天才创始人对谈AI教父Hinton:多模态是AI的未来,医疗将发挥AI最大的潜力

5月17日消息,AI教父Geoffrey Hinton接受访谈。对谈不仅涉及Hinton对大型神经网络、多模态学习、模拟计算、AI安全等技术发展的看法,还有其接触人工智能的经历以及与Ilya初识的回忆。
访谈的提问者是一名天才创业者——Joel Hellermark。
Joel Hellermark
Joel是Sana AI的创始人兼首席执行官,Sana是一家领先的人工智能公司,已从NEA、Menlo和EQT筹集了超过8000万美元的融资。他在13岁时自学编程,16岁时创立了自己的第一家公司,开发了一个视频推荐引擎。
官网截图
对谈要点整理如下:
初识Ilya时就觉得十分优秀,Ilya很早就预测过Scaling Law是存在的。
下一个token预测能有效解释大脑的学习机制,模型在学习过程中可以习得推理能力。
类比是创造力的源泉,而模型能挖掘事物之间的共有结构,找到人类不曾注意的类比,进而超越训练数据。
多模态能让模型更好理解学习,并且能让模型的空间推理能力更强,一定是提升AI能力的重要方向。
医疗将是AI应用的最重要领域之一,AI的发展无法阻挡。
Ilya是完美的研究伙伴,他的直觉非常灵敏
Hinton:我想起当时从英格兰第一次来到卡内基梅隆大学。是在英格兰的研究部门,下午6点后一般都会去酒吧喝酒。但我来了几周后的一个周六晚上,一个朋友都没有,也不知道能做什么。我实验室有要用的机器机,但家里没有,所以决定去实验室编程。
于是我在周六晚上9点左右来到实验室,所有的学生都在那里,挤满了人。他们都在那里。他们都相信自己在研究未来,接下来做的事情,将改变计算机科学的发展,这与英格兰的情况完全不同。所以这令我耳目一新。
主持人:带我回到最初在剑桥探索脑科学的日子。那时候什么感觉?
Hinton:说实话,很失望。我学的生理学,夏季学期教大脑的工作方式,结果只教了神经元如何传导动作电位。确实有趣,但并没有说明白大脑究竟如何工作,所以我比较失望。我后面转去学哲学,希望能学到思维是如何运作的。但同样失望。
我最后去爱丁堡大学学习人工智能,那更有趣。至少可以进行模拟,可以测试理论。
主持人:还记得开始是对人工智能的哪些方面感兴趣吗?有没有特定的一篇论文或者科学家,让你发现了有意思的点子。
Hinton:唐纳德·赫布的一本书对我影响颇深。他对如何学习神经网络中的连接强度非常感兴趣。我还读过约翰·冯·诺伊曼的一本书,关注大脑如何计算、大脑计算方式与普通计算机的差异。
主持人:你在爱丁堡的时候,觉得这些接触到的想法以后会有用吗?你那时候的直觉是怎样的?
Hinton:在我看来,我们需要遵循大脑本身的学习方法。显然,大脑不可能将所有东西先编程,然后使用逻辑推理,这从一开始就显得不太对。所以必须弄清楚,大脑是如何学习调整神经网络中的连接,去处理复杂任务。冯·诺伊曼和图灵都相信这一点,他们都非常擅长逻辑,但他们不相信这种逻辑方法。
主持人:学习神经科学,仅仅做人工智能里的算法,你在二者之间如何分配精力的?你在早期受到了多少启发?
Hinton:我对神经科学研究不多,主要受到的启发来自大脑的工作方式。大脑有一大堆神经元,执行相对简单的操作,工作又是非线性的,但它们能接收输入,进行加权,然后在此基础上输出。问题是,到底如何改变权重使整个系统做一些厉害的事?这个问题看上去相当简单。
主持人:那个时候,你和谁有合作?
Hinton:我在卡内基梅隆大学做研究,但主要合作者并不是卡内基梅隆大学的。我与特伦斯·谢诺夫斯基(注:他与杰弗里·辛顿共同发明了玻尔兹曼机)往来比较多。他在巴尔的摩的约翰霍普金斯大学。应该是每个月一次,要么他开车来匹兹堡,要么我开去巴尔的摩,距离是250英里。我们会用周末时间研究玻尔兹曼机。合作非常愉快,我们都相信这是大脑的工作方式,这是我做过的最令人兴奋的研究。也许有很多成果也很棒,但我认为那不是大脑的工作方式。
我还与彼得·布朗有很好的合作,他是优秀的统计学家,IBM从事语音识别工作。所以,到卡内基梅隆大学攻读博士学位时,他作为学生已经很成熟,已经知道很多。他教了我很多关于语音的知识。事实上,他教了我关于隐马尔可夫模型的知识。这就是我理想的学生:从他那里学到的,比我教他的还多。他教我隐马尔可夫模型时,我正在使用带有隐藏层的反向传播。那时候还不叫隐藏层,但我决定使用马尔可夫模型中的命名方式,这个叫法能很好地表示究竟在做什么的变量。总之,这就是神经网络中隐藏一词的来源。
主持人:谈谈Ilya出现在你办公室的时候吧。
Hinton:那时候我在办公室,应该是个周日,我在编程,然后有人敲门。敲门声很急促,和一般敲门不太一样。我开门发现是一个年轻的学生。他说整个夏天他都在炸薯条,但他更愿意在我的实验室工作。所以我说,约个时间来聊聊?然后他说,不如就现在?Ilya就是这样的人。于是我们聊了下,我给他一篇文章读,是关于反向传播的Nature期刊论文。
我们约定一周后再次见面,他回来了,他说他不太明白。我挺失望的,本来看起来蛮聪明。这只是链式法则,理解它并不难。他说:不,我理解链式法则,我只是不理解,为什么你不把梯度赋予一个合理的函数优化器。好家伙,他提出的问题让我们思考了好几年。他总是是这样,对问题的直觉非常好,总是能提出好的想法。
主持人:Ilya为什么有这种直觉?
Hinton:我不知道。或许他总是独立思考,很小就对人工智能感兴趣。他也很擅长数学。但我不知道为什么他直觉那么准。
