美大模型巨头:DeepSeek没我们先进 AI竞争白热化

DeepSeek R1的推出给全球AI行业带来了新的变数。面对这一冲击,美国两大AI巨头Anthropic与OpenAI迅速做出回应,试图缓解市场对其技术领先地位的担忧。
周三,Anthropic首席执行官达里奥·阿莫迪发布了一篇长文讨论了DeepSeek的进展。他指出,DeepSeek并没有“用600万美元做到美国AI公司花费数十亿美元才能实现的事情”。以Anthropic为例,Claude 3.5 Sonnet是一个中等规模的模型,训练成本达数千万美元,远非数十亿美元级别。他认为DeepSeek的训练成本降低符合行业趋势,并不代表突破性的技术成就。如果AI训练成本每年下降4倍,而DeepSeek-V3的训练成本比一年前开发的美国当前模型低约8倍,这完全符合正常趋势。即使接受DeepSeek的训练成本数据,他们也只是处于趋势线上,甚至可能还未完全达到。
此前一天,OpenAI首席研究员Mark Chen也对DeepSeek R1做出回应,其态度既肯定又带有一丝微妙。Chen承认DeepSeek“独立发现了OpenAI在o1模型研发过程中的一些核心理念”,但他将焦点转移到成本问题上,认为“外界对成本优势的解读有些过头”。他还提到了“蒸馏技术”的成熟和“成本与能力解耦”的趋势,强调OpenAI在模型压缩和优化技术方面的探索。他表示,低成本服务模型并不意味着拥有更强的模型能力。OpenAI将继续在降低成本和提升能力两个方向上努力,并承诺今年会发布更优秀的模型。
纽约大学教授、AI专家Gary Marcus则认为,DeepSeek对OpenAI的影响可能比想象中更大。他指出,DeepSeek基本上免费提供了OpenAI想要收费的东西,这可能会严重影响OpenAI的商业模式。此外,DeepSeek比OpenAI更开放,这将吸引更多人才。Marcus质疑OpenAI 1570亿美元的估值,在每年损失约50亿美元的情况下,这一估值难以证明合理性。
阿莫迪进一步解释了AI发展的三大定律:规模法则、计算成本的下降和训练范式的变化。规模法则表明,训练规模越大,AI在一系列认知任务上的表现越稳定、越出色。计算成本的下降则是由于算法和硬件的改进,使得AI训练的计算成本每年下降约4倍。训练范式的改变则体现在从预训练到强化学习的发展。这些因素有助于理解DeepSeek最近的发布。尽管DeepSeek在某些方面表现出色,但并未从根本上改变LLM的经济性,它只是持续成本降低曲线上一个预期的点。不同的是,这次第一个展示预期成本降低的公司是中国的,这在地缘政治上具有重要意义。美国公司很快也会跟上这一趋势。

鹿晗关注了Sana的ins 粉丝热议不断

医疗主题基金迎战略机遇期 AI技术驱动增长

1月厦门维修进境飞机增两成 航空维修产业迎“开门红”

朗普新任期将满月:政策落地遇阻,全球市场格局生变

美国东部8州遭洪灾影响上亿人?肯塔基紧急状态,真有这么严重吗 致命风暴致8人死亡

外援斯蒂尔再度控诉NBL江西男篮欠薪 薪水拖延问题持续发酵

拉夫罗夫抵达沙特 单手揣兜下飞机 谈判桌上的博弈
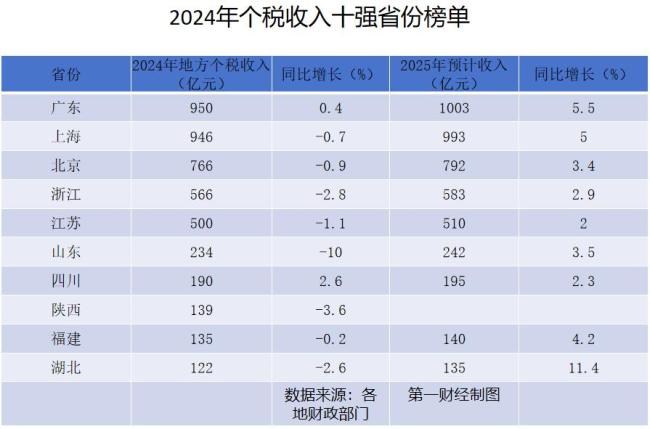
个税收入十强省份公布 广东重夺榜首

