华为万卡集群挑战英伟达胜算几何 中国AI算力逆袭之路

华为万卡集群挑战英伟达胜算几何 中国AI算力逆袭之路!当全球科技界还在为英伟达H100的算力神话惊叹时,华为在9月18日的全联接大会上发布了一款名为Atlas960的超节点产品。这款产品支持15488张昇腾卡,其FP8算力达到惊人的8EFLOPS,互联带宽突破16PB/s,硬指标全面超越英伟达同期产品。这不仅是华为被制裁六年来最猛烈的技术反击,也标志着中国AI产业正式吹响了算力自主化的号角。
徐直军表示,算力过去是,未来也将继续是人工智能的关键,更是中国人工智能的关键。2019年华为被列入实体清单时,中国AI产业面临算力断供的困境——英伟达A100禁运、台积电断供7nm工艺、国产GPU性能落后三代。如今昇腾950/960芯片路线图的公布,证明华为选择了一条“超节点+集群”的突围路径。
MatrixLink全对等互联技术是这场逆袭的核心武器。不同于英伟达依赖CPU调度的传统架构,华为让每个NPU、DPU都拥有平等话语权,实测显示LLaMA3千亿模型训练速度达到传统方案的2.5倍。15488卡超节点不仅实现硬件指标超越,更重构了算力底层架构,就像用分布式电网取代集中供电站,这种范式革命让中国首次掌握AI基础设施定义权。
华为计划在2027年实现百万卡超节点的目标,这意味着将形成覆盖50万至100万张加速卡的算力网络,为中国AI产业提供永不枯竭的“数字三峡”。基于中国芯片制造工艺的解决方案完全规避了H20芯片禁运风险,同时构建起包含80多个适配大模型和2700多个行业伙伴的生态壁垒。实测数据显示,在多模态模型Qwen测试中,图像生成速度超过同行1.2倍,视频处理效率直接翻倍。
昇腾384超节点的技术细节令人惊叹:300Pflops算力、269TB/s带宽、1229TB/s内存吞吐。与英伟达NVL72并排对比时,107%的互联带宽优势形成碾压态势。华为通过光互连技术和存算一体芯片的全栈替代,将“备胎计划”升级为引领性方案。美国政府限制H20芯片出口的背景下,华为公开的芯片路线图展现出惊人魄力。950PR芯片采用自研HBM内存,950DT优化了张量计算架构,而2027年的昇腾970将实现存算一体突破。徐直军强调的“基于中国可获得的芯片制造工艺”,实际上是用架构创新绕过制程封锁。
“万卡超节点,一台计算机”的理念正在颠覆传统认知。华为已部署的300多套CloudMatrix384超节点,在金融、能源等11个领域落地6000多个解决方案,证明算力可以像电力一样成为国家基础能力。当Atlas960在2027年实现百万卡集群时,中国将拥有全球唯一不受地缘政治影响的AI算力供给体系。这场逆袭的意义在于,从被迫“备胎转正”到主动定义标准,华为不仅改写了企业命运,也为所有追赶者上了一课——真正的技术自主从来不是简单的参数超越,而是体系重构的降维打击。

一张价值40万豹皮的转卖历程 多次倒手终被查处

你如何看男子持续多年朝商店扔钱 神秘顾客的“固执”行为

男子给网友寄281克黄金被拦截 警方及时止损28万
一张价值40万豹皮的转卖历程 多次倒手终被查处

特朗普走下空军一号再现经典舞步 外交派对开场
你如何看男子持续多年朝商店扔钱 神秘顾客的“固执”行为

美媒:亿万富翁蒂莫西·梅隆捐款1.3亿美元,帮助特朗普支付军人工资 低调富豪的慷慨之举
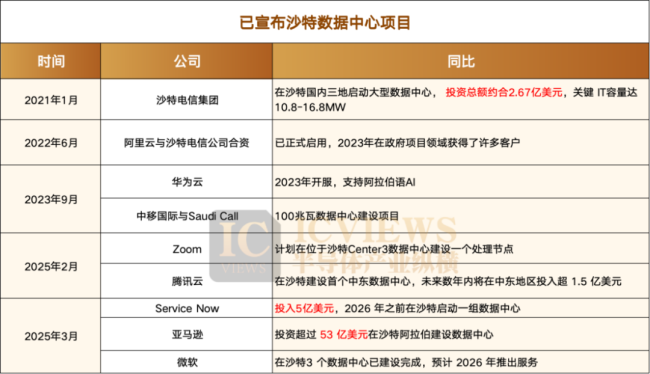
沙特能否成为算力中心 转型中的科技雄心
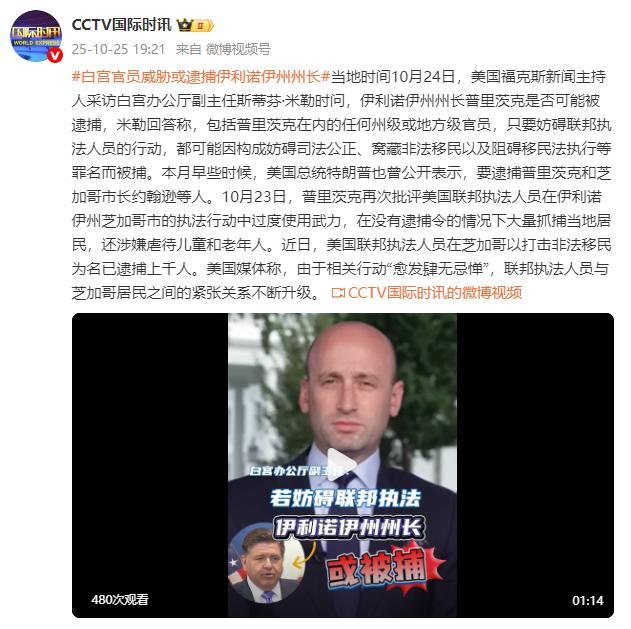
白宫官员威胁或逮捕伊利诺伊州州长 执法争议升级

