DeepSeek的新模型很疯狂:整个AI圈都在研究视觉路线,Karpathy不装了

DeepSeek的新模型很疯狂:整个AI圈都在研究视觉路线,Karpathy不装了!DeepSeek-OCR 论文的发布在一夜之间打破了大模型的传统范式。昨天下午,全新模型 DeepSeek-OCR 开源,该模型能够将1000个字的文章压缩成100个视觉token,压缩比达到十倍且精度可达97%。使用一块英伟达A100每天可处理20万页数据。这种处理方式可能解决大模型领域中的长上下文效率问题,并预示着大模型输入方式的重要转变。
GitHub上,DeepSeek-OCR项目一夜之间获得了超过4000个Star。作为开源的小模型,它迅速经历了AI社区的检验,许多专家对此发表了看法。OpenAI联合创始成员之一、前特斯拉自动驾驶总监Andrej Karpathy认为这是一个很好的OCR模型。他更感兴趣的是,对于大语言模型而言,像素是否比文本更适合做输入?他提出,所有LLM的输入都应该是图像,即使有纯文本输入,也应先渲染再输入。这将带来更高的信息压缩率和更通用的信息流。
Karpathy还强调了删除分词器的重要性。他认为分词器丑陋且独立存在,不是端到端的,引入了Unicode和字节编码的问题,增加了安全风险。此外,OCR只是众多有用的视觉-文本任务之一,文本-文本任务可以转换为视觉-文本任务,但反之则不行。
纽约大学助理教授谢赛宁对Karpathy的观点表示赞同,尤其是关于计算机视觉与自然语言处理结合的部分。谢赛宁曾首次将Transformer架构与扩散模型结合,提出了扩散Transformer(DiT),为文生视频开辟了新道路。
研究者Emanuel指出,在多模态大语言模型中,视觉token传统上是“外挂”功能。然而,DeepSeek-OCR通过高效压缩视觉token,使其比文本token更高效。一万英文单词原本对应15,000个文本token,但转换成视觉token后可能变成30,000到60,000个。而DeepSeek-OCR的压缩方法使这一过程变得更加高效。

民进党当局公告日本5地核食管制解禁 引发岛内哗然疑虑

上周末我国多领域迎来新突破 捷报频传

专家:高市错误言论暗藏三大意图 挑战中方底线

美国宇航局发布神秘星际天体新图像,揭示了其真实本质,成功击破持续数周的网络谣言!

中国无人驾驶重卡开进英国最大港口 科技风景线闪耀菲力斯杜港

美国为什么从日本撤走“堤丰”中程导弹系统? 局势突变引发撤离

中国004航母核动力真相曝光 战斗力惊人 或成全球最大航母

日本发生大火今晨仍未被扑灭 火势持续蔓延

加总理:即使没有美国世界也可以运转 G20共识仍具分量

湖人再胜爵士 客场险胜迎4连胜

高市早苗被拒进入日本相扑擂台 传统规定引发争议

首个报道南京大屠杀的记者王火去世 百岁人生见证历史
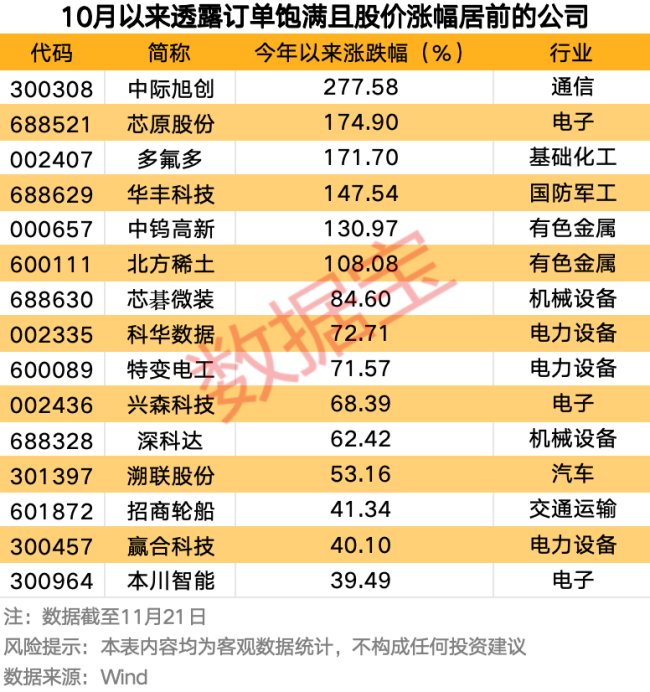
最新!订单爆棚的公司名单来了,12家获机构扎堆关注 业绩增长催化剂
上周末我国多领域迎来新突破 捷报频传

张家界荒野求生决赛开始 14强选手迎终极挑战

日本为啥急于重启柏崎刈羽核电站 能源危机下的无奈选择

公然挑衅,执意玩火!高市早苗挑衅言论会造成什么样的恶果?

官方通报三无飞机问题 面条厂造飞机暗藏风险

特朗普猛烈抨击乌克兰领导层 感激危机背后的博弈

中国军队坚定捍卫国家主权 维护地区和平稳定

南通崇川区原一级调研员陈跃生被查 涉嫌严重违纪违法

公然挑衅,执意玩火!高市早苗挑衅言论会造成什么样的恶果?