主持人:你和他之间,合作分工是怎样的?
Hinton:真是很有趣。记得有一次,我们试着用数据制作复杂的地图,用的是一种混合模型,所以你可以使用相似性来制作两张地图,使得在一张地图上,河岸可以靠近绿地,而在另一张地图上,河岸可以靠近河流。因为在一张地图上,你不能让它同时靠近两者,河流和绿地相距很远。所以有了混合地图,我们在MATLAB中进行操作,这涉及到对代码进行大量重组,进行正确的矩阵乘法。
然后他就做得烦了。有一天他来找我说,我要为MATLAB编写一个交互界面,就可以用另一种语言编程,然后把它转换成MATLAB。我说,不,Ilya,那将花费你一个月的时间。这个项目要继续,不能被那个分散注意力。Ilya说,没关系,我早上就做好了。
主持人:简直不可思议!这些年来,最大的变化不仅仅体现在算法,还有规模。你如何看待?
Hinton:Ilya很早就看到这点,总是说,规模更大,表现更好。我之前总觉得站不住脚,新的想法还是需要的。但事实证明,他的判断基本上是正确的。像Transformers这样的算法确实很有用,但真正起作用的,是数据和计算的规模。当时想象不到计算机会快上数十亿倍,觉得快上一百倍了不得了,于是试着提出巧妙的想法来解决问题。然而,有更大的数据和计算规模,很多问题就迎刃而解了。
大约在2011年,Ilya和另一个叫James Martins的研究生与我合作,写了一篇关于字符级预测的论文。使用维基百科,并试图预测下一个HTML字符。用的是GPU上的一个很好的优化器,效果出乎意料的好。我们从未真正相信它理解了任何东西,但它看起来又好像理解了,这似乎让人难以相信。
神经网络不仅仅是记住训练数据,而是在“理解”,推理能力的提高指日可待
主持人:能解释一下模型如何预测下一个单词,以及这样认识他们为何是错误的?
Hinton:好吧,我其实觉得这不算错。
事实上,我认为我制作了第一个使用嵌入和反向传播的神经网络语言模型。数据非常简单,只是三元组,将每个符号(Symbol)转换为一个嵌入(embedding),然后让嵌入相互作用以预测下一个符号的嵌入,然后从该嵌入中预测下一个符号,然后通过整个过程反向传播以学习这些三元组。大约10年后,Yoshua Bengio(图灵奖得主)使用非常相似的网络,展示了它在真实文本上的效果。大约10年后,语言学家开始相信嵌入。这有一个发展的过程。
我认为它不仅仅是预测下一个符号。
问一个问题,答案第一个单词是下一个符号,那就必须理解这个问题。大多数人认为的“自动填充”则是,看到不同的单词出现在第三位的频率,这样就可以预测下一个符号。但其实不是这样。
为了预测下一个符号,必须理解正在说什么。我们是通过让它预测下一个符号,迫使它理解。很多人说,它们不像人类那样推理,只是在预测下一个符号。但我认为,它的理解方式像我们一样。为了预测下一个符号,它必须进行一些推理。现在已经看到,你制作一个大的模型,不添加任何特殊的推理内容,它们也已经可以进行一些推理。规模越大,它们未来能进行的推理也更多。
主持人:现在除了预测下一个符号外,还做了其他什么吗?
Hinton:这就是学习的方式。不管是预测下一个视频帧,还是预测下一个声音。我觉得这就是解释大脑学习的十分合理的理论。
主持人:为什么这些模型能够学习如此广泛的领域?
Hinton:大语言模型所做的,是寻找事物之间共同的结构。基于共同结构对事物进行编码,这样一来效率很高。
举个例子。问GPT-4,为什么堆肥堆像原子弹?大多数人都无法回答这个问题,觉得原子弹和堆肥堆是非常不同的东西。但GPT-4会告诉你,尽管能量、时间尺度不同,但相同的是,堆肥堆变热时会更快地产生热量;原子弹产生更多的中子时,产生中子的速度也会随之加快。这就引出了链式反应的概念。通过这种理解,所有的信息都被压缩到它自己的权重中。
这样一来,它将能处理人类尚未见过的数百种类比,这些看似不相关的类比,正是创造力的源泉。我想,GPT-4变得更大时,创造力将非常高。如果只是觉得,它只在反刍学过的知识,只是将它已经学过的文本拼凑在一起,那就小看它的创造力了。
主持人:你可能会说,它会超越人类的认知。尽管我们看到了一些例子,但貌似尚未真正见到你说的这点。很大程度上,我们仍然处于当前的科学水平。你认为什么能让它开始有所超越呢?
Hinton:我觉得在特定情况中已经看到这点了。以AlphaGo为例。与李世石的那场著名比赛中,AlphaGo的第37步,所有专家看来都觉得是错棋,但后来他们意识到这又是一步妙棋。
这已经是在那个有限的领域内,颇具创造力的动作。随着模型规模增加,这样的例子会更多的。
主持人:AlphaGo的不同之处在于,它使用了强化学习,能够超越当前状态。它从模仿学习开始,观察人类如何在棋盘上博弈,然后通过自我对弈,最终有所超越。你认为这是当前数据实验室缺少的吗?
Hinton:我认为这很可能有所缺失。AlphaGo和AlphaZero的自我对弈,是它能够做出这些创造性举动的重要原因。但这不是完全必要的。
很久以前我做过一个小实验,训练神经网络识别手写数字。给它训练数据,一半的答案是错误的。它能学得多好?你把一半的答案弄错一次,然后保持这种状态。所以,它不能通过只看同一个例子来把错误率平均。有时答案正确,有时答案错误,训练数据的误差为50%。
但是你训练反向传播,误差会降到5%或更低。换句话说,从标记不良的数据中,它可以得到更好的结果。它可以看到训练数据是错误的。