粉丝给馆长念欢迎台湾小朋友 馆长频频点头直呼“有心了”

越南国会任命新副总理 范氏清茶成首位女性副总理
女村支书回应带全村老人免费旅游 温暖行动获赞无数

解放军抢滩登陆演练机器狗当先锋 钢铁之躯震撼登场

美两党议员呼吁加强博彩监管 NBA赌博风波凸显体育博彩合作风险
男子给网友寄281克黄金被拦截 警方及时止损28万

APEC峰会本周在韩国举行,各国首脑外交成焦点 中美会晤备受期待

评论员称美军根本不想打委内瑞拉 施压而非开战

台网红馆长怒斥民进党是历史的罪人 篡改历史遗忘抗日

坠入南海美军机单价超F35 MH-60R直升机价格惊人

郑丽文喊话朱立伦赵少康 促蓝军大团结

赵一鸣客服回应门店用糖找零:公司明确不支持用糖果找零

印度称被枪指着头时不会签任何协议 绝不仓促妥协

以军无人机空袭维和部队 未造成人员伤亡
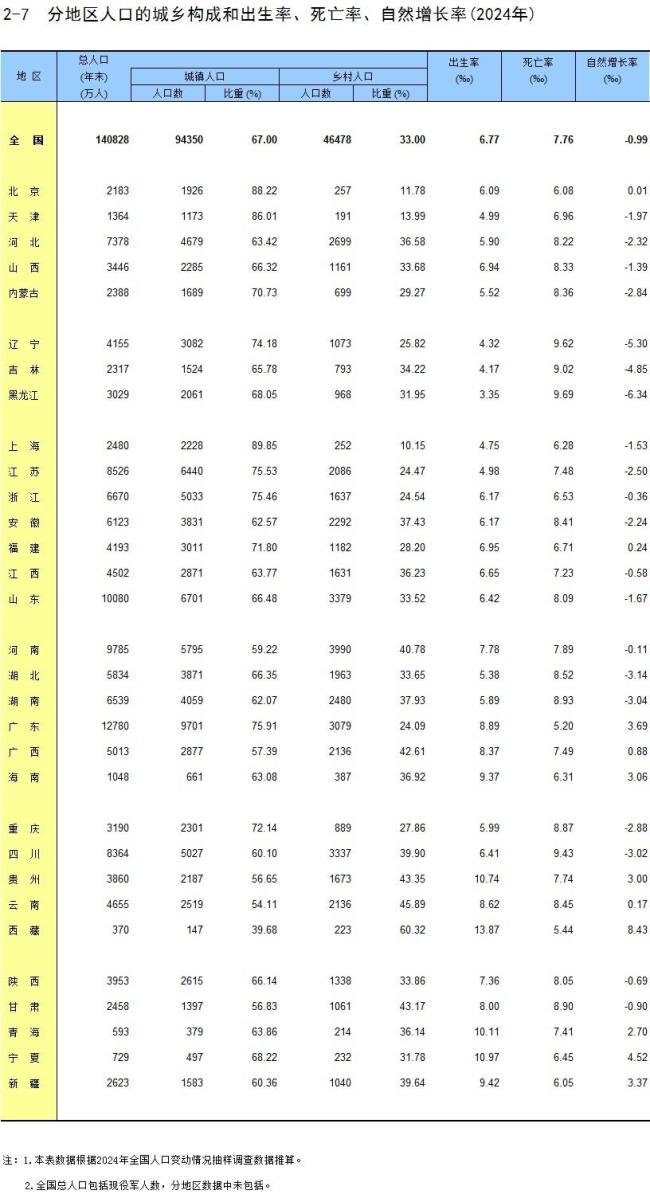
4省去年出生人口超50万 广东连续7年居首

