Meta无限长文本大模型来了:参数仅7B,已开源 高效稳定,超越Transformer

谷歌和Meta相继在无限长上下文建模领域展开角逐。Transformer模型因二次复杂度及对长序列处理的局限性,尽管已有线性注意力和状态空间模型等次二次解决方案,但其预训练效率和下游任务准确性仍不尽人意。谷歌近期推出的Infini-Transformer通过创新方法,使大型语言模型能够处理无限长输入,且无需增加内存与计算需求,引发业界关注。
紧随其后,Meta携手南加州大学、CMU、UCSD等研发团队,推出了名为MEGALODON的神经架构,同样致力于无限长文本的高效序列建模,上下文长度无任何限制。MEGALODON在MEGA架构基础上,引入了复数指数移动平均(CEMA)、时间步归一化层、归一化注意力机制及具备双特征的预归一化残差配置等技术组件,旨在提升模型能力和稳定性。
在与LLAMA2的对比试验中,拥有70亿参数、经过2万亿训练token的MEGALODON展现出超越Transformer的效率优势。其训练损失为1.70,介于LLAMA2-7B(1.75)与13B(1.67)之间。一系列基准测试进一步证实了MEGALODON在不同任务与模式中相对于Transformers的显著改进。
MEGALODON的核心改进在于对MEGA架构的优化,利用门控注意力机制与经典指数移动平均法。为增强大规模长上下文预训练的能力与效率,研究者引入了CEMA,将MEGA中的多维阻尼EMA扩展至复数域;并设计了时间步归一化层,将组归一化应用于自回归序列建模,实现沿顺序维度的归一化。此外,通过预归一化与两跳残差配置调整,以及将输入序列分块为固定块,确保了模型训练与推理过程中的线性计算与内存复杂性。
在与LLAMA2的直接较量中,MEGALODON-7B在同等数据与计算资源条件下,训练困惑度显著低于最先进的Transformer变体。针对长上下文建模能力的评估涵盖了从2M的多种上下文长度到Scrolls中的长上下文QA任务,充分证明了MEGALODON处理无限长度序列的能力。此外,在LRA、ImageNet、Speech Commands、WikiText-103和PG19等中小型基准测试中,MEGALODON在体量与多模态处理方面展现卓越性能。
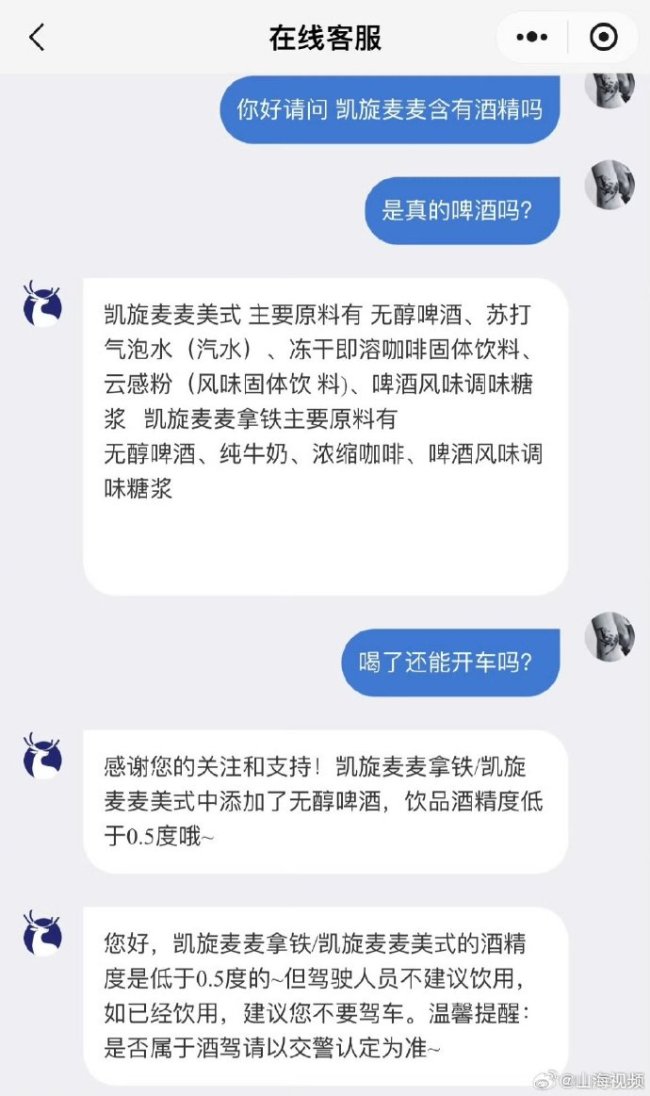
瑞幸称凯旋麦麦酒精度低于0.5度 喝完勿开车

当27岁的阿斯塔纳遇上23岁的上合,一起找寻青春的气息!

什么是住房公积金年度结息?