聪明的学生能比他们的导师更聪明。即使接收了导师传授的所有内容,但他们能取其精华去其糟粕,最终比导师更聪明。因此,这些大型神经网络,其实具有超越训练数据的能力,大多数人没有意识到。
主持人:这些模型能够获得推理能力吗?一种可能的方法是,在这些模型之上添加某种启发式方法。目前,许多研究都在尝试这种,即将一个思维链的推理反馈到模型自身中。另一种可能的方法是,在模型本身中增加参数规模。你对此有何看法?
Hinton:我的直觉告诉我,模型规模扩大后,推理能力也能提升。
人们如何工作?大致来说,人类有直觉进行推理,再用推理来纠正我们的直觉。当然,在推理过程中也会使用直觉。假设推理的结论与直觉冲突,我们就会意识到需要纠正直觉。
这与AlphaGo或AlphaZero的工作方式类似,它们有一个评估函数,只需看一眼棋盘,然后判断“这对我来说有多好?”但是,进行蒙特卡罗推演时,你会得到一个更准确的想法,你可以修改你的评估函数。因此,通过让模型接受推理的结果,来对模型进行训练。
大语言模型必须开始这样做,必须开始通过推理,来训练模型的直觉,知道下一步做什么,并意识到什么是不对的。这样,他们就可以获得更多的训练数据,而不仅仅是模仿人类。这正是AlphaGo能够做出第37步妙棋的原因,它拥有更多的训练数据,因为它使用推理来检查下一步应该是什么。
多模态让模型学习更加容易,同时利于空间推理
主持人:你对多模态有何看法?我们谈到了这些类比,而这些类比往往远远超出了我们所能看到的范围。模型发现的类比远远超出了人类的能力,可能是在我们永远无法理解的抽象层面上。现在,当我们将图像、视频和声音引入其中时,你认为这会如何改变模型?你认为它将如何改变,它能够进行的类比?
Hinton:这将带来很大的改变。例如,它将使模型更好地理解空间事物。仅从语言角度来看,很难理解一些空间事物。尽管值得注意的是,即使在成为多模态之前,GPT-4也能做到这一点。但是,当你让模型成为多模态时,如果你让它既能做视觉,又能伸手抓东西,它能拿起物体并翻转它们等等,它就会更好地理解物体。因此,虽然可以从语言中学到很多东西,但如果是多模态,学习起来会更容易。事实上,需要的语言更少。
多模态模型显然会占据主导地位。你可以通过这种方式获得更多数据,它们需要的语言会更少。当然,可以仅从语言中学习出一个非常好的模型,但从多模态系统中学习要容易得多。
主持人:你认为这将如何影响模型的推理能力?
Hinton:我认为它将使空间推理变得更好,例如,实际尝试捡起物体,会得到各种有用的训练数据。
主持人:你认为人类大脑的进化服务于语言,还是说语言的进步是服务于人类大脑?
Hinton:这是一个非常好的问题,我认为两者是共存的。我曾经认为,可以完全不需要语言去进行大量的认知活动,但现在我的想法有所改变。
那么,我将给出三种不同的语言观点以及它们与认知的关系。
一种观点是陈旧的符号观点,即认知包括使用某种经过清理的逻辑语言中的符号串,这些语言没有歧义,并应用推理规则。这就是认知——只是对语言符号串之类的事物进行符号操作。这是一种极端观点。
另一种极端观点是,一旦你进入头脑,它就全是向量。符号进来了,把这些符号转换成大向量,所有内容都是用大向量完成的,然后想产生输出,又会生成符号。2014年左右,机器翻译中有一个说法,当时人们使用循环神经网络,单词会不断进入,它们会有一个隐藏状态,它们会在这个隐藏状态下不断积累信息。因此,当它们读完一个句子时,它们会得到一个大的隐藏向量,它捕捉到了该句子的含义,然后可以用来生成另一种语言的句子。这被称为思维向量。这是对语言的第二种看法——将语言转换成一个与语言完全不同的大向量,这就是认知的全部内容。
第三种观点,也是我现在所相信的,即你采用这些符号,将符号转换成嵌入,并使用多层嵌入,这样你就得到了这些非常丰富的嵌入。但是嵌入仍然与符号相关联,从某种意义上说,你有一个用于这个符号的大向量,以及一个用于那个符号的大向量。这些向量相互作用,产生下一个单词的符号的向量。这就是理解的本质——知道如何将符号转换成这些向量,并知道向量的元素应该如何相互作用,从而预测下一个符号的向量。无论是在这些大型语言模型中,还是在我们的大脑中,理解就是这样进行的。这是一个介于两者之间的例子。你继续使用符号,但将它们解释为这些大向量,这就是所有工作所在。所有的知识都在于你使用的向量以及这些向量的元素如何相互作用,而不是符号规则。
这并不是说,能完全摆脱符号。而是将符号变成大向量,保留符号的表面结构。这就是这些模型的工作方式。在我看来,这也是人类思维比较合理的模型。
借助共享权重,数字系统的思维迁移十分高效
主持人:您是最早想到使用GPU的人之一,我知道Jensen(黄仁勋)很喜欢你。2009年你就告诉Jensen,这可能是训练神经网络的一个绝佳办法。当初要使用图形处理单元(GPU)训练神经网络,您是怎么想的?
Hinton:记得在2006年,我有位研究生,是十分优秀的计算机视觉专家。一次会议上,他建议我考虑使用图形处理卡(GPU),因为它们在矩阵乘法方面表现出色,我所做的基本上都是矩阵乘法。我考虑了下,然后我们开始研究配备四个GPU的Tesla系统。
我们一开始只是购买了游戏用的GPU,发现它们将运算速度提高了30倍。然后又买了一个配备四个GPU的Tesla系统,并在此基础上进行了一次公开汇报,效果非常好。2009年,我在NIPS会议上发表了演讲,告诉在场的一千名机器学习研究人员:你们都应该去购买NVIDIA的GPU,它们是未来,你们需要GPU进行机器学习。
