DeepSeek 小力出奇迹 低成本高性能引发关注

在人工智能领域,一场激烈的竞争正在上演。去年12月,国内大模型公司“深度求索”开发的DeepSeek应用推出了DeepSeek-V3,在全球AI领域引起了巨大反响。这款模型以极低的训练成本实现了与GPT-4等顶尖模型相媲美的性能,震惊了业界。不到一个月后,DeepSeek再次震动全球AI圈。
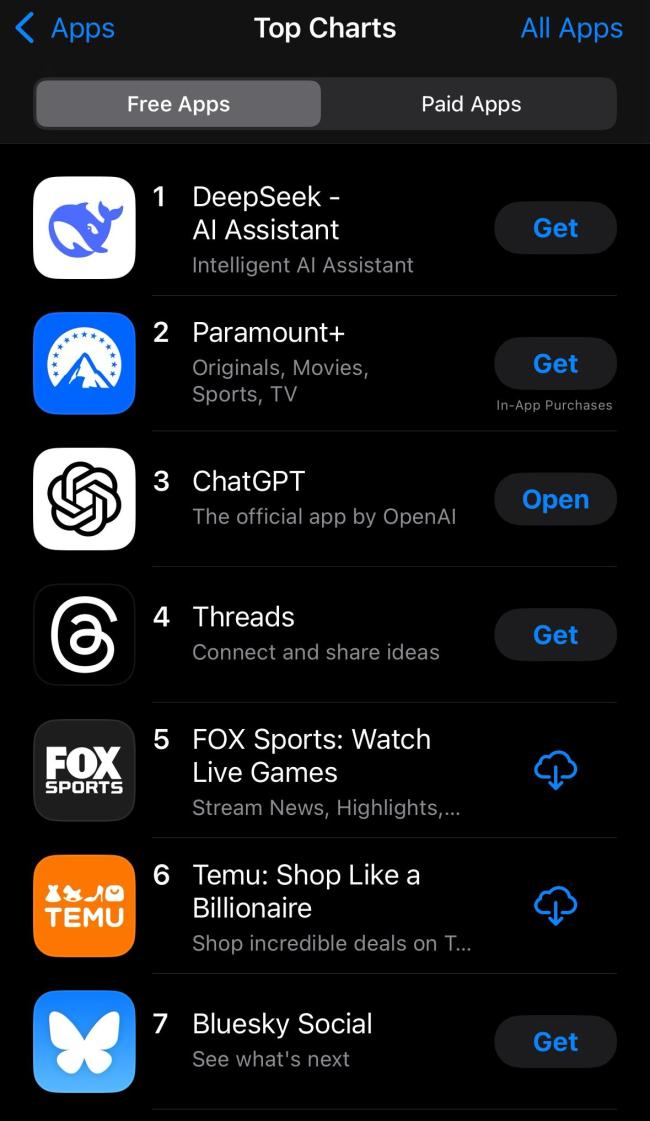
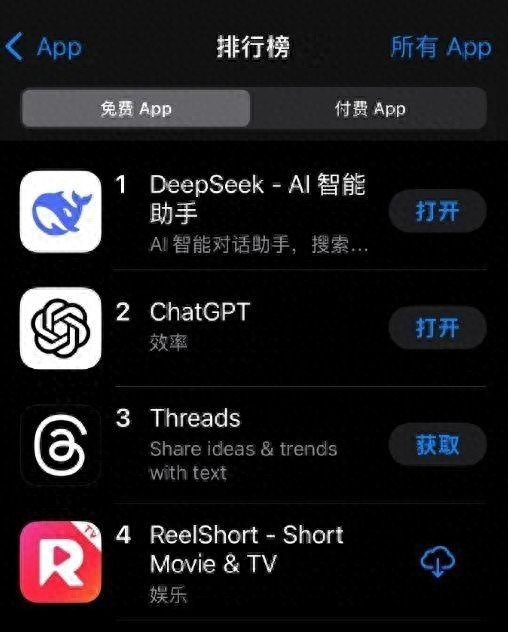
随着新模型DeepSeek-R1的推出,1月27日,Deepseek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,并在美国区超越了ChatGPT。这一消息不仅在AI圈内引起了轩然大波,也让广大用户对这款新兴应用产生了浓厚兴趣。DeepSeek究竟好在哪?为什么能以较低的成本取得显著效果?开源是不是大模型未来的发展方向?
DeepSeek是一款由国内人工智能公司研发的大型语言模型,它拥有强大的自然语言处理能力,能够理解并回答用户的问题,就像和朋友聊天一样自然流畅。此外,DeepSeek还能帮助用户写代码、整理资料,甚至解决复杂的数学问题。它背后有复杂的算法和大量数据支持,能够从海量信息中挖掘出用户所需的内容。

说到类似的大模型,人们通常会想到OpenAI开发的ChatGPT。从2024年9月OpenAI发布o1-preview到现在,市场上已经出现了许多媲美甚至超越其性能的推理模型。然而,DeepSeek之所以能够脱颖而出,是因为它不仅率先实现了媲美OpenAI-o1模型的效果,还将推理模型的成本压缩到了极低。
关闭

点映能拯救《蛟龙行动》吗?春节档逆袭难度大
点映能拯救蛟龙行动吗2025-01-28 21:49:48

被岳云鹏的《五瓦》狠狠共情了 唤起深藏的记忆
被岳云鹏的五瓦狠狠共情了2025-01-28 21:49:16

春晚第一个镜头给了李子柒 惊艳亮相成亮点
春晚第一个镜头给了李子柒2025-01-28 21:47:01

中国人过年指南 春节习俗全解析
中国人过年指南2025-01-28 20:18:46
DeepSeek回应超越ChatGPT 市场热情与挑战并存
DeepSeek回应超越ChatGPT2025-01-28 20:09:27

