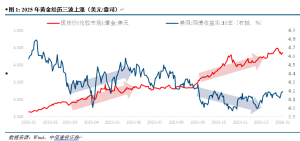
幻方DeepSeek如何“震惊”硅谷 性价比与开源的胜利

过去一周,中国的人工智能大模型成为硅谷乃至全球科技界的热议话题。引发这场讨论的是中国人工智能初创公司深度求索(DeepSeek)。该公司上周发布的推理大模型DeepSeek-R1因其性能可比肩OpenAI的o1、极低的服务价格以及代码和模型架构的完全开源而震惊业界。
多位知名科技人士对DeepSeek近期取得的成就表示赞叹。Scale AI创始人亚历山大·王称,美国可能在过去的十年里一直领先于中国,但DeepSeek的发布可能会“改变一切”。加州大学伯克利分校计算机科学教授伊恩·斯托伊卡表示,DeepSeek-R1只需花费训练GPT、Gemini和Claude等现有大模型的一小部分成本即可获得最先进的结果,并且在该校的大模型排行榜中排名第三。
这一成就在美国对华芯片出口管制加强的背景下实现。斯托伊卡认为,限制条件和资源匮乏往往会激发创新。
受到规模定律的影响,全球AI大模型开发长期以来陷入了一场关于顶尖人才、先进算力和巨额投资的竞争。各大科技公司大量囤积芯片以确保充足的算力。然而,当越来越多科学家开始质疑堆数据和堆算力的做法时,中国量化交易公司幻方量化旗下的人工智能初创公司DeepSeek横空出世,通过优化模型架构和基础设施等方式快速突进。
早在去年12月,该公司推出的DeepSeek-V3展现了极致性价比。从技术报告来看,该模型仅需2.788M H800 GPU小时,训练成本仅为557万美元,但其性能与GPT-4o和Claude Sonnet 3.5等顶尖模型相当。著名人工智能科学家卡帕西指出,这种级别的能力通常需要接近16000颗GPU的集群。
最新发布的DeepSeek-R1在服务价格上也具有明显优势。其API服务定价为每百万输入tokens 1元(缓存命中)/ 4元(缓存未命中),分别是OpenAI o1的2%和3.6%。外界普遍认为,美国尖端芯片出口管制并没有削弱中国的AI能力,反而推动了DeepSeek等初创公司以效率、资源池和协作的方式进行创新。

周深佩戴珠宝细节 舞台形象引热议
网传陈晓净身出户 十年情路终落幕
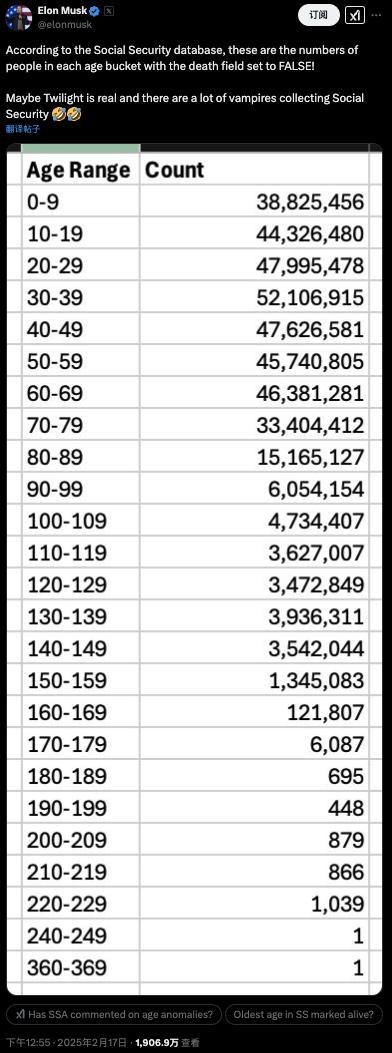
马斯克声称发现360岁老人 数据异常引争议

