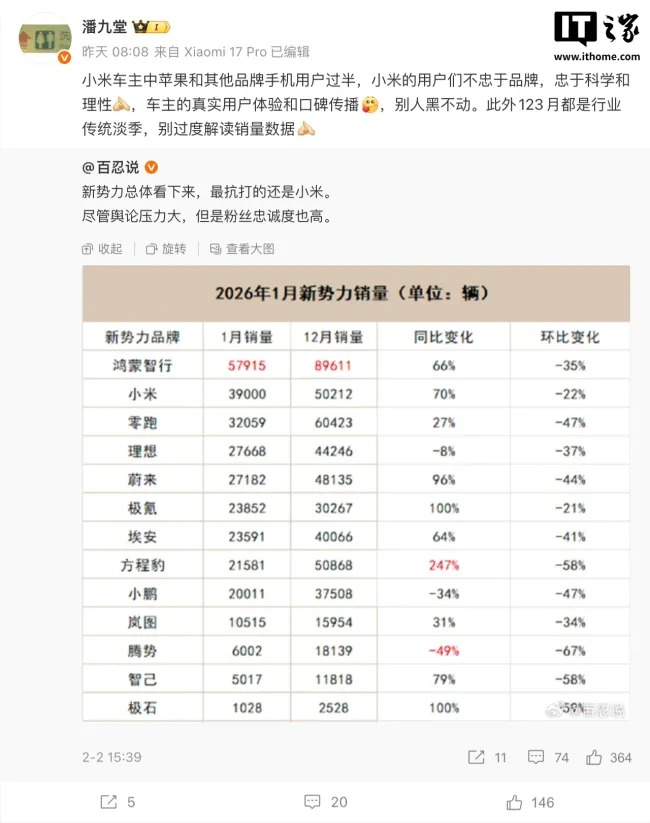
潘九堂谈小米汽车销量 理性看待淡季数据

轰-6K战巡南海,飞跃黄岩岛释放信号,一旦开战美军插手也没用 展现坚定主权意志

见义勇为者儿子称不放弃向其大嫂索赔 坚持法律维权

39岁刘心悦成春晚主持人新面孔 主持经历丰富
父母不信儿子车祸医院破例签字救人 紧急手术挽救生命

自然资源部:将“带押过户”服务从个人拓展到企业 优化营商环境关键举措

婚礼上女方父母退还女婿给的彩礼 传递爱与理解

英国首相访华4天访日仅停留7小时 时间差异凸显外交重心

日本15岁女生携600片安眠药被抓 青少年药物滥用问题严峻

第三方平台破解12306限购实为代购 付费抢票无实际意义

歼16飞行员说宝岛景色无以言表!

法国坚持要求:英国要想卖乌克兰武器,必须给欧盟交钱:利益博弈加剧

台湾省自制潜艇海鲲号海试 首艘自研潜艇展现实力

特朗普说与哥伦比亚总统相处融洽 会谈成果显著
57岁男子被限高到2099年才解除 最终顺利解禁

多家企业按吨向银行借金 对冲金价下跌风险

美国一男子躺在数十只冻僵的鬣蜥下 寒潮引发“天降蜥蜴”奇观

俄罗斯石油还买不买?莫迪不说话 美印协议背后的真相

警方通报夫妻网购娃娃菜食用中毒 实为敲诈勒索

菲两大家族斗法 正副总统陷弹劾旋涡 权力内斗激化

冰面下的巨鲸:伊朗影子经济的真相 影子经济支撑政权存活

老人失联10小时被发现时在冰河呼救 救援队深夜搜救成功

悬赏百万征集借千万未还男子线索 高额悬赏寻人

大V:泽连斯基恐进退两难 政治博弈中的选择难题

一刀省200亿?7500亿巨头也撑不住了?海航资金链断裂真相

委内瑞拉驻华大使发声 感谢中国坚定支持

评论员:伊朗局势面临三种可能结果,每条都可能通向万丈深渊!
相关新闻
OpenAI发布视频生成模型Sora2 AI视频的“ChatGPT时刻”
当地时间9月30日,OpenAI推出了一款全新社交媒体应用,这款应用基于升级版的AI视频生成器Sora 2。用户只需输入文本提示即可生成带音频的高清短片,并能上传视频至虚拟场景中与他人互动
2025-10-01 10:41:23OpenAI发布视频生成模型Sora2OpenAI等六大AI巨头遭作家起诉 盗版书籍训练模型引发诉讼
2025-12-23 13:21:08OpenAI等六大AI巨头遭作家起诉OpenAI突发两款开源模型 开发者可定制
OpenAI发布了两款免费使用的AI模型,GPT-oss-120b和GPT-oss-20b。这些模型可以根据用户提示生成文本内容,并允许开发者进行定制。然而,OpenAI并未提供用于训练这些模型的数据
2025-08-06 08:21:05OpenAI突发两款开源模型OpenAI发布2款开源模型 重大突破引领未来
OpenAI发布了两款可以免费使用的AI模型,GPT-oss-120b和GPT-oss-20b。这是自GPT-2发布以来,OpenAI首次推出新的开源大语言模型
2025-08-06 09:05:42OpenAI发布2款开源模型OpenAI:GPT-5将免费提供给用户 智能模型全面开放
OpenAI创始人兼CEO Sam Altman宣布,GPT-5采用集成模型,不再需要模型切换器。新模型能够自主决定何时进行更深入的思考,具备高度智能、直观且快速的特点,并将免费提供给用户
2025-08-08 01:41:58GPT-5将免费提供给用户OpenAI:GPT-5将免费提供给用户 智能模型全面开放
OpenAI创始人兼CEO Sam Altman宣布,GPT-5将采用集成模型,不再需要模型切换器,能够自行决定何时进行更深入的思考。这款新模型具备高度智能、直观且快速的特点,并将免费提供给用户
2025-08-08 08:06:36GPT-5将免费提供给用户