扎克伯格:AI方面我们需要政府帮助 探讨科技未来与竞争态势
扎克伯格,AI方面我们需要政府帮助2025-01-27 08:49:39

春晚无锡分会场亮点满满 水乡特色尽显
春晚无锡分会场亮点满满2025-01-28 20:05:01

美媒:美国援助冻结令对抗不了中俄 致命且无益
美媒,美国援助冻结令对抗不了中俄2025-01-28 21:17:07

陈哲远骨折 热搜爆了引发关注
陈哲远骨折2025-01-28 21:46:35

俄称在乌阵地发现几具被锁士兵遗体 有遭受酷刑痕迹
俄称在乌阵地发现几具被锁士兵遗体2025-01-26 17:32:14
特朗普总统又反悔了?但这次是好事,中美贸易战2.0可能不打了 金融市场迎来利好
特朗普总统又反悔了,但这次是好事,中美贸易战2,0可能不打了2025-01-27 08:47:58

专家谈乌军失守大诺沃西尔卡 俄军三面包围成功
专家谈乌军失守大诺沃西尔卡2025-01-27 21:15:42

马斯克的政府效率部诞生一周干了啥 首周削减4.2亿美元预算
马斯克的政府效率部诞生一周干了啥2025-01-27 08:26:52
被岳云鹏的《五瓦》狠狠共情了 唤起深藏的记忆
被岳云鹏的五瓦狠狠共情了2025-01-28 21:49:16

上海为入境游客准备文化大餐 迎首个非遗版春节
上海为入境游客准备文化大餐2025-01-28 20:02:03
春晚第一个镜头给了李子柒 惊艳亮相成亮点
春晚第一个镜头给了李子柒2025-01-28 21:47:01

菲律宾在南海能掀得起浪吗 小人使坏徒劳无功
菲律宾在南海能掀得起浪吗2025-01-27 08:30:49

春节迎买金潮 商家叹不如去年 小克重金饰受青睐
春节迎买金潮商家叹不如去年2025-01-28 20:31:17

实战画面揭示2000磅炸弹真实威力 十层高楼4秒钟化为废墟
实战画面揭示2000磅炸弹真实威力2025-01-26 11:44:36

美印第安纳州总检察长起诉当地警长 拒配合移民执法
美印第安纳州总检察长起诉当地警长2025-01-27 08:28:05

观众建议岳云鹏别上春晚了 相声依旧好笑
观众建议岳云鹏别上春晚了2025-01-28 21:29:34

央视春晚倒计时 亮点纷呈迎新春
央视春晚倒计时2025-01-28 19:58:33

专家谈欧盟计划在格陵兰岛驻军 地缘政治新焦点
专家谈欧盟计划在格陵兰岛驻军2025-01-27 08:31:06

年轻人如何缓解过年焦虑 面对家庭压力的建议
年轻人如何缓解过年焦虑2025-01-28 20:42:39

第9艘055大驱将首航 解放军海军东海南海实战演训 强化临战演练
第9艘055大驱将首航 解放军海军东海南海实战演训 强化临战演练2025-01-26 15:43:28

余承东:家里的旧车都被我淘汰了 换上鸿蒙智行享界S9
余承东,家里的旧车都被我淘汰了2025-01-28 20:57:47

回家的路 就是最美的风景 温暖归途心
回家的路就是最美的风景2025-01-28 21:25:04

美国无人机为啥这么贵 高昂成本引发质疑
美国无人机为啥这么贵2025-01-27 08:26:20

特朗普的“星际之门”计划会失败吗 马斯克公开质疑
特朗普的星际之门计划会失败吗2025-01-27 08:28:23

尹锡悦会被判处死刑吗 涉嫌“内乱头目”罪名成立?
尹锡悦会被判处死刑吗2025-01-27 08:30:30

聂卫平:韩国棋院的道歉避重就轻 呼吁处理不当裁判
聂卫平,韩国棋院的道歉避重就轻2025-01-28 21:01:34
点映能拯救《蛟龙行动》吗?春节档逆袭难度大
点映能拯救蛟龙行动吗2025-01-28 21:49:48

学者:鲁比奥把火烧向泽连斯基,暂时冻结对乌克兰的援助
学者:鲁比奥把火烧向泽连斯基2025-01-27 16:14:44

民进党为何不遗余力地推进大罢免 手段卑劣引发争议
民进党为何不遗余力地推进大罢免2025-01-27 08:28:47
比特币和黄金又将重回历史新高,谁才是有力的战略储备? 美元走弱与政策推动共助涨势
比特币和黄金又将重回历史新高,谁才是有力的战略储备2025-01-27 08:49:11
相关新闻
DeepSeek掀起算力新范式 低成本训练引领变革
2025-01-27 19:43:28DeepSeek掀起算力新范式华尔街分析师:DeepSeek不是算力利空 效率提升或促需求增长
周一,全球股市因DeepSeek的出现而波动。这家公司打破了“只有大量资金才能发展AI”的传统观念,导致算力产业相关公司股价大幅下跌
2025-01-28 11:33:34华尔街分析师DeepSeek正在打破算力为王行业规则 引发AI算力股下挫
2025-01-27 22:03:32DeepSeek正在打破算力为王行业规则北京突然飘雪属于大力出奇迹
2024-11-27 14:33:02北京突然飘雪属于大力出奇迹实测DeepSeek做奥数题写作文 DeepSeek火爆全球
2025-01-27 20:13:31实测DeepSeek做奥数题写作文DeepSeek彻底爆发 性能卓越成本低
2025-01-26 15:56:02DeepSeek彻底爆发