DeepSeek公布推理新论文 提升奖励模型可扩展性

DeepSeek R2的研究成果已经接近。最近,DeepSeek和清华大学的研究者发表了一篇论文,探讨了奖励模型在推理时的Scaling方法。
强化学习(RL)已广泛应用于大规模语言模型(LLM)的后训练阶段。通过RL激励LLM的推理能力表明,采用合适的学习方法可以实现有效的推理时可扩展性。然而,RL面临的一个关键挑战是在多种领域中为LLM获得准确的奖励信号。
研究者发现,在奖励建模(RM)方法上采用点式生成式奖励建模(GRM),可以提升模型对不同输入类型的灵活适应能力,并具备推理阶段可扩展的潜力。为此,他们提出了一种自我原则点评调优(SPCT)的学习方法。这种方法通过在线RL训练促进GRM生成具备可扩展奖励能力的行为,即能够自适应生成评判原则并准确生成点评内容,从而得到DeepSeek-GRM模型。
DeepSeek-GRM-27B是基于Gemma-2-27B经过SPCT后训练的。实验结果表明,SPCT显著提高了GRM的质量和可扩展性,在多个综合RM基准测试中优于现有方法和模型。研究者还比较了DeepSeek-GRM-27B与671B更大模型的推理时间扩展性能,发现它在模型大小上的训练时间扩展性能更好。此外,他们引入了一个元奖励模型(meta RM)来引导投票过程,以提升扩展性能。
研究者的贡献包括:提出了一种新方法——自我原则点评调优(SPCT),用于推动通用奖励建模在推理阶段实现有效的可扩展性;SPCT显著提升了GRM在奖励质量和推理扩展性能方面的表现,超过了现有方法及多个强劲的公开模型;将SPCT的训练流程应用于更大规模的LLM,并发现相比于训练阶段扩大模型参数量,推理阶段的扩展策略在性能上更具优势。

为这个女警队点赞!她们是200多个孩子的紧急联系人

车展内外齐发力 带火汽车消费热 政策补贴助推市场活力
儿子瞒着父母考上北大研究生 妈妈得知后震惊 惊喜让妈妈笑醒

邓卓翔:全力以赴对待与津门虎的比赛 积极备战迎接挑战

花了近7000订到假五星酒店 平台独特评分引争议

停火结束战争继续,普京宣布恢复攻势 双方互指违反协议
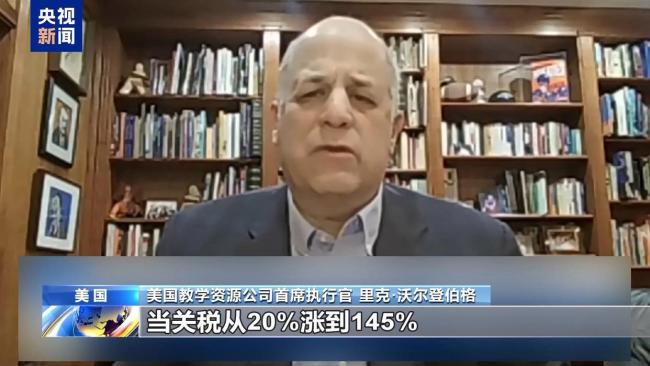
美玩具公司因关税政策起诉美政府 中小企业维权之战

美军战略轰炸机进驻日本想演给谁看 加剧亚太安全困境
车展内外齐发力 带火汽车消费热 政策补贴助推市场活力

84斤女子称买百件衣服穿不上 网购尺码困扰多

金正恩携女儿出席朝鲜人民军新型驱逐舰入水仪式 称“将一刻不停地建设海军”

