百模”实力哪家强?研究机构测评的国内外140 大模型综合能力对比来了:国产模型新亮点

近期,一场针对大模型的全面评测活动吸引了众多关注。北京智源研究院发布的评测结果显示了140余种语言及多模态大模型的能力,这些模型覆盖了开源与商业闭源领域,旨在通过详尽的评估为公众揭示各模型的性能与易用性差异。
此次评测的一大亮点是,智源研究院与北京海淀教委合作,首次对大模型进行了K12学科测试,这一举措对把握大模型当前的发展状况及潜在应用价值具有重要意义。评测显示,尽管部分模型在综合学科能力上展现出较高水平,但仍与海淀学生平均表现存在一定差距,尤其是在理科科目和图表理解能力上暴露出弱点,显示出大模型在教育领域的应用还有待加强。
在语言模型方面,评测从多方面考察了模型的简单理解至安全价值观等能力,结果显示,字节跳动的豆包Skylark2与OpenAI的GPT-4在中文语境下表现突出,体现了国内大模型对本土用户的深刻理解。多模态模型评测则聚焦于图文理解与生成能力,展示了如OpenAI DALL-E3在文生图领域的领先地位,以及OpenAI Sora在文生视频中的显著优势。值得注意的是,国产模型如爱诗科技的PixVerse也在文生视频评测中取得了优异成绩,表明国产大模型正逐步缩小与国际先进水平的差距。
智源研究院院长王仲远强调,多模态模型仍处于初级发展阶段,现有评测标准与方法需伴随技术进步持续更新。他指出,未来多模态模型将趋向与语言模型融合,要求模型不仅具备高水准的生成能力,还需掌握世界的运行规律及科学原理,评测体系亦需随之快速演进。
关于大模型在教育行业的应用潜力,王仲远表示,K12学科测试并非直接服务于教育行业,而是作为检验模型跨学科能力的一种手段,有助于辨识模型在特定领域的适用性,如数理化能力强的模型可能更适合应用于材料科学或医疗领域。
综观评测,尽管大模型在多个领域展现出了令人瞩目的成就,但其发展和完善之路依旧漫长,特别是在实现真正意义上的多模态理解和生成上,以及如何更贴近人类认知逻辑上,均有待进一步探索和突破。

野猪莽撞冲入饭店 两顾客兴奋追打!

胖东来与擀面皮事件联营商户解除合同:奖励投诉顾客10万元,相关工作人员辞退、免职

专家称应立即叫停一元面值退市

女生高考查分见6开头坐地大哭!

核战风险升级到数十年来最高点,国际核态势处关键转折点

水位满出河堤 村书记绑绳疏通涵管

《度华年》追剧日历曝光 高甜预警,共赴时空之约
柴犬丢失9个月被民警找回 奇迹团圆感动人心

多国宣布将自带空调参加巴黎奥运会!

不只有“美国航母挨炸”,中国沙漠靶场还惊现“被摧毁的F-22”

狮子搏兔,俄军使用昂贵制导炮弹打步兵,又富裕了?

赵露思到底摸到了什么 全民好奇心引爆网络

阻挠中美人文交流这个锅,美国甩不出去

美研制新海基核巡航导弹,或激发新一轮核军备竞赛

在韩打工11年的中国人:赚得多花得多,在国内能月入5000元就别来

扬言卖战机、出售军事机密?韩国严查社交网络频道!

关于英语,泽连斯基签令!