湖南一工作人员防汛时被水冲走失联

菲律宾,又传来一个坏消息

高三女生卖游戏ID反被骗900元

农村学生营养餐补贴不能成“唐僧肉”
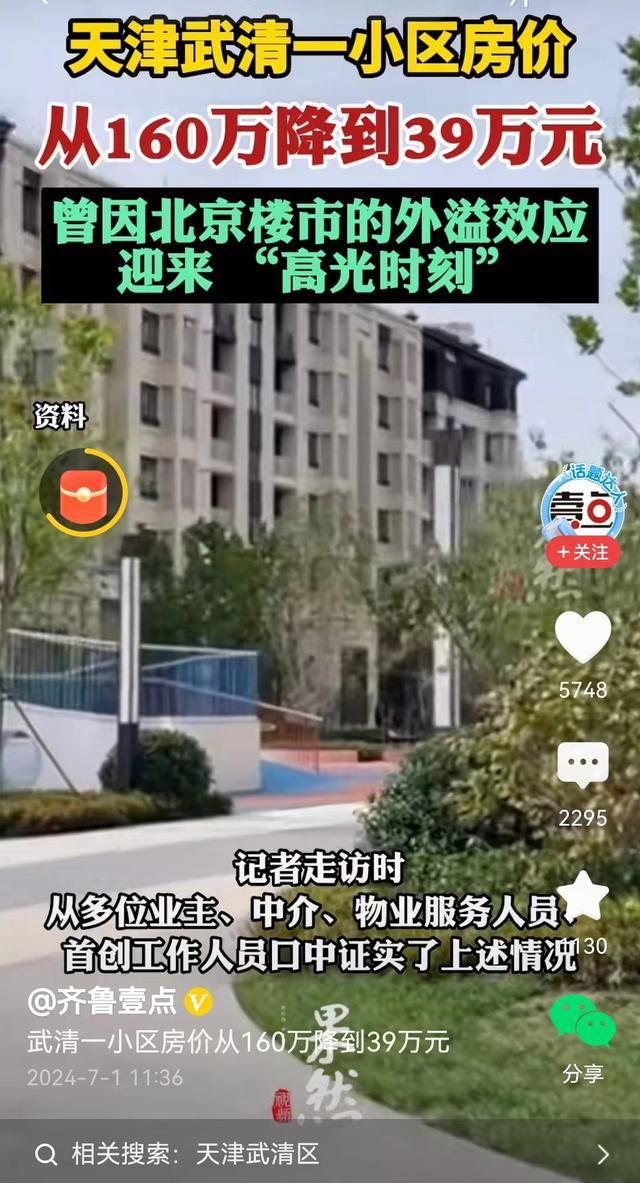
160万房降到39万可以不还房贷吗?楼市寒冬下的购房者困境

匈牙利接任欧盟轮值主席国前夕,欧尔班发文:欧盟领导层想与俄开战

炒作所谓“间谍”风险,白宫欲对中国起重机加税,美港口群起反对!

美国究竟有多少核弹头?最新数据
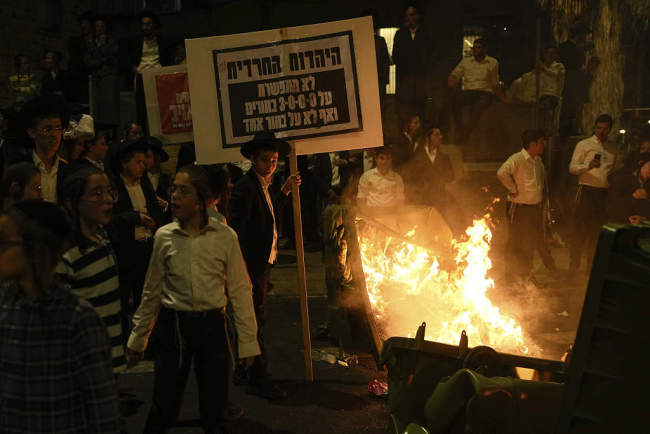
“宁愿死也不参军!”以色列极端正统派上街抗议征兵

平江暴雨为何洪水排不出去 道路塌方引担忧

法国“屏住呼吸”举行议会选举!美媒:此次选举可能“撼动欧盟与北约”