特朗普批波音总统专机还没造好 项目拖延引不满

“廿二做三事,不富也平安”,明日正月廿二 金佛下凡祈福日

12.4亿美元买“酒”!巴菲特,释放了什么信号? 加码消费股布局

恭喜!国乒24岁新星恋情曝光 甜蜜合影引关注

美客机翻覆现场视频曝光 恶劣天气或成事故主因

台北市议员:特朗普想要台积电的命 担忧核心技术外流

欧洲的安全,还是美国的利益?美俄谈判前夕,欧洲被边缘化引发担忧

俄代表:欧盟英国“完全不守信用” 质疑其未来协议参与资格

艺人王大陆因涉嫌逃兵役被逮捕,将送新北检

男子撞劳斯莱斯逃逸车损预估20多万
中国经济2025年第一份“体检报告”
马斯克坐实AI游戏工作室计划 让游戏再次伟大

当DeepSeek开始教人买房,中介的饭碗还端得住吗?
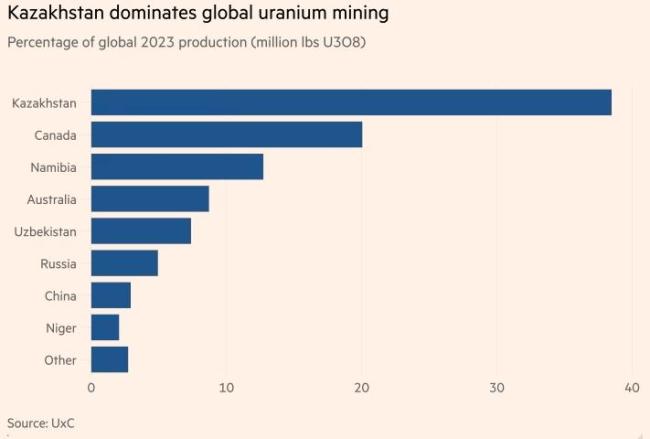
哈萨克斯坦铀出口重心东移 哈铀售中俄后致欧美快断供了
未参与美俄谈判 乌克兰被美抛弃了吗 乌方未受邀参会引发猜测
马斯克声称发现360岁老人 数据异常引争议

“最没含金量”的世界冠军,偷走了假赛主播的人生?

上海多地惊现南美“巨型老鼠” 生态危机引关注
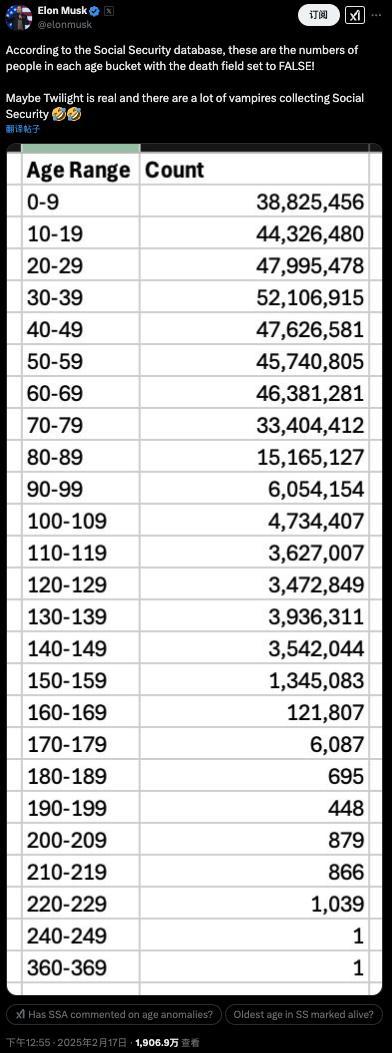
马斯克查账“美国社保”,称发现360岁老人?