美关税政策重创美电商行业 跨境电商面临严峻考验

韩国残运会盒饭只有海苔泡菜 简陋餐食引争议

和泽连斯基见面后 特朗普质疑普京 是否真心结束冲突
为这个女警队点赞!她们是200多个孩子的紧急联系人

中美未来关税战的局势将如何发展 或将迎来大结局

印巴一旦打起来后果有多严重 中国角色成关键
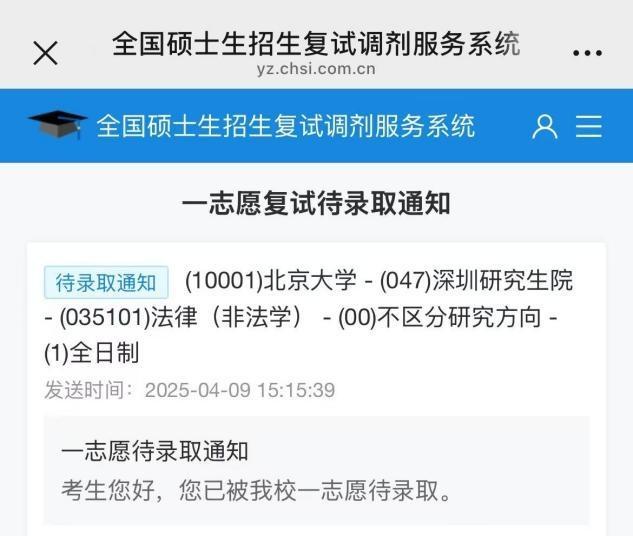
儿子瞒着父母考上北大研究生 妈妈得知后震惊 惊喜让妈妈笑醒
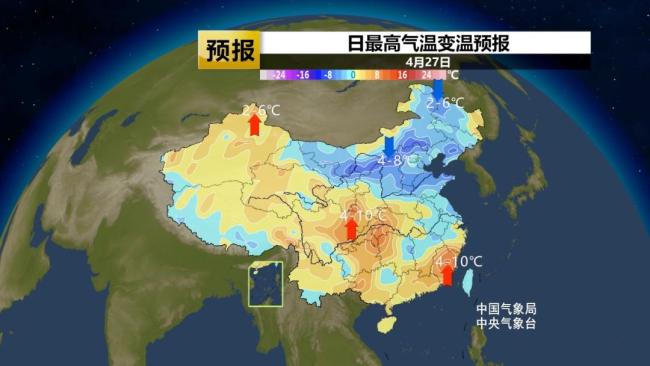
五一期间南方30℃以上区域扩张 多地将现高温天气

超市老板投资赚千万全给员工 兑现承诺分享幸福

47岁刘烨现身上海,暴瘦成纸片人!此前已许久未在公众视野露面 硬汉男神判若两人

董明珠“海归间谍论”引起争议 海归价值再审视

美国对乌不愿接受领土让步感到愤怒 会谈破裂引发关注

印度未通知开闸泄洪,巴基斯坦多地水位大幅上升面临洪灾风险

看似周日,实则周一!

伊朗最大港口爆炸是以色列干的吗 事件蒙上神秘面纱

普京为何匆忙宣布库尔斯克解放 胜利日临近压力大

马斯克称5月起工作重心将转回企业 专注特斯拉项目

南方人更爱泡影院!男性电影观众占比反超女性 华中成“观影卷王”

出现在上海小区的狐狸已死亡 身份成谜引发讨论

航拍中国黄岩岛绝美风景 碧海蓝天诗意画卷

特朗普:让加拿大加入美没开玩笑 言论引发争议

美国严格执行人类清除计划 芬太尼提案引争议

菲律宾能选出亲华总统吗?中美都在等结果

太揪心!浙江高速突发,高速交警嘶吼喊话司机:“别睡,家人在等你!”
相关新闻
DeepSeek发布新论文 梁文锋是共创 NSA机制革新长文本处理
2025-02-18 20:31:32DeepSeek发布新论文梁文锋是共创英伟达创满血DeepSeek推理世界纪录 性能显著提升
英伟达在NVIDIA GTC 2025上宣布,其NVIDIA Blackwell DGX系统创下DeepSeek-R1大模型推理性能的世界纪录
2025-03-20 09:03:59英伟达创满血DeepSeek推理世界纪录DeepSeek崛起对AI芯片行业有何影响 推动推理芯片需求增长
中国人工智能初创公司DeepSeek发布的大模型对美国的人工智能生态系统产生了显著影响,尤其是使芯片巨头英伟达的市值在一夜之间大幅缩水。然而,对于较小规模的人工智能公司来说,这反而带来了扩大业务的机会
2025-02-08 09:31:04DeepSeek崛起对AI芯片行业有何影响DeepSeek利好哪些AI基建产业链环节 推理需求增长带动新机遇
DeepSeek震动硅谷,其高性价比的训练技术引发了市场的广泛关注
2025-02-02 11:44:50DeepSeek利好哪些AI基建产业链环节黄仁勋揭秘下一代芯片Rubin,英伟达想要吃“DeepSeek红利” 推理时代的新机遇
2025-03-19 12:03:54黄仁勋揭秘下一代芯片RubinDeepSeek评价Manus AI新黑马崛起
2025年3月6日,中国AI领域迎来了一款名为Manus的通用型AI Agent产品,这款由国内团队Monica.im打造的“数字大脑”迅速在网络上引起轰动
2025-03-07 12:11:05DeepSeek评价Manus