我还给NVIDIA发了一封邮件,说我已经动员一千名机器学习研究人员去购买你们的卡,你们能不能送我一个?他们并没有回复。但后来把这个故事告诉Jensen时,他免费给了我一个(要显卡,得直接找老板谈)。
主持人:人工智能发展过程中,GPU其实也在发展。在计算领域,我们路在何方?
Hinton:我在谷歌的最后几年里,其实一直在思考模拟计算。这样,我们可以使用 30 瓦的功率(例如大脑),而不是使用一兆瓦的功率。我希望在模拟硬件中,运行这些大型语言模型。虽然从来没实现,但我开始真正重视数字计算。
使用低功耗的模拟计算,每个硬件部分都会有所不同,即需要学习利用特定硬件的属性。这就是人们身上正在经历的。人和人的大脑都是不同的。我们不能将你大脑中的权重,放入我的大脑中。硬件不同,各个神经元的精确属性也不同。我们最后都会死去,我脑中的权重,对其他大脑也毫无用处。
我们可以很低效地将信息从一个人传递给另一个人。我写句子,你想办法改变你思维里的权重,你就会说同样的话。这其实叫做提炼,但这种知识交流非常低效。
数字系统却不同,它们不会死去。一旦有了一些权重,计算机这个壳就不重要了。只需将权重存储在某个磁带或者什么上,就可以把同样的权重转移进另一台计算机。如果是数字的,它就可以与其他系统一样计算。所以,数字系统能够以极高效率共享权重,甚至还能迭代。假设你有一大把数字系统,从相同的权重开始,各自进行微量的学习,还能再次共享权重,这样它们都能知道其他系统学到了什么,甚至完成了迭代。人类无法做到这一点,在知识共享上,数字系统比我们做得好太多。
主持人:许多已经在该领域实施的想法,其实都是非常传统的,因为这些想法在神经科学中一直存在。那么,你认为还有哪些想法可以应用于我们正在开发的系统呢?
Hinton:因此,我们仍需追赶神经科学的发展。
在几乎所有的神经网络中,都存在一个快速的活动变化时间尺度。因此,当输入进来后,活动和嵌入向量都会发生变化,然后有一个缓慢的时间尺度会改变权重。这就是长期学习。
你只有这两个时间尺度。然而在大脑中,权重会改变的时间尺度很多。例如,我说一个意想不到的词,比如“黄瓜”,五分钟后,你戴上耳机,会听到很多噪音,而且单词非常模糊,但你会更好地识别“黄瓜”这个词,因为我五分钟前说过这个词。大脑中的这些知识是如何存储的呢?这些知识,显然是突触的暂时变化,而不是神经元在重复“黄瓜”这个词。你没有足够的神经元来做这件事。这是权重的暂时变化。你可以用暂时的权重变化做很多事情,我称之为快速权重。
我们的神经模型并不会这样做,原因是,对依赖于输入数据的权重进行临时更改,则无法同时处理大量不同的情况。目前,我们采用大量不同的字符串,将它们堆叠在一起,然后并行处理它们,因为这样我们可以进行矩阵乘法,效率要高得多。正是这种效率,阻止了我们使用快速权重。但大脑显然将快速权重用于临时记忆。而且,你可以通过这种方式。做各种我们目前不做的事情。
我认为这是你必须学习的最重要的事情之一。我非常希望像Graphcore(一家英国的AI芯片公司)这样的设备,它们采用顺序方式,并只进行在线学习,那么它们就可以使用快速权重。但这还没有奏效。或许当人们使用电导作为权重时,最终它会奏效。
官网截图:https://www.graphcore.ai/
主持人:了解这些模型如何工作,了解大脑如何工作,对你的思维方式有何影响?
Hinton:多年来,人们非常看不起大型随机神经网络,只要给它大量的训练数据,它就会学会做复杂的事情的想法。你和统计学家或语言学家,或者大多数人工智能领域的人交谈,他们会说,那只是一个白日梦。没有某种先天知识,没有很多架构限制,模型就不可能学会真正复杂的事情。以为随便用一个大型神经网络,就能从数据中学习一大堆东西——但这是完全错误的。
随机梯度下降,即使用梯度反复调整权重,也可以学习非常复杂的东西,这些大型模型已经证实了这一点。这是对大脑理解的一个重要观点。大脑并不需要拥有所有的先天结构。即使大脑确实拥有许多先天结构,但对易于学习的事物,又并不需要这些先天结构。
乔姆斯基的观点是,只有当知识本身无比扎实、成熟,才能学习像语言这样复杂的事物。然而现在看来,这种观点显然很荒谬。
主持人:乔姆斯基会很高兴看到你说他的观点很荒谬。
Hinton:乔姆斯基的许多政治观点非常明智。我很惊讶,为什么一个在中东问题上观点如此明智的人,在语言学方面会犯如此大的错误。
主持人:你认为什么会让这些模型有效模拟人类的意识?现在的 ChatGPT 每次都从头开始,删除对话的记忆。如果有一个你一生中与之交谈过的人工智能助手,它能自我反省。有一天,你去世了,你认为助手在那个时候会有感觉吗?
Hinton:我认为他们也会有感觉。所以我认为,就像我们有这种感知的内在剧场模型一样,我们也有一个感觉的内在剧场模型。这些是我能体验到的东西,但其他人却不能。我认为那个模型同样是错误的。我认为,假设我说,我想打Gary的鼻子,我经常这样做。让我们试着从内心剧场的概念中总结出这一点——我真正想告诉你的是,如果不是因为我的额叶受到抑制,我就会采取行动。所以当谈论感觉时,我们实际上是在谈论没有限制的情况下会采取的行动。这就是感觉的真正含义——没有限制时,我们会采取的行动。所以没有理由说这些东西不能有感觉。
