关于DeepSeek 马斯克评论了两条帖子 AI将无处不在

马斯克评论称:“有趣的分析。我所见过的最好的。”“AI 将无处不在。”
关于 DeepSeek r1 的真相与细节,该应用在相关 App Store 类别中下载量排名第一,领先于 ChatGPT,并且超过了 Gemini 和 Claude 的表现。从质量角度看,它与 o1 相当,但不及 o3。r1 实现了真正的算法突破,在训练和推理方面都显著提高了效率。FP8 训练、MLA 和多 token 预测都有重要意义。尽管其训练成本仅为 600 万美元,但这数字可能具有误导性。即使硬件架构新颖,值得注意的是他们使用 PCI-Express 进行扩展。
根据技术论文,600 万美元并不包括前期研究和架构、算法及数据消融实验的成本。这意味着只有在实验室已经在前期研究上投入数亿美元并且能够访问更大规模集群的情况下,才能以 600 万美元的成本训练出 r1 质量的模型。DeepSeek 显然拥有远超 2048 个 H800 的算力;早期的一篇论文提到拥有 10000 个 A100 的集群。一个同样聪明的团队不可能仅凭 600 万美元就能启动 2000 个 GPU 集群并从头开始训练 r1。大约 20% 的 Nvidia 收入来自新加坡,但 20% 的 Nvidia GPU 可能并不在新加坡。存在大量的知识蒸馏,如果没有对 GPT-4o 和 o1 的无障碍访问,他们可能无法完成这个训练。限制前沿 GPU 的访问权限却不对中国蒸馏美国前沿模型的能力采取任何措施,这显然违背了出口限制的目的。
DeepSeek r1 确实具有重要意义,尤其在推理成本上比 o1 低得多且效率更高,这比 600 万美元的训练成本更具意义。r1 的每次 API 调用成本比 o1 低 93%,可以在高端工作站上本地运行,而且似乎没有遇到任何速率限制。简单计算一下,每 10 亿个活跃参数在 FP8 下需要 1GB 的 RAM,因此 r1 需要 37GB 的 RAM。批处理大大降低了成本,更多的计算能力增加了每秒 token 数,所以云端推理仍然具有优势。这里还存在真正的地缘政治动态,“Stargate”之后发布并非巧合。

乌方将不承认美俄谈判达成的协议 泽连斯基坚决立场
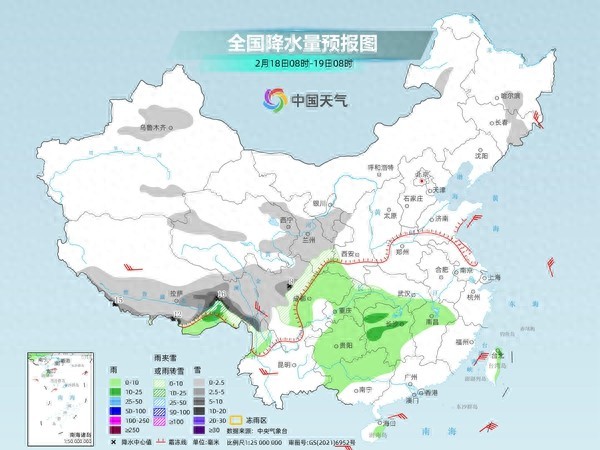
未来三天南方阴雨湿冷感明显 北方降水增多

武汉一培训机构请千名学生看哪吒2 放松身心缓解压力

以民众持续抗议要求政府维持停火 呼吁释放被扣押人员

伊朗:反对外国势力干涉叙利亚 支持叙人民自决权

章昊直播时模仿徐冬冬姿势

三亚招募100名旅游体验官 提升服务质量与游客满意度

大V:欧洲和乌克兰遭受三次沉重打击 西方暴露三大问题
武汉一培训机构请千名学生看哪吒2 放松身心缓解压力
乌方将不承认美俄谈判达成的协议 泽连斯基坚决立场

泽连斯基将到访沙特 不参与美俄会谈
未来三天南方阴雨湿冷感明显 北方降水增多
马斯克坐实AI游戏工作室计划 让游戏再次伟大

网红高收入合理吗?顾茜茜称每天躺赚30万是气话
媒体批特朗普又一次“抢劫”台湾 美国的真实意图暴露
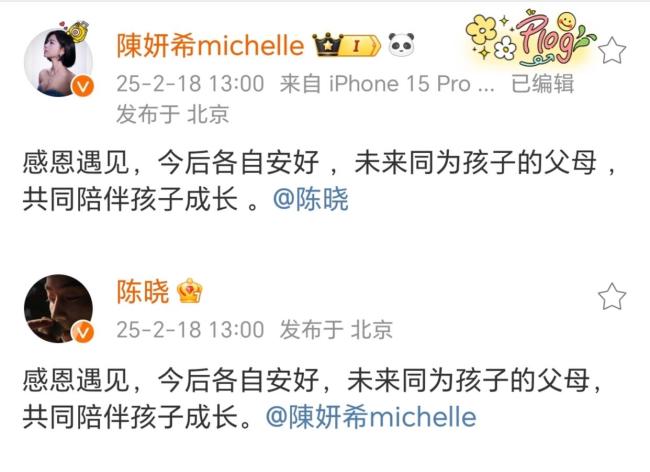
陈晓陈妍希 今后各自安好 感恩遇见共伴成长
光线传媒再度巨震 高位人气股走弱

