微软新模型一图秒生成超燃游戏大片 16亿参数助力创意无限

微软的研究团队最近在国际顶级学术期刊Nature上发表了一项新成果,名为Muse的视频游戏生成模型。该模型基于近七年的游戏数据进行训练,参数量最高达到16亿,能够理解游戏中的物理和3D环境,并生成玩家动作及视觉效果。不过,目前它仅能以300×180像素的分辨率生成游戏画面。
Muse生成的游戏视频效果保持了一致性、多样性和持久性。这意味着它可以生成长达两分钟的一致游戏序列,提供不同摄像机移动角度、角色和游戏工具的多样性,并支持开发者添加新元素并自动融入画面。这项工作由微软研究员游戏智能团队、可教的AI体验团队与Xbox Games Studios旗下的Ninja Theory合作完成。
为了让更多开发者体验这项技术,微软开源了权重和样本数据,并提供了可视化交互界面WHAM Demonstrator。开发者可以在Azure AI Foundry上学习和试验这些资源。Xbox也在考虑利用Muse为用户构建简短的交互式AI游戏体验,即将在Copilot Labs上试用。
Muse在7Maps数据集上进行了训练,每张图像被编码为540个Tokens,数据量相当于七年多的人类游戏时间。此外,还有较小规模的数据集用于特定地图上的训练。通过提示模型使用10个初始帧(1秒)的人类游戏和整个游戏序列的控制器动作,可以生成多个可能的延续图像。用户还可以浏览生成的序列并进行调整,例如使用游戏控制器指导角色行动,这展示了Muse如何将迭代作为创作过程的一部分。
研究人员总结了27名从事游戏开发的创意人员的意见,确定了模型需要具备一致性、多样性和持久性三大能力。一致性使得生成的序列随时间推移并与游戏机制保持一致;多样性允许模型产生大量不同的序列,反映不同的潜在结果;持久性则使用户对游戏视觉效果和控制器动作进行修改,并将其同化到生成的游戏序列中。

山西女硕士失踪案进入审查起诉阶段 卜某事件涉案人员或涉嫌强奸罪
山西女硕士失踪案进入审查起诉阶段,涉嫌罪名或包括强奸罪

《将门毒后》少年少女就让少年少女演

匈总理要求欧盟不让乌克兰加入 欧尔班提出12点要求

老人坐银行转椅摔伤起诉索赔10万 银行被判无需赔偿
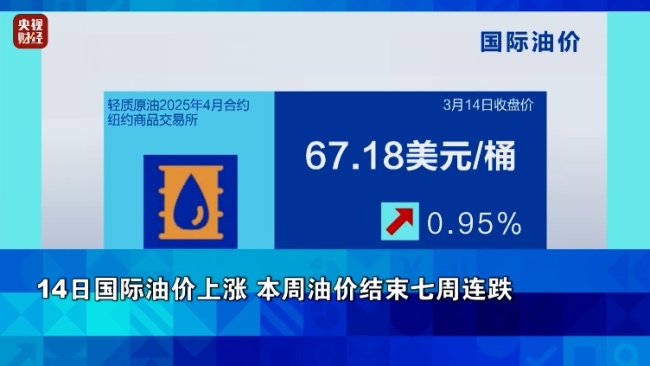
本周三油价或迎年度最大降幅 司机们加油可省近10元

俄罗斯会否两手准备以战促谈,谈不拢就开打?