在 1973 年,我看到过有情感的机器人。他们在爱丁堡有一个带有两个夹子的机器人,如果你把零件分开放在一块绿色毛毡上,它可以组装一辆玩具车。但是你把零件堆在一起,机器人视力不够,看不清零件。就会把夹子放在一起把零件敲散,再拼一起。要是看到一个人类这么做,你会说这个他不太理解情况,很生气,所以才敲散了零件。
主持人:在我们之前的谈话中,你把人类和LLM描述为擅长做类比机器(analogy machines)。你一生中发现的,最有力的类比是什么?
Hinton:我想可能对我影响很大的一种弱类比,是宗教和符号处理之间的类比。
我来自一个无神论家庭,我小时候上学时就面临着宗教信仰。在我看来,这简直是无稽之谈。即使我再次审视,我仍然认为这是无稽之谈。有人将符号处理视为对人们工作方式时,我认为这种观点依然荒谬。
但我不认为现在的观点完全是荒谬的,我们确实在进行符号处理,我们把大的嵌入向量赋予给符号。但不是像人们以为的那样,单单匹配符号——符号的唯一属性就是与另一个符号异同,让这成为符号的唯一属性。但我们并不是这样做的。我们用上下文,为符号提供嵌入向量;借助嵌入向量组成部分之间的交互,我们才能进行思考。
有位非常优秀的谷歌研究员叫 Fernando Pereira。他认为,我们确实在进行符号推理,但唯一符号就是自然语言。我们把自然语言作为符号语言进行推理。我现在觉得这很正确。
很难因为安全问题减缓AI研究,看好医疗保健应用
主持人:你已经进行了一些计算机科学史上最有意义的研究。你能给我们讲讲,你是如何发现合适的研究问题的?
Hinton:首先,我要纠正你一下,是我和学生一起完成了很多有意义的研究。这离不开我与学生的良好合作,离不开我发现优秀学生的能力。从70年代到本世纪初,研究神经网络的人不多。我作为少数研究神经网络的人,可以选到最优秀的学生。这非常幸运。
科学家都有自己的一套研究方法理论,虽然很多科学家会总结一套自己的研究方法理论,但是实际上他们不一定真的是这么做的。但我还是想说,我的理论是,我会寻找那些人人都赞同、但直觉又能感觉出有点不对的问题。然后我就把这个定为研究问题,看看我是否能深入,说清楚我认为它是错的原因。比如也许我能用一个小的计算机程序做个demo,说明大家的预期是错的。
让我举一个例子。很多人认为,给神经网络添加噪音会让结果变得更糟。如果训练示例,让一半的神经元保持沉默,效果就会更糟。然而实际上,这样做的话会带来更好的泛化效果。你可以用一个简单的例子来证明这一点。这就是计算机模拟的优点。你可以证明,增加噪音会使情况变得更糟,去掉一半的神经元,会使它工作得更糟。短期内确实如此。但你这样训练它,最终它会工作得更好。你可以用一个小型计算机程序来证明这一点,然后你可以认真思考为什么会这样,以及它如何阻止复杂的协同适应。
这是我的研究方法。找到并研究那些看上去不可靠的事情,看看自己能否给出简单demo,说明为什么错误。
主持人:你觉得现在有什么不可靠的点呢?
Hinton:我们不使用快速权重的做法,貌似不是很可靠,我们只有两个时间尺度,这完全是错误的,一点不像大脑的工作方式。从长远来看,肯定要有更多的时间尺度。这只是一个例子。
主持人:我们谈到了推理、时间尺度。假设一群学生来问你,你的领域中最重要的问题是什么?你又会给他们什么最值得研究的问题?
Hinton:对于我来说,现在的问题和我过去 30 年来一直存在的问题是一样的,那就是大脑会进行反向传播吗?我相信大脑会获得梯度。你得不到梯度,你的学习效果就会比得到梯度时差很多。但是大脑是如何获得梯度的?它是以某种方式实现某种近似版本的反向传播,还是某种完全不同的技术?这是一个悬而未决的大问题。我继续做研究的话,这就是我要研究的内容。
主持人:当你现在回顾你的研究生涯时,你会发现你在很多事情上都是对的。但是你在什么地方做错了,以至于你希望自己花更少的时间?
Hinton:这是两个独立的问题。一是错在什么地方,二是是否希望自己花更少的时间在这上面。
我认为我对玻尔兹曼机的看法是错误的,我很高兴我花了很长时间研究它。关于如何获得梯度,有比反向传播更漂亮的理论。反向传播很普通,很明智,它只是一个链式法则。玻尔兹曼机很聪明,它是一种获取梯度的非常有趣的方法。我希望大脑也能这样工作,但事实应该并非如此。
主持人:您是否也花了很多时间想象,这些系统开发后会发生什么?您是否曾经想过,我们能让这些系统运行良好,我们就能让教育民主化,让知识更容易获得,解决医学上的一些难题。对您来说,这更多的是了解大脑?
Hinton:科学家应该做一些对社会有益的事情,但实际上这并不是开展研究的最佳方式。当好奇心驱使时,您会进行最好的研究。您只需要了解一些事情,仅此而已。
但最近,我意识到这些技术是把双刃剑,开始更加担心它们对社会的影响。但这不是我的研究动机。我只是想了解,大脑究竟是如何学习做事的?这正是我想要知道的。但我有点失败了。作为失败的副作用,我们得到了一些不错的工程。
主持人:是的,这对世界来说是一次很好的“失败”。从真正可能顺利的事情的角度来看,你认为最有前途的应用是什么?
Hinton:医疗保健显然会是很大的应用。社会可以吸收的医疗保健几乎是无穷无尽的。以一位老年人为例,他们可能需要五位全职医生的照顾。因此,当人工智能在某些领域的表现超过人类时,我们会期待它能在更多领域发挥更大的作用。这可能意味着我们需要更多的医生。每个人都能拥有三位专属的医生,那将是极好的。我们有望实现这一目标,这也是医疗保健领域的优势之一。
