OpenAI等六大AI巨头遭作家起诉 盗版书籍训练模型引发诉讼

当地时间12月22日,两届普利策新闻奖得主约翰·卡雷鲁牵头的作家群体向美国加州北区地方法院提起集体诉讼,将OpenAI、谷歌、Meta、Anthropic、xAI及Perplexity AI六家AI公司列为共同被告,指控其通过盗版书籍训练模型构成“蓄意侵权”。卡雷鲁曾揭露硅谷血液检测创业公司Theranos的骗局,并据此出版了《滴血成金》一书。
诉状显示,原告的核心指控集中于“双重侵权链条”:这六家公司从LibGen、Z-Library等非法影子图书馆批量下载数百万册小说和纪实作品等盗版书籍,再将这些著作用于大语言模型训练与产品优化,形成“盗版获取-模型训练-商业变现”的非法闭环。原告方强调,作家的智力成果支撑起价值数十亿美元的AI生态,却未获分文补偿。若陪审团认定侵权属故意行为,每部侵权作品最高可获赔15万美元。
这不是AI公司首次卷入文字作品侵权纠纷。据报告,OpenAI是行业“被诉大户”,已面临至少14起版权诉讼。早在2023年底,《纽约时报》就因侵犯版权起诉微软和OpenAI,称报纸发表的数百万篇文章被用于训练智能聊天机器人。《纽约时报》认为,被告应为非法复制和使用其独特而有价值的作品相关的损失负责,并要求销毁使用其版权材料的任何AI模型和训练数据。
今年6月,OpenAI对《纽约时报》要求无限期保留消费者ChatGPT和API客户数据的诉讼请求提起上诉,认为这项诉讼请求违背了其对用户做出的隐私承诺。此外,《纽约时报》还向生成式AI初创公司Perplexity发出停止并终止通知,要求后者停止访问和使用其内容。
Anthropic因使用盗版书籍训练Claude模型被告,最终在2025年6月被美国加州法院裁定“盗版数据不适用合理使用”,迫使该公司支付15亿美元和解并销毁侵权数据。尽管xAI与Perplexity AI成立时间较短,但此次被指控的侵权模式与行业巨头高度一致,暴露出AI公司对盗版数据的依赖。
该案审理地加州北区法院已受理25起AI版权案件,占全美同类案件半数以上,其判决结果或将成为界定AI训练数据合法性的关键标尺。

竹子穿透路灯生长 成网红打卡地 生命力顽强令人称奇

中国GDP跨越140万亿元关口 经济增长5.0%

神舟二十号,回家啦 航天英雄平安归来

台退将称歼20将改变西太军力平衡

江湖是英文无法翻译的词 央视点赞武侠情怀
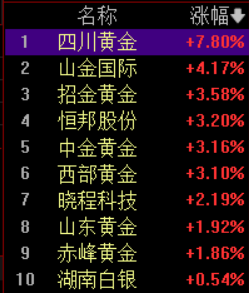
现货黄金站上4690美元 贵金属创历史新高

胖东来为什么要抑制扩张 业绩越好越要踩刹车?

南部战区发声:完全正当合法 无人机正常训练

“高超音速导弹”天团:鹰击-21、东风-17、东风-26D如何各司其职?

专家:美国霸权露出致命裂缝 航母闹剧暴露短板

卫星图揭露日本驱逐舰航母化改造 F-35B战机部署进展

金银大涨后铜条悄悄火了 投资新宠引发热议
中国GDP跨越140万亿元关口 经济增长5.0%

血战利曼!15公里战线乌军只部署千人 乌军防线告急

欧盟37人大军少了15人!丹麦部队手里的武器,都是美式武器

一觉醒来金银又涨了 贵金属延续强势

俄专家称普京若被暗杀欧洲核弹洗地!

非洲顶流大象离世终年54岁 传奇“超级长牙”陨落

樊振东暴力轰击连拿6分 落后不慌,力挽狂澜!

俄谈欧洲多国近期对俄立场 能源博弈影响民生

西安一烤鱼店开业有人排队11小时 食客为正宗麻辣味甘愿等待

卫星发射前零件失效只能归零再来 航天探索的坚韧之路

神二十成功着陆 应急救援彰显航天韧性

美媒声称目前还没有六代机!

匈牙利总理:西欧正准备与俄罗斯开战 欧盟会议变军事讨论

欧洲和美国要开撕了吗 欧盟多国考虑对美国商品加征关税

深圳一全职主妇屡遭丈夫责骂吞药轻生 精神摧残何其残忍

“南天门计划”是科幻?未来空天趋势探析

北京八达岭长城再现北国风光冰封雪飘 银装素裹迎游客

国新办介绍2025年国民经济运行情况 高质量发展成效显著

特朗普为何中止对伊朗动手 盟友压力与军事评估叫停战争

伊朗最高领袖:美国和以色列是伊朗暴力事件幕后黑手 指责特朗普造成伤亡

欧洲被美国逼到墙角 被迫寻求与俄对话
竹子穿透路灯生长 成网红打卡地 生命力顽强令人称奇
神舟二十号,回家啦 航天英雄平安归来
相关新闻
OpenAI拉上巨头豪赌AI基建 万亿赌局引领未来
2025-10-11 08:33:39OpenAI拉上巨头豪赌AI基建新西兰作家用AI生成封面遭大奖除名 新规引发争议
新西兰国家广播电台报道,因封面设计中使用了人工智能技术,两位知名作家被奥克兰图书奖评选委员会除名
2025-11-19 13:43:05新西兰作家用AI生成封面遭大奖除名马斯克正式起诉OpenAI苹果 指控不公平竞争
马斯克发起诉讼,指控苹果公司和OpenAI在iPhone上不公平地偏袒OpenAI的人工智能应用程序,阻碍其他聊天机器人制造商的竞争
2025-08-26 09:48:34马斯克正式起诉OpenAI苹果美科技巨头掀起AI“军备竞赛” 角逐AI高地
美国正在经历一场迅速升级的人工智能人才争夺战,其中Meta首席执行官扎克伯格表现得尤为激进。他试图从各个顶级AI研究实验室吸引顶尖人才,并为此提供了高达1亿美元的签约奖金,此举在硅谷引起了轩然大波
2025-07-03 13:10:38美科技巨头掀起AI军备竞赛OpenAI推出首款AI浏览器 ChatGPT Atlas正式发布
2025-10-22 14:14:33OpenAI推出首款AI浏览器OpenAI密集落子算力帝国 巨头资本交织布局
近期,OpenAI密集推进算力扩张,频频签下巨额合作协议,引发市场热潮。9月25日,由英伟达支持的云服务初创公司CoreWeave追加最高224亿美元供给,较3月承诺的119亿美元翻倍
2025-09-30 20:47:14OpenAI密集落子算力帝国