美国新版“空军一号”再度延期交付 供应链问题拖累进度

韩国空姐打开应急舱门站机翼上自拍 争议举动惹众怒

美国翻脸后,欧洲从“夸夸其谈的少年”走向独立成熟要做三件事 应对三大危机
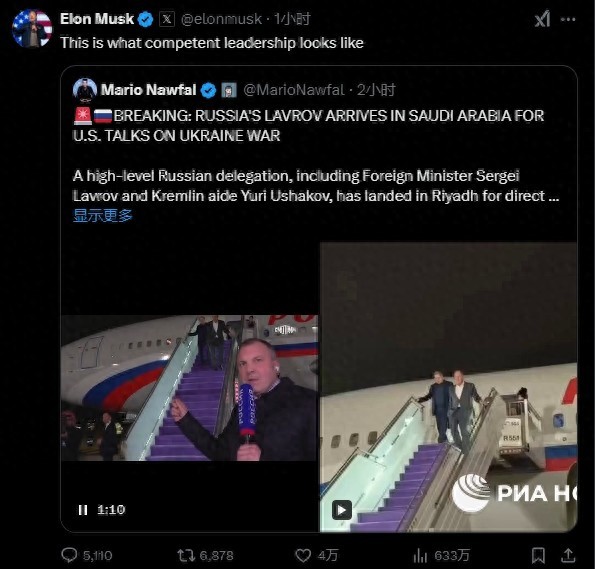
美俄谈判今日开始 泽连斯基:不承认 乌克兰缺席引发争议

中国导演20万美元拍出北美短剧第一 刷新票房纪录

伊朗:反对外国势力干涉叙利亚 支持叙人民自决权

“一二三四五......”司机见中草药包变10万现金惊住了

多名官员被解雇后起诉美政府 裁员争议升级
周深佩戴珠宝细节 舞台形象引热议
网传陈晓净身出户 十年情路终落幕

泽连斯基将到访沙特 不参与美俄会谈
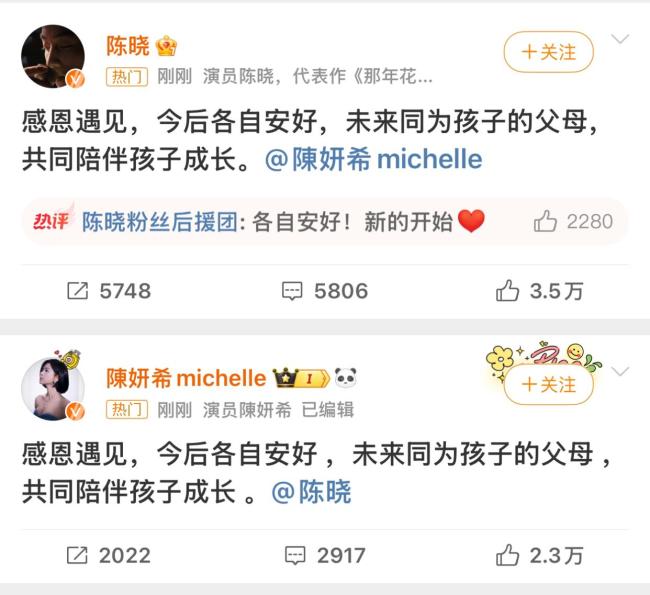
陈晓陈妍希情史回顾 九年婚姻终落幕

为了增加军费,英国公共服务部门被曝准备削减11%的预算,欧洲派兵计划陷入僵局
相关新闻
DeepSeek如何“震惊”硅谷 性能成本震撼巨头
2025-01-27 10:28:18DeepSeek如何震惊硅谷美媒:DeepSeek如何威胁美国主导地位 低成本高效率挑战硅谷
2025-01-27 10:50:53美媒从幻方到DeepSeek:梁文锋的“布施”与“布道”技术信仰与情怀
2025-01-30 10:09:50从幻方到DeepSeekDeepSeek大模型强在哪 引发硅谷恐慌
短短一个月内,中国AI初创公司深度求索(DeepSeek)发布了两款大模型:DeepSeek-V3和DeepSeek-R1
2025-01-27 08:21:32DeepSeek大模型强在哪DeepSeek美股泡沫得以延续 挑战硅谷霸权
白头鹰再次针对一家小公司采取行动,使用的依旧是那些熟悉的手段。近期,一家初创公司推出的DeepSeek软件在全球范围内引起轰动,在160多个国家的AI软件下载排行榜上位居榜首
2025-02-04 19:33:47DeepSeek美股泡沫得以延续DeepSeek让Meta深陷恐慌 中国AI逆袭硅谷
短短一个月内,中国AI初创公司深度求索(DeepSeek)发布了两款大模型——DeepSeek-V3和DeepSeek-R1
2025-01-26 10:34:01DeepSeek让Meta深陷恐慌