此外,新的工程项目和新材料的开发,例如用于改进太阳能电池板或超导性能的材料,或者仅仅是为了更深入地了解人体的运作机制,都将产生巨大的影响。这些都是积极的一面。
然而,我担心有政治家可能会利用这些技术来做邪恶的事情,比如利用人工智能制造杀人机器人,操纵舆论或进行大规模监控。这些都是非常令人担忧的问题。
主持人:你是否担心,我们放慢这个领域的发展速度,也会阻碍其积极一面的发展?
Hinton:当然,我有这样的担忧。我认为这个领域的发展速度不太可能放慢,部分原因是它具有国际性。一个国家选择放慢发展速度,其他国家并不会跟随。因此,中国和美国之间显然存在人工智能领域竞争,双方都不会选择放慢发展速度。有人提出我们应该放慢六个月的发展速度,但我并未签署这一提议,因为我认为这种情况永远不会发生。尽管如此,我可能应该签署这一提议,因为即使这种情况永远不会发生,它也提出了一个政治观点。为了表达观点,有时候我们需要提出一些无法实现的要求,这往往是一种有效的策略。但我不认为我们会放慢发展的步伐。
主持人:你认为有了这些人工智能助手,会对 AI 研究过程产生什么影响?
Hinton:我认为它们会大大提高研究效率。有了这些助手,AI研究将变得更加高效,它们不仅能帮助你编程,还能帮助你思考问题,甚至可能在各种方程式方面为你提供很大帮助。
建立自己的认知框架对于独立思考来说非常重要
主持人:你是否考虑过人才选拔的过程?这对你来说主要是依赖直觉吗?例如,当Ilya出现在门口时,你会觉得他很聪明,于是决定与他一起工作。
Hinton:在人才选拔方面,有时候你就是能感觉到。与Ilya交谈不久后,我就觉得他非常聪明。再深入交谈几句,他的直觉、数学能力都非常出色,这让我觉得他是理想的合作伙伴。
还有一次,我参加了一次NIPS会议。我们有一张海报,有人走过来,他开始询问有关学术海报上的问题。他提出的每一个问题都深入地揭示了我们的错误。五分钟后,我就给他提供了一个博士后职位。那个人就是 David McKay,他非常聪明。他去世了,这让人感到非常遗憾,但他的才华是显而易见的,你会希望能与他一起工作。然而,有时候,情况并不总是那么明显。
我确实学到了一件事,那就是人与人是不同的。优秀的学生并不只有一种类型。有些学生可能没有那么有创造力,但他们在技术上非常强,能够让任何事情都成功。有些学生在技术上可能并不出色,但他们却拥有极高的创造力。理想的情况下,我们希望找到的是既有技术实力又具备创造力的学生,但实际上,这样的学生并不总是那么容易找到。然而,我认为在实验室环境中,我们需要的是各种不同类型的研究生。
我始终坚信我的直觉,有时候,你只需要和某人进行一次交谈,他们就能理解你的意思。这就是我们所期待的。
主持人:你是否曾经思考过,为什么有些人的直觉会更强呢?他们是否只是比其他人拥有更好的训练数据?或者,你是如何培养自己的直觉的?
Hinton:我认为,部分原因在于他们不允许胡说八道。因此,这里有一种获取错误直觉的方式,那就是盲目相信你被告知的一切,这是非常危险的。我认为有些人就是这样做的。我觉得有独立思考能力的人会有一个理解现实的完整框架。当有人告诉他们某件事情时,他们会试图弄清楚这件事如何融入他们的框架。无法融入,他们就会予以拒绝。这是一个非常好的策略。
那些试图将他们被告知的一切都融入自己的框架的人,最终会得到一个非常模糊的框架,并且会相信一切。这是无效的。因此,我认为,对世界有强烈的看法,并试图操纵传入的事实以符合自身观点,是非常重要的。显然,这可能会导致你陷入深刻的宗教信仰和致命缺陷等等,就像我对玻尔兹曼机器的信仰一样。但我认为这是正确的做法。
主持人:当你看到今天正在进行的研究类型时,你是否认为我们把所有的鸡蛋都放在一个篮子里,我们应该在这个领域更加多样化我们的想法?或者你认为这是最有前途的方向然后全力以赴?
Hinton:我认为拥有大型模型并在多模态数据上训练它们,即使只是为了预测下一个单词,也是一种非常有前途的方法,我们应该全力以赴。显然,现在有很多人在做这件事。看到有很多人似乎在做疯狂的事情,这很好。我认为大多数人走这条路是可以的,它效果很好。
主持人:你认为学习算法真的那么重要吗,还是只是尺度之一?我们是否有数百万种方法可以达到人类水平的智能,或者我们需要发现少数几种?
Hinton:特定的学习算法是否非常重要,或者是否有各种各样的学习算法可以完成这项工作,我不知道这个问题的答案。但在我看来,反向传播某种意义上是正确的做法。获得梯度以便更改参数使其更好地工作,这似乎是对的,而且它也取得了惊人的成功。
可能还有其他学习算法,它们是获得相同梯度的替代方法,或者将梯度转移到其他东西上,并且也有效。我认为现在这一切都是开放的,也是非常有趣的问题,关于是否还有其他你可以尝试和最大化利用的东西,可以为你提供良好的系统,也许大脑这样做是因为这样更容易。但反向传播在某种意义上是正确的做法,我们知道这样做效果很好。
主持人:最后一个问题,当您回顾您几十年的研究历程,您最引以为豪的成就是什么?是你学生的成就吗?或者是您的研究成果?在您的整个职业生涯中,您最引以为豪的是什么?
Hinton:我的回答是玻尔兹曼机的学习算法。这个算法非常优雅,尽管在实践中可能并不实用,但这是我和 Terry共同开发的过程中最享受的事情,也是我最引以为豪的成就,即使它可能是错误的。
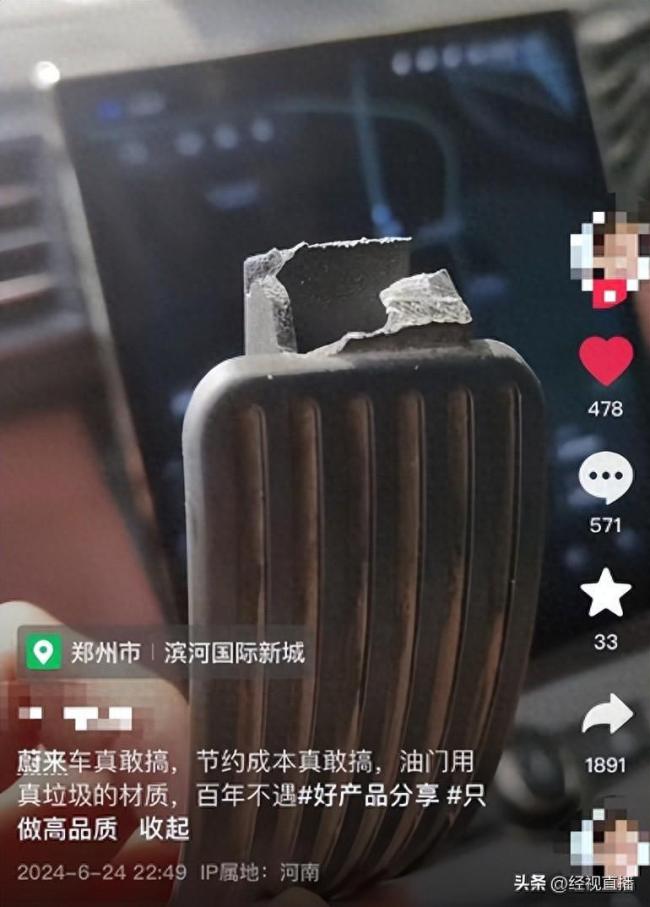
蔚来回应加速踏板断裂 涉事车辆系二手事故车