特朗普批波音总统专机还没造好 项目拖延引不满
安徽一车坠河4人遇难 事故仍在调查处理中

曾被雷军千万年薪挖角!亲属称罗福莉与丈夫研究领域相同

欧洲的安全,还是美国的利益?美俄谈判前夕,欧洲被边缘化引发担忧

美国翻脸后,欧洲从“夸夸其谈的少年”走向独立成熟要做三件事 应对三大危机

波兰外长:在黄油和枪炮间很难选择 欧洲需加强国防开支

赖志光任广东惠州公安局局长 新任副市长兼公安局长
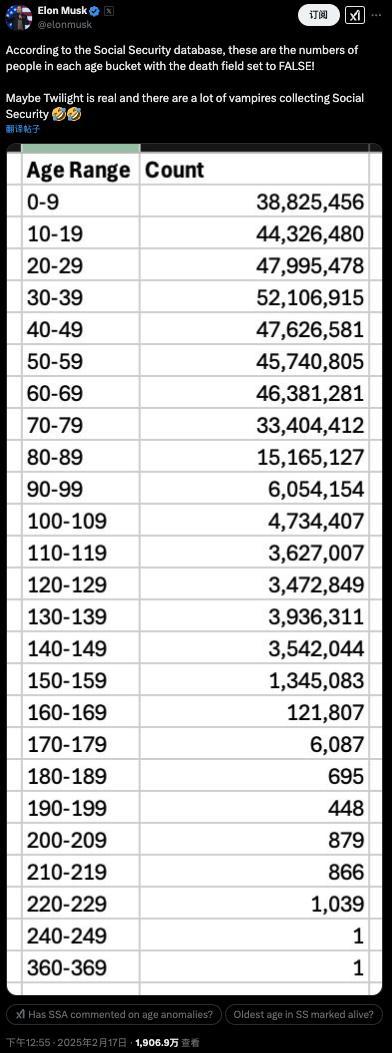
马斯克查账“美国社保”,称发现360岁老人?

美为何提议从中国向乌派遣维和人员 美国的奇葩主意

网曝河北邢台一局长酒后砸店伤人 当地纪委介入调查

美国新版“空军一号”再度延期交付 供应链问题拖累进度

哪吒2主创团队已进入新创作周期 续写神话新篇章

暴雪《守望先锋》国服明日回归!中国主题四大天王皮肤来了 国服专属福利揭晓

申公豹的结巴能矫正吗 口吃并非无法改善

为了增加军费,英国公共服务部门被曝准备削减11%的预算,欧洲派兵计划陷入僵局
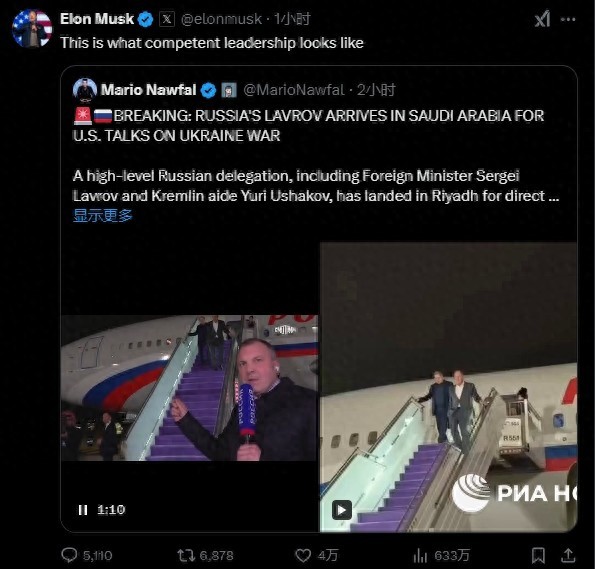
美俄谈判今日开始 泽连斯基:不承认 乌克兰缺席引发争议

拉夫罗夫抵达沙特 单手揣兜下飞机 谈判桌上的博弈

美客机翻覆现场视频曝光 恶劣天气或成事故主因
相关新闻
马斯克谈DeepSeek xAI即将发布更强模型
2025-02-09 22:13:58马斯克谈DeepSeek杨华评论:关于中国足球的集体反思都是盲人摸象
2024-09-14 15:36:57杨华评论:关于中国足球的集体反思都是盲人摸象马斯克评论中国机器狗产品 未来战争新趋势
近日,中国机器人创业公司宇树科技发布了最新机器狗产品B2-W的演示视频,引起了全球关注。许多国外网友表示被中国的科技实力震撼
2024-12-29 13:21:43马斯克评论中国机器狗产品OpenAI前研究员自杀 马斯克评论 引发行业震动
2024-12-14 18:46:24OpenAI前研究员自杀马斯克评论马斯克为何成DeepSeek“头号黑粉” 小力出奇迹的挑战者
马斯克的“仇人”名单上最近新增了中国AI创业公司DeepSeek。过去一个月,这家以少量资源开发出顶级性能R1开源大模型的公司持续受到全球关注
2025-01-31 13:48:55马斯克为何成DeepSeek头号黑粉马斯克评论美国24年来最严重空难 质疑FAA雇佣政策
当地时间周三晚,一架美国航空公司的支线飞机与一架美国陆军的黑鹰直升机在华盛顿特区上空相撞,导致客机上的64人和直升机上的3名军人全部遇难。这是自2001年11月以来美国发生的最严重的空难
2025-01-31 13:46:59马斯克评论美国24年来最严重空难