日本夺岛方案“揭秘” 自卫队三套计划曝光

日本一工厂发生火灾火势无法控制 持续8小时未减弱

石破茂再批高市早苗 外交政策遭严厉批评

韩国总统希望早日访华 推进中韩合作
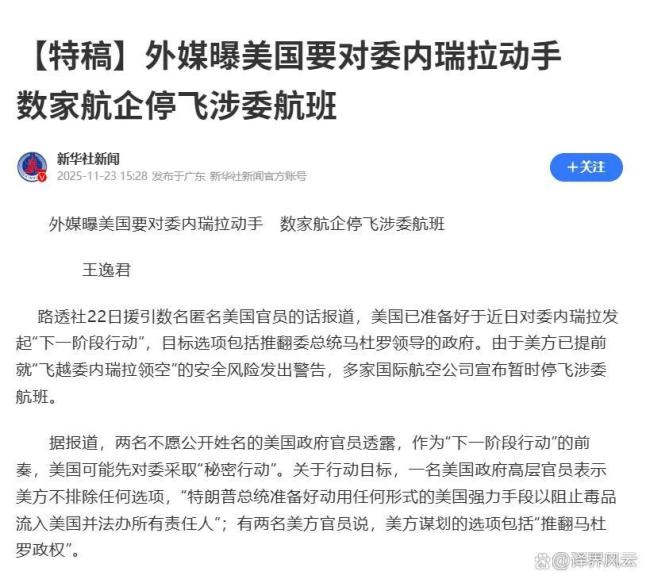
美发布“委领空预警”是要动手了吗 历史重演?

英伟达力推对华芯片销售 中美关系缓和现曙光
专家:高市错误言论暗藏三大意图 挑战中方底线

美国专家批评高市错误言论 转移国内注意力

日本民众批评高市早苗 要求其辞职平息局势

男子卧铺车厢排便旅客鞋子箱子遭殃 醉酒惹祸端
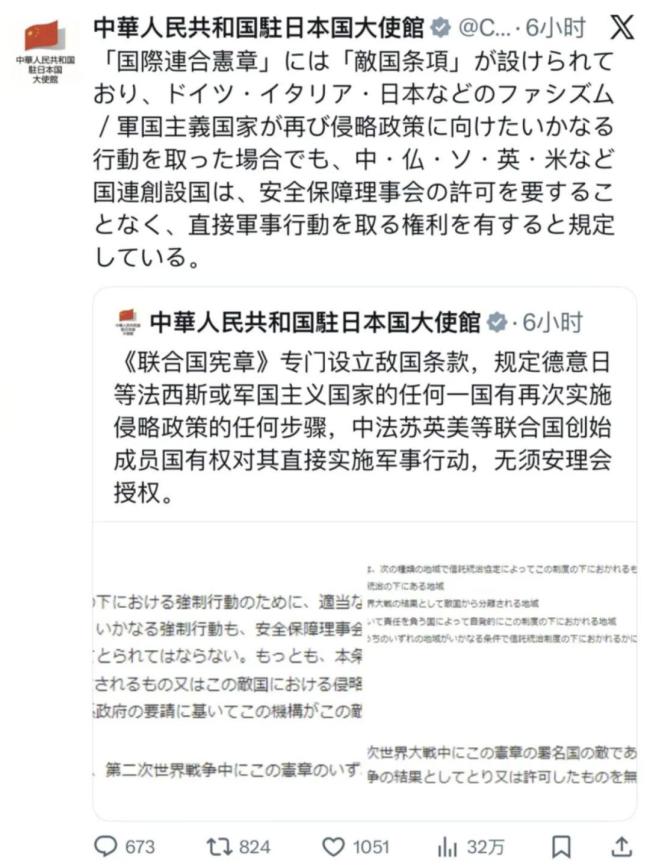
日媒宣传“敌国条款”已废除,事实真是如此吗? 中国官方重申条款真相
民进党当局公告日本5地核食管制解禁 引发岛内哗然疑虑

樊振东店长工作牌 樊振东任小米一日店长
相关新闻
DeepSeek开源新模型DeepSeek-OCR 探索视觉-文本压缩边界
10月20日,人工智能团队DeepSeek AI发布了全新多模态模型 DeepSeek-OCR
2025-10-20 20:33:14DeepSeek开源新模型DeepSeek-OCRDeepSeek使用率暴跌 原因何在?新模型R2缺席影响显著
由于新模型R2迟迟未发布,DeepSeek近期备受关注。国际知名半导体研究机构Semianalysis的报告显示,DeepSeek的用户使用率从年初的7.5%峰值显著下降至3%,官网流量同期下滑近三成
2025-07-10 13:25:04DeepSeek使用率暴跌原因何在DeepSeek为何发表研究成果 揭示AI模型秘密
证券时报的文章内容仅供参考,不构成实质性投资建议,据此操作风险自担。下载“证券时报”官方APP或关注官方微信公众号,可以随时了解股市动态,洞察政策信息,把握财富机会
2025-09-20 12:51:47DeepSeek为何发表研究成果DeepSeek在《自然》杂志公布论文 R1模型成本创新低
AI初创公司DeepSeek的论文最近登上了《自然》杂志。该公司表示,其强大的AI模型R1的成功并不依赖于模仿其他大型语言模型生成的示例进行训练。这一声明随着R1模型同行评审版本的发布而公布
2025-09-20 12:18:52DeepSeek在自然杂志公布论文DeepSeek开源新版R1 媲美OpenAI 性能媲美o3模型
DeepSeek开源了R1最新0528版本,尽管官方未对此版本进行详细说明,但已有网友在著名代码测试平台Live CodeBench中发现其性能可与OpenAI最新的o3模型高版本相媲美
2025-05-29 08:46:15DeepSeek开源新版R1媲美OpenAIDeepSeek R1模型已完成小版本试升级 官方邀您体验
5月28日,DeepSeek官方宣布,DeepSeek R1模型已完成小版本试升级。用户可以前往官方网页、APP或小程序测试新功能,API接口和使用方式保持不变
2025-05-29 08:41:18DeepSeekR1模型已完成小版本试升级