姆巴佩欧洲杯首球刷爆4大纪录!神剧本:8强战,姆皇有望对决C罗

姆巴佩打入欧洲杯首球,法国队却落入淘汰赛“死亡半区” 巨星救主难阻危局

美军舰艇,炼就“金刚不坏之身”?军事观察员解读

事发日本,以色列游客预定被取消……
姆巴佩打入欧洲杯首球,法国队却落入淘汰赛“死亡半区” 巨星救主难阻危局
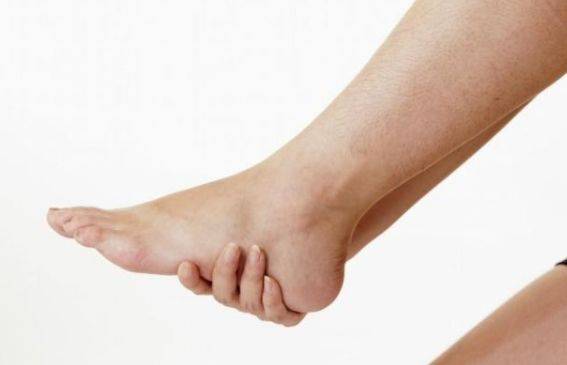
走路多了脚底痛?若出现这些症状,可能是“足弓塌陷”在预警