莫迪对华最新表态:确保分歧不会演变成争端,进行“健康且自然”的竞争 强调对话解决问题

伊朗回应美国:勿再做以色列帮凶 坚决反对美军空袭
《将门毒后》少年少女就让少年少女演
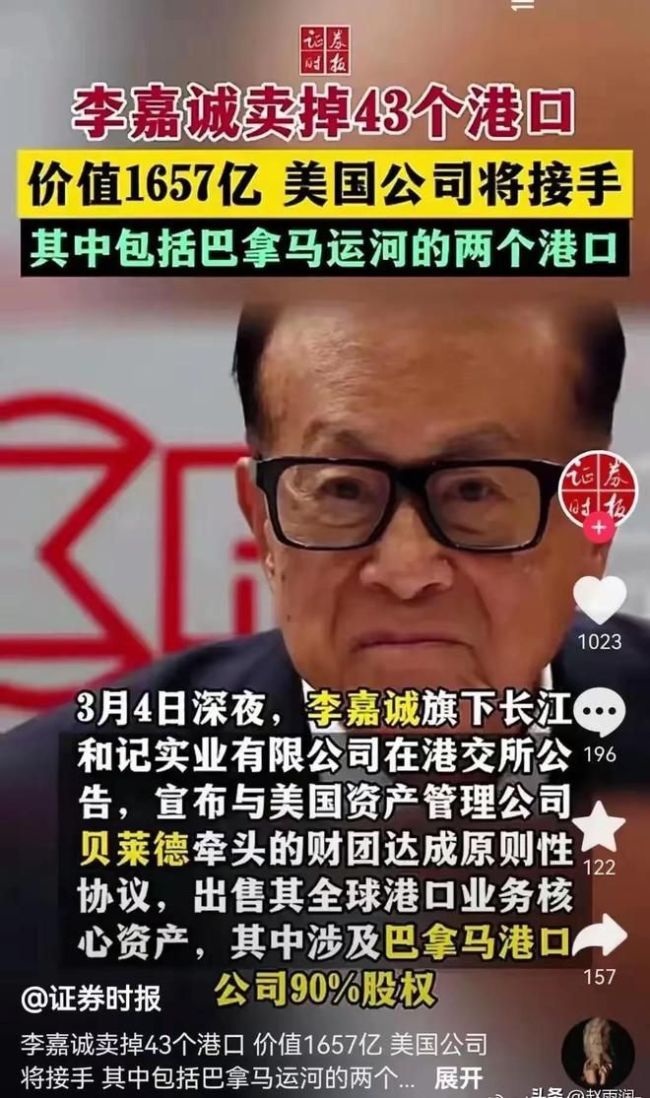
港媒三评李嘉诚出售港口:饮水思源 商业与民族情怀的抉择

预测:菲律宾总统马科斯的结局,谁将笑到最后?
山西女硕士失踪案进入审查起诉阶段,涉嫌罪名或包括强奸罪

学者解读特朗普下令空袭胡塞武装 意在向伊朗发出警告
FBI等部门警告:美数百用户已遭“美杜莎”勒索软件攻击!