上海空港口岸入境旅客数量持续增长 外籍旅客增幅显著
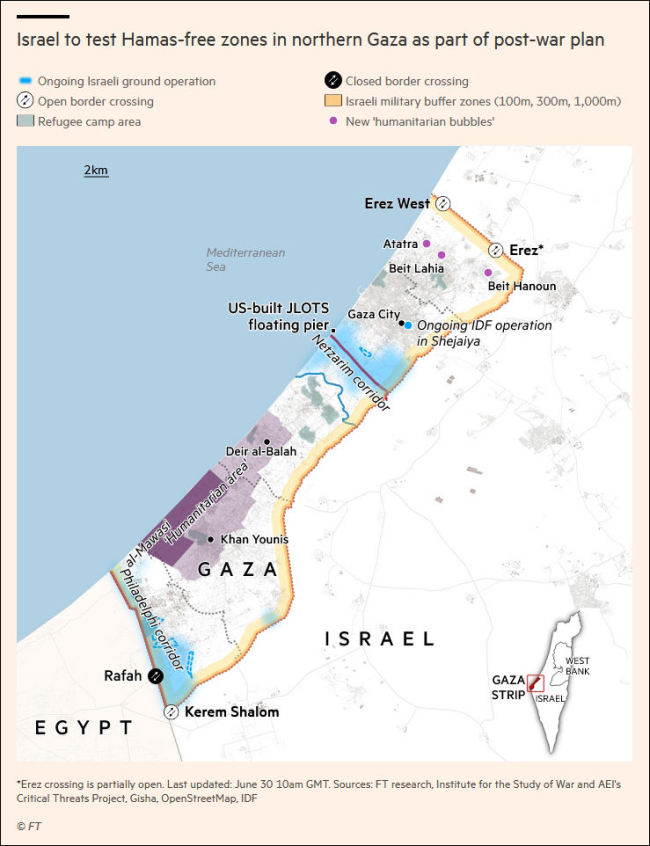
以色列在加沙试点逐渐取代哈马斯,被哈马斯武力挫败

高校回应开设"导弹维修技术"专业:是真的

议起复盘 马刺童话过于美好 勇士三叉戟解体终究未能复制传奇

大选辩论后,拜登陷入“劝退”漩涡!美媒刊文:“他已不是4年前的他了”

党内盟友涌向媒体,千方百计转移话题,拜登开展危机公关救选情!

限制北约收集情报,威胁击落美无人机!俄军考虑在黑海设立禁飞区

张志杰母亲听闻噩耗病倒入院 家庭支柱骤失引悲痛

美媒炒作:盟友不是信不过拜登,质疑声太多恐“便宜”了中俄

央行今年多次提示长债风险 债市"纠偏"行动升级

国会请愿网站一度瘫痪!80万韩国网民要求“弹劾尹锡悦”

新华社谈张志杰离世:生命至上应是赛场的最高规则

卫星影像显示山东舰抵菲附近海域,外媒猜测有“威慑”之意?军事专家解读
中企高管菲律宾被撕票 疑受邀前去考察
什么是住房公积金年度结息?
瑞幸称凯旋麦麦酒精度低于0.5度 喝完勿开车
当27岁的阿斯塔纳遇上23岁的上合,一起找寻青春的气息!

中国一个“管理条例”,又让西方破了大防

泽连斯基称不排除与俄“迂回”谈判,乌媒:谈判态度发生“180度大转弯”!

百花奖提名揭晓:《万里归途》《封神》领衔竞争激烈

“买家秀”!塞尔维亚首次公开展示红旗-17AE防空系统
相关新闻
中国大模型登顶全球开源第一!
金融领域正成为大型模型应用的重要潜在场景。度小满公司近期在金融大模型的实践上取得显著进展,致力于解决该领域落地的实际难题,并把握信息技术进步带来的机遇,加速推进大模型的研发与应用,以强化其技术基础
2024-06-27 13:34:44中国大模型登顶全球开源第一昆仑万维宣布天工3.0大模型开启公测,拥有4000亿参数
4月17日,昆仑万维发布重要消息:其自主研发的“天工3.0”基座大模型及“天工SkyMusic”音乐大模型已面向公众开放公测
2024-04-17 15:00:08昆仑万维宣布天工3.0大模型开启公测Meta CEO扎克伯格最新采访:最强开源模型Llama 3凭什么值百亿美金
2024-04-19 13:49:45Meta昇腾社区回应华为发布会被指造假:是读取外部开源大模型实时生成的图片
5月16日,昇腾社区就网传发布会演示造假的质疑做出回应。在5月10日的鲲鹏昇腾开发者大会上,他们展示了一项mxRAG SDK的功能,旨在向开发者证明仅需少量代码就能快速开发RAG应用
2024-05-16 14:24:44昇腾社区回应华为发布会被指造假:是读取外部开源大模型实时生成的图片美国最该尴尬的,是今天中国开源模型们重大的贡献 通义大模型引领创新潮
5月9日的阿里云AI智领者峰会上,阿里云首席技术官周靖人分享了通义大模型的最新应用和服务数据。据统计,通义大模型通过阿里云已服务于超过9万家企业,而通过钉钉平台,这一数字达到了220万
2024-05-11 21:21:50美国最该尴尬的斯坦福AI团队“套壳”清华系开源大模型被实锤,被揭穿后全网删库跑路 学术诚信警钟再响
近期,斯坦福大学的人工智能研究团队推出了一款名为Llama3-V的多模态大型模型,宣称其性能超越了GPT-4V等其他知名模型
2024-06-04 20:06:10斯坦福AI团队“套壳”清华系开源大模型被实锤