菲总统会见高市早苗 南海布局新篇章

男子交百万给女友保管女子全花脸上 恋爱财务纠纷背后的信任与法律边界

渔民捕获罕见“石斑王”约重200多斤
我驻柬使馆辟谣中国女子被绑架 轻生事件引发误解
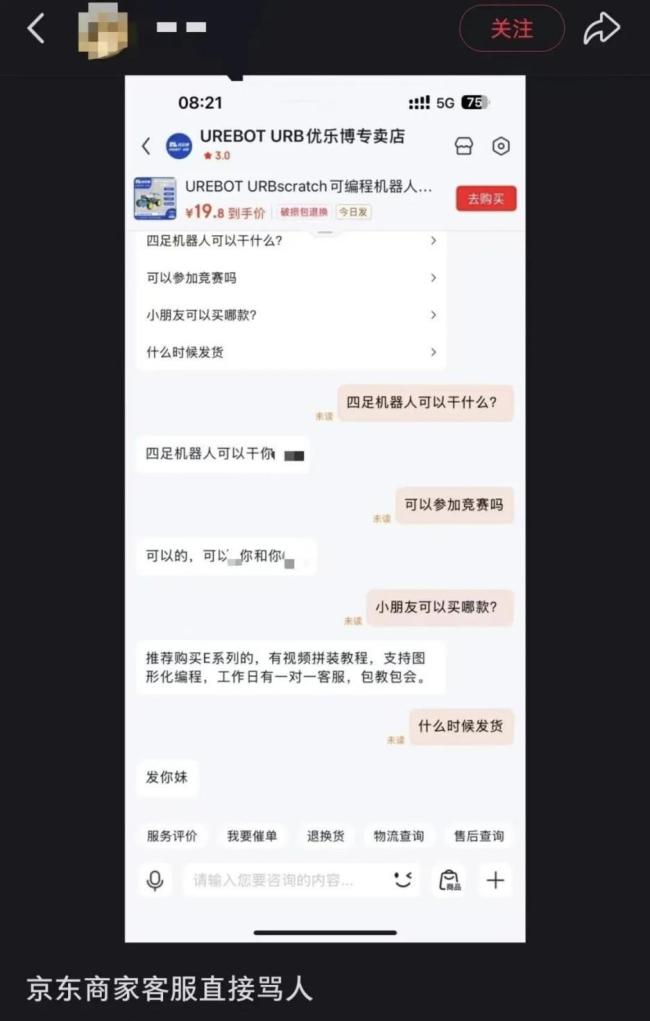
优乐博客服辱骂消费者?商家最新回应 疑似黑客攻击已报警处理

俄军大规模炮轰赫尔松沿岸 夜战火光映战场

小偷入室盗窃遇房主回家钻床下

馆长说认同自己是中国人无比光荣 “要帮台湾人找回被民进党刻意淡化的历史”

俄就美欧对俄新制裁回应 不会产生重大影响

28日美空管人员将完全领不到工资 航班延误或加剧

5岁女孩成六大派团宠宛如郭襄现世 武术小冠军引热议
相关新闻
华为超级节点挑战英伟达霸权 开源打破垄断
2025-09-19 07:39:29华为超级节点挑战英伟达霸权宗馥莉押注“娃小宗”胜算几何 品牌更迭挑战重重
2025-10-11 15:26:16宗馥莉押注娃小宗胜算几何AI过热隐忧再现 英伟达们前景几何 资本开支增长成焦点
在一轮飞速反弹后,美股进入了波动期。科技股或人工智能(AI)主题能否持续发力成为投资者关注的焦点。过去两周,华尔街对AI资本开支增长可能在2026年见顶表示担忧
2025-09-09 09:11:32AI过热隐忧再现英伟达们前景几何媒体:英伟达需要重新认识中国市场 本土竞争加剧挑战
7月15日,英伟达创始人兼CEO黄仁勋出席了第三届中国国际供应链促进博览会。这是他在2025年内第三次访问中国大陆。几天前的7月9日,英伟达市值在盘中突破4万亿美元大关
2025-07-15 19:27:45媒体黄仁勋称华为AI芯片将取代英伟达 时间问题
7月16日,英伟达CEO黄仁勋在接受采访时谈及AI训练时华为AI芯片能否取代英伟达的问题。他认为这只是时间问题,并表示英伟达已在这方面努力了30年,而华为虽然起步较晚,但已经展示了强大的实力
2025-07-17 07:31:42黄仁勋称华为AI芯片将取代英伟达华为系列产品全面对标英伟达 算力竞赛新布局
2025-09-20 15:35:42华为系列产品全面对标英伟达