DeepSeek发新成果 稀疏注意力机制NSA显著提升长上下文处理速度

2月18日,DeepSeek团队发布了一篇新论文,介绍了一种改进的稀疏注意力机制NSA,适用于超快速的长上下文训练与推理。NSA以性价比极高的方式在训练阶段应用稀疏性,在训推场景中均实现速度的明显提升,特别是在解码阶段实现了高达11.6倍的提升。
DeepSeek创始人兼CEO梁文锋出现在了合著名单之中,位列倒数第二,表明他作为项目管理者参与了一线研究工作。这篇论文的第一作者Jingyang Yuan是在实习期间完成的研究。
NSA具有三大核心组件:动态分层稀疏策略、粗粒度token压缩和精粒度token选择。这些组件协同工作,既提升了效率,也保留了模型对全局长上下文的感知能力和局部精确性。NSA专门针对现代硬件进行优化设计,支持模型训练,加速推理并降低预训练成本,对性能无明显影响。采用NSA机制的模型在通用基准、长上下文任务和基于指令的推理上,与全注意力模型相当或表现更优。
在8卡A100计算集群上,NSA的前向传播和反向传播速度分别比全注意力快9倍和6倍,由于减少了内存访问量,NSA在长序列解码时相较于全注意力模型速度显著提升。
长文本建模是下一代语言模型的关键能力,但传统注意力机制的高复杂度限制了其在长序列上的应用。例如,在解码64k长度的上下文时,注意力计算占据了总延迟的70%至80%。因此,稀疏注意力机制应运而生,通过选择性计算关键的查询键对来减少计算开销。然而,许多稀疏注意力方法在实际推理中未能显著降低延迟。
一些方法仅在自回归解码阶段应用稀疏性,而预填充阶段仍需进行密集计算;另一些方法仅关注预填充阶段的稀疏性,导致在某些工作负载下无法实现全阶段加速。还有部分稀疏方法无法适应现代高效的解码架构,导致KV缓存访问量仍然较高,无法充分发挥稀疏性优势。此外,现有的稀疏注意力方法大多仅在推理阶段应用稀疏性,缺乏对训练阶段的支持。

命案逃犯不敢结婚怕说梦话暴露 15年终落法网

美滞留空间站宇航员拟18日返回 提前结束漫长太空之旅

中国首个“星际矿工”诞生 太空资源开发迈出关键一步
FBI等部门警告:美数百用户已遭“美杜莎”勒索软件攻击!

乌在库尔斯克作战行动结束意味着啥 战场失利与外部施压交织

特朗普轰炸也门是地缘政治秀吗 战争背后的深层逻辑

莫迪对华最新表态:确保分歧不会演变成争端,进行“健康且自然”的竞争 强调对话解决问题

资通电军是干什么的 网络攻击与渗透真相

护士长路遇车祸上演教科书式救援 为患者争取了宝贵的每一分每一秒

俄罗斯会否两手准备以战促谈,谈不拢就开打?

一组“腿脚操”给血管减龄,让血管重返年轻态!
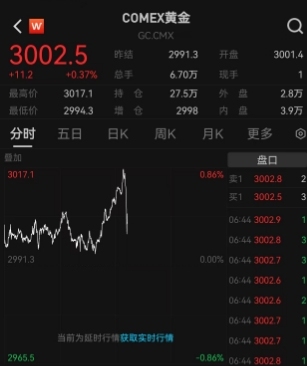
再创历史新高的黄金还能接着涨吗 三大驱动力推动金价飙升