匈牙利反对?欧盟提出变通方法,直接绕过

再复活?台军公开展示“轮型战车”样车

于根伟下课进入倒计时?津门虎新帅或敲定大牌洋教头

魏大勋舞会穿搭,工作室晒图,网友:很帅气

马来西亚前总理马哈蒂尔接受专访:美国喜欢“引战”,然后大发战争之财
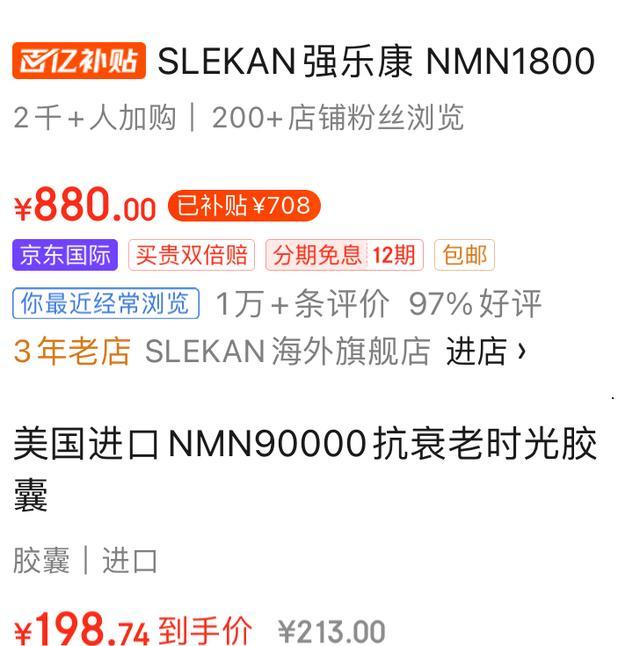
长生不老“神药”NMN禁售风波 多方回应

内塔尼亚胡称加沙激战“接近结束”,美媒:战争可能很快进入一个变化时期
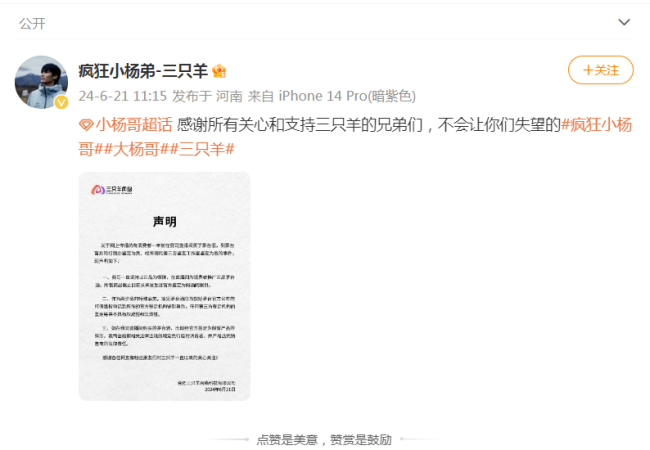
三只羊被指售假茅台 官方声明严守正品承诺

这个可怜人,最终向美国低了头
就这?美军又来跟龙王比宝了……

菲外长最新表态!“希望与中国进行对话”

什么信号?台军演习出现新变化

爷爷病床上抚摸奶奶脸颊携手凝望 本来答应好奶奶要回家的

多地“老破小”挂牌1天“秒售”!部分房源价格回落到5年前

警惕!乌克兰战场的“萨拉热窝时刻”正在逼近

特朗普前顾问出招逼俄乌和谈,自信“俄罗斯会因这一承诺被哄骗至谈判桌前”

荷兰2-3惨败却大赚,法国1-1没输反而亏惨,姆巴佩脸色难看真急了
蔚来回应加速踏板断裂 涉事车辆系二手事故车
父母假装不知成绩配合女儿查分欢呼 网友:父母提供的情绪价值拉满了

长生不老“神药”NMN禁售风波 市场混乱与监管收紧并行

俄罗斯警告美国后,这两位防长首次通话

罗云熙:“润玉”红利吃了6年,新剧因为太瘦翻车 古装美男变尴尬

不愧是韩国!直接威胁俄罗斯……

俄罗斯直接指责美国参与克里米亚袭击:后果自负

武僧一龙两次都打不赢的日本人,碰上中国小将,被打的满脸都是血

造价3亿多美元扛不住4级风 美军码头为何这么脆
姆巴佩欧洲杯首球刷爆4大纪录!神剧本:8强战,姆皇有望对决C罗

为何补时8分钟?魔笛主帅不服,董路猜想
相关新闻
马斯克:我最大的恐惧是AI,未来工作何去何从?
2024-05-25 22:56:38马斯克:我最大的恐惧是AI多地高校将严查AI代写论文 引进AIGC检测系统查AI
原标题:AI代写论文?多所高校明确:严查!现在,2024届高校毕业生陆续进入论文答辩阶段,多地高校发表声明,明确将引入论文检测工具,严查AI(人工智能)代写论文的行为。
2024-05-17 14:08:12多地高校将严查AI代写论文OpenAI发布全新生成式AI模型GPT-4o 交互革新,实时多模态引热议
5月14日,OpenAI在春季发布会上揭晓了其最新的旗舰AI模型——GPT-4o,这一模型以“全知全能”为目标,实现了实时的语音、文本、图像交互功能
2024-05-15 09:10:07OpenAI发布全新生成式AI模型GPT-4o知识之舟导航未来!AI仅10秒写完主题是AI的高考作文
互联网和技术的迅速发展,特别是人工智能的兴起,让我们仿佛潜入了一个知识的广阔海洋。信息变得触手可及,问题似乎瞬间就能找到答案。但这片海洋的深邃也引发了思考:我们的疑问,真的因此减少了吗?
2024-06-07 13:23:08AI仅10秒写完主题是AI的高考作文AI时政视界|未来之城 日新月异
联播+雄安站候车大厅内,“千年轮”的启动可以追溯至2017年4月1日,那是雄安新区设立的日子。“把智能、绿色、创新打造成为雄安新区的亮丽名片。
2024-04-02 08:27:40AI时政视界|未来之城Windows 11 AI PC品类发布:专为AI体验而设计,重塑未来计算
微软在新园区发布了一款专为AI体验设计的Windows 11 AI PC新品,这款产品内置的NPU芯片每秒运算能力超过40万亿次,能显著提升AI应用性能
2024-05-21 15:48:2611