国足“嵌合体”阵容迎来蜕变时刻 新星闪耀助力升级

结婚下车时新郎出糗直呼重新来

虞书欣维权案5月开庭
美方再次施压乌克兰割地 谈判僵局难解

俄罗斯对停火为何既积极又谨慎 战场形势决定态度

乌在库尔斯克作战行动结束意味着啥 战场失利与外部施压交织

“90后”潘林枫已归国任职 投身太阳能燃料研究

资通电军是干什么的 网络攻击与渗透真相
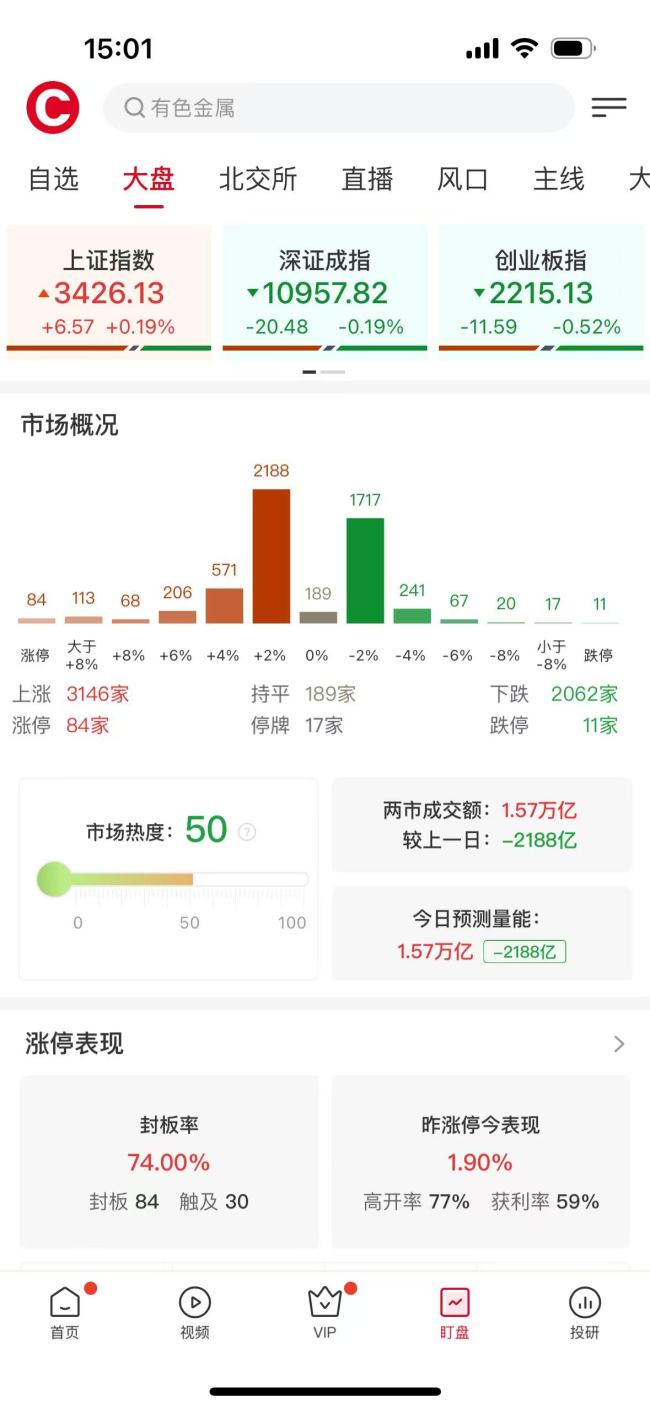
两市成交额不足1.6万亿 市场窄幅震荡分化
山西女硕士失踪案进入审查起诉阶段 卜某事件涉案人员或涉嫌强奸罪

匈总理要求欧盟不让乌克兰加入 向欧盟提出十二项要求

“胖猫”事件续:办案民警遭网暴 谣言侵蚀信任基础

国新办发布会介绍提振消费情况 多部门联合解读政策

事关和平协议 俄坚持要求乌做到两点 中立与拒入北约
FBI等部门警告:美数百用户已遭“美杜莎”勒索软件攻击,威胁范围正在扩大

“用了18枚导弹”!美国航母突然遭袭 胡塞武装誓言报复

青岛姑娘在韩国摆摊卖中国小吃,2小时卖出200个肉包

暖心!女子丢失车钥匙被人系红绳提醒
iOS19外观要变了 借鉴visionOS设计

英国邀20国派兵乌克兰有何意味 欧洲战略自主的尝试
相关新闻
微软游戏业务寻求新收购 拓展市场版图
2024-11-14 09:01:01微软游戏业务寻求新收购超燃!海警新年开训大片震撼来袭
2025-01-03 10:48:02超燃!海警新年开训大片震撼来袭英伟达与微软达成新合作 加速游戏图形处理
2025-03-14 03:21:12英伟达与微软达成新合作DeepSeek文生图新模型优于OpenAI 技术突破引发关注
北京时间1月28日凌晨,农历新年前夕,中国人工智能初创公司DeepSeek在GitHub和Hugging Face上发布了多模态大模型Janus-Pro,进军文生图领域
2025-01-29 04:29:50DeepSeek文生图新模型优于OpenAI微软上月游戏收入高达4.62亿美元 《使命召唤》功不可没
2025-01-31 10:21:42微软上月游戏收入高达4马斯克发布新模型 称能力超DeepSeek Grok 3亮相引发关注
2025-02-18 13:56:45马斯克发布新模型称能力超DeepSeek