泽连斯基重申不承认被占领土属于俄 坚定立场不变

机器人跳斧头帮舞蹈致敬《功夫》 AI合成引发热议

“用了18枚导弹”!美国航母突然遭袭 胡塞武装誓言报复

国际资本对俄资产“蠢蠢欲动” 押注制裁解除

英国邀20国派兵乌克兰有何意味 欧洲战略自主的尝试

Jonathan‘s 11 Years,loewe创意总监离任
命案逃犯不敢结婚怕说梦话暴露 15年终落法网

医院回应1750元招保安要求35岁以下 高要求引发热议

新款iPad侧面印中国制造 字样位置变化引关注
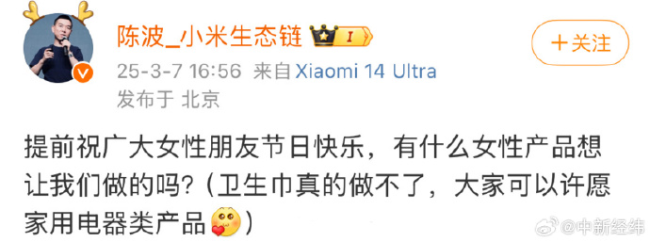
小米高管删除“不做卫生巾”博文 卫生巾质量问题引热议

事关和平协议 俄坚持要求乌做到两点 中立与拒入北约

预测:菲律宾总统马科斯的结局,谁将笑到最后?

学者解读特朗普下令空袭胡塞武装 意在向伊朗发出警告
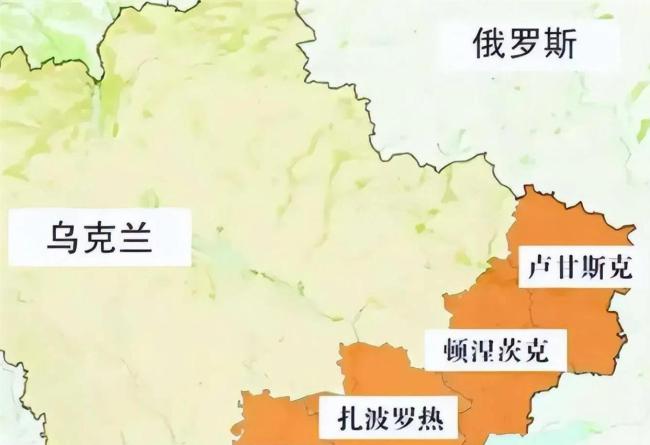
美方再次施压乌克兰割地 谈判僵局难解
中国首个“星际矿工”诞生 太空资源开发迈出关键一步
美滞留空间站宇航员拟18日返回 提前结束漫长太空之旅

匈总理要求欧盟不让乌克兰加入 欧尔班提出12点要求

县医院招保安要求35岁以下大专以上 回应:属实!

俄罗斯对停火为何既积极又谨慎 战场形势决定态度

匈总理要求欧盟不让乌克兰加入 向欧盟提出十二项要求
FBI等部门警告:美数百用户已遭“美杜莎”勒索软件攻击,威胁范围正在扩大

伊朗回应美国:勿再做以色列帮凶 坚决反对美军空袭

国乒大合影给受伤的王曼昱留了位置 团队温暖细节感人
相关新闻
《唐探1900》发新预告 欢喜冤家大显神通
旧金山突发轰动全美的奇案,“开膛手杰克”疑似再现,嫌疑人范围指向旧金山唐人街。1月21日,《唐探1900》最新发布的“所笑披靡”版预告片引发观众强烈期待
2025-01-22 11:03:57唐探1900发新预告《射雕英雄传:侠之大者》发新预告 铁血丹心唤武侠情怀
1月25日,武侠电影《射雕英雄传:侠之大者》发布了“铁血丹心”特别预告
2025-01-26 10:53:15射雕英雄传以对贝鲁特发新撤离令 以军空袭接踵而至
10月8日晚,以色列国防军发言人阿维凯·阿德拉伊在社交媒体上宣布了一项紧急撤离指令。该指令针对的是黎巴嫩首都贝鲁特南郊特定几栋建筑物的居民,要求他们立即离开,前往距离建筑物至少500米外的地方避险
2024-10-10 21:07:12以对贝鲁特发新撤离令周杰伦宣布暑假要发新专辑 粉丝兴奋期待
2025-02-09 07:41:37周杰伦宣布暑假要发新专辑DeepSeek在自动驾驶中有何优势 车圈刮起“DeepSeek风”
2025-02-18 06:34:40DeepSeek在自动驾驶中有何优势实测DeepSeek做奥数题写作文 DeepSeek火爆全球
2025-01-27 20:13:31实测DeepSeek做奥数题写作文