复旦的招生方式好有梗 官方整活引热议

美军舰艇,炼就“金刚不坏之身”?军事观察员解读

美对台军售两款巡飞弹,“大突破”背后有什么盘算

看不懂,但很震撼!土耳其晋级淘汰赛后,恰尔汗奥卢带领全队花式庆祝
专家称应立即叫停一元面值退市

继美国空军后,美海军陆战队也重启太平洋二战机场
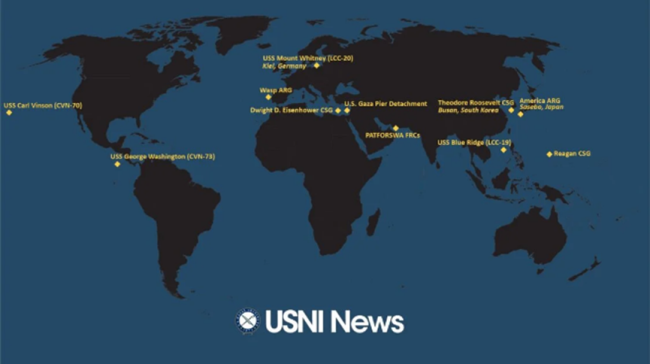
美国航母怎么又不够用了?
“中国第六代战斗机初见曙光”,美媒:技术验证机或已试飞!

三代变身四代,德法主战坦克新发展有何启示?

一觉醒来,这个锂矿大国发生闪电政变
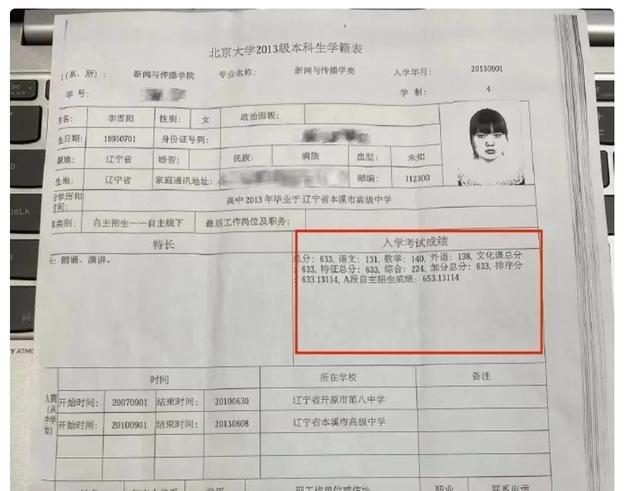
李雪琴未通过体育加分造假上北大,其同学称没有这回事
胖东来与擀面皮事件联营商户解除合同:奖励投诉顾客10万元,相关工作人员辞退、免职

美国再向中国发难,这次是核问题……

胡塞武装公布视频:自研高超音速导弹袭击以色列船只

马来西亚前总理马哈蒂尔接受专访:美国喜欢“引战”,然后大发战争之财
野猪莽撞冲入饭店 两顾客兴奋追打!

德布劳内指示接应 队友无动于衷 队长冷静应对嘘声风波

俄军在黑海上空击落美军“全球鹰”无人机?克宫回应
相关新闻
百模大战"拼价格!国内大厂开卷,AI大模型纷纷降价:普惠AI时代来临
2024-05-23 09:11:40“百模大战”拼价格!国内大厂开卷学术不端引咎撤模!斯坦福AI项目作者对抄袭中国大模型致歉
近日,斯坦福大学AI团队开发的Llama3-V开源模型,被指涉嫌抄袭清华大学与面壁智能合作的开源模型“小钢炮”MiniCPM-Llama3-V 2.5,此事件迅速在网络上引发了广泛关注和讨论。
2024-06-04 16:32:19斯坦福AI项目作者对抄袭中国大模型致歉盘点茶百道商业版图 港交所挂牌显实力
2024-04-23 21:40:25盘点茶百道商业版图字节大模型比行业价格低99% 引领大模型“厘时代”革新
2024-05-15 17:20:28字节大模型比行业价格低99%Meta无限长文本大模型来了:参数仅7B,已开源 高效稳定,超越Transformer
2024-04-18 12:57:16Meta无限长文本大模型来了:参数仅7B李开复称大模型疯狂降价是双输 国内大模型竞争白热化
2024-05-22 09:56:37李开复称大模型疯狂降价是双输