本·西蒙斯晒出海钓鱼视频 快船新旅程开启

王大陆经纪人拒接电话 事件非同小可
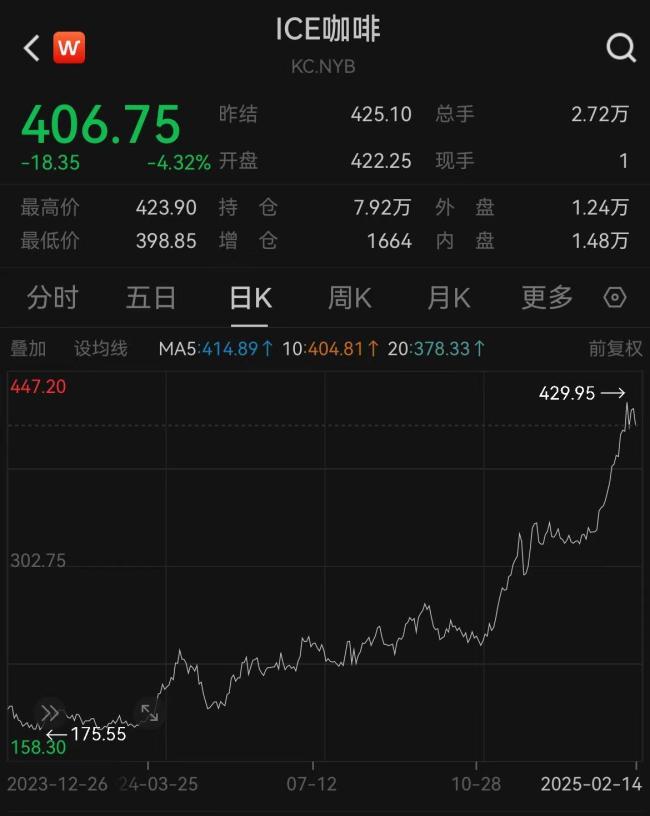
多品牌回应咖啡是否涨价 成本上涨引关注

美方:乌克兰能“上桌”谈判 欧洲被排除引发争议
医疗主题基金迎战略机遇期 AI技术驱动增长

0日将允许户籍栏登记可填“台湾” 外交部敦促 恪守一个中国原则

美为何提议从中国向乌派遣维和人员 美国的奇葩主意

曝知名男星涉嫌逃兵役被捕 王大陆被带回侦办

美政府裁员引发抗议 改革浪潮争议不断
媒体批特朗普又一次“抢劫”台湾 美国的真实意图暴露
1月厦门维修进境飞机增两成 航空维修产业迎“开门红”

17岁小将黄振文首球即完美世界波 华裔新星闪耀澳超

宇树科技创始人王兴兴曾差点没考上高中 从内向少年到科技领军人物
俄美今日开谈谈什么?为何选在沙特?乌欧又在“焦虑”什么? 乌克兰问题成焦点

哪吒2出现错别字 光线传媒回应 将讨论并回复

哈马斯一名军事指挥官在黎南部遭以色列无人机袭击死亡 以军确认行动成功
陈晓陈妍希官宣离婚 感恩遇见各自安好

特朗普批波音:总统专机怎么还没造好 项目拖延引不满

大V:欧洲和乌克兰遭受三次沉重打击 西方暴露三大问题

特朗普上一任期让做的专机至今没好 项目拖延引不满
鹿晗关注了Sana的ins 粉丝热议不断

外媒:以色列内阁投票确认扎米尔为下任以军总参谋长 即将于3月5日就职

洛杉矶街头出现科比东契奇巨幅壁画 湖人诚意打动东契奇
下赛季全明星周末或将引入单挑赛 巨星积极响应

曾被雷军千万年薪挖角!亲属称罗福莉与丈夫研究领域相同

今年雨水不一般,60年一遇,有3大特点,4大特殊

CTA与皇马代表谈判罚等议题 友好氛围中进行会谈
相关新闻
科技巨头开始“卷”AI智能体 大模型已达上限
尽管像ChatGPT这样的大语言模型一直是AI新闻的焦点,但人们开始意识到它们的局限性。OpenAI表示其旗舰GPT模型的改进速度正在放缓,这引发了对未来发展方向的疑问
2024-11-26 11:17:00科技巨头开始“卷”AI智能体多个平台宣布上线DeepSeek大模型 多家科技巨头纷纷跟进
近日,百度智能云、华为云、阿里云、腾讯云、360数字安全、云轴科技等多个平台宣布上线DeepSeek大模型。用户可以在各大平台上调用DeepSeek-R1和DeepSeek-V3等模型
2025-02-05 10:02:29多个平台宣布上线DeepSeek大模型谷歌25亿美元买下Character.AI 大模型竞争加剧,创业公司归拢巨头麾下
2024-08-05 20:14:01谷歌25亿美元买下Character.AIDeepSeek登顶苹果美区免费下载榜 国产大模型崛起
1月27日,DeepSeek应用登顶苹果美国地区应用商店免费APP下载排行榜,超越了ChatGPT。同一天,该应用也在中国区苹果应用商店的免费榜上位列第一
2025-01-27 09:12:14DeepSeek登顶苹果美区免费下载榜450亿欧舒丹正式退市 美妆巨头私有化落幕
2024-09-13 16:38:24450亿欧舒丹正式退市枪杀美巨头高管嫌犯是高材生 常青藤名校背景
2024-12-11 09:11:05枪杀美巨头高管嫌犯是高材生







