AI大牛卡帕西盛赞DeepSeek 强化学习展现巨大潜力

AI大牛卡帕西盛赞DeepSeek!近日,OpenAI联合创始人、前特斯拉AI总监安德烈·卡帕西在YouTube上发布了一则3.5小时的免费课程,向普通观众全面介绍了大模型的相关知识。他以最近爆火的DeepSeek-R1为例,详细讲解了强化学习技术路径的巨大潜力。
卡帕西指出,在大模型训练体系中,预训练、监督微调和强化学习是三个主要阶段。他认为强化学习是其中最关键的一环,尽管其本质是“试错学习”,但在选择最佳解决方案和提示词分布等方面仍有许多细节需要解决。这些问题目前仅限于各大AI实验室内部,缺乏统一标准。
DeepSeek-R1的研究论文首次公开讨论了强化学习在大语言模型中的应用,并分享了这项技术如何使模型展现出推理能力。卡帕西认为R1在强化学习过程中涌现出的思维能力是最令人难以置信的成效。未来,如果继续在大模型领域对强化学习进行扩展,有望让大模型解锁像AlphaGo那样的“神之一手”,创造出前所未有的思考方式,例如用全新语言进行思考。但前提是需要创造足够大且多样的问题集,让模型能够自由探索解决方案。
强化学习的基本工作方式是让模型在可验证的问题上不断试错,并根据答案正误激励正确行为,最终引导模型提升能力。当前主流的大语言模型训练体系包括预训练、监督微调和强化学习。预训练和监督微调已发展成熟,而强化学习仍处于早期阶段。DeepSeek-R1论文的重要意义在于它是第一篇公开讨论强化学习在大语言模型应用的论文,激发了AI界使用RL训练大语言模型的兴趣,并提供了许多研究结果和技术细节。
DeepSeek在R1论文中展示了R1-Zero在AIME竞赛数学问题上的准确性提升过程。随着强化学习步骤增加,模型准确性持续上升。更令人惊喜的是,模型在这一过程中形成了一套独特的解题方法,倾向于使用更多token来提高准确性。R1在强化学习过程中展现了所谓的“aha moment”,即通过尝试多种想法从不同角度解决问题,显著提升了准确率。这种解决方式类似于人类解决数学问题的模式,但不是靠模仿或硬编码,而是自然涌现的。R1重新发现了人脑的思维过程,自学了思维链(CoT),这是RL应用于大语言模型时最令人难以置信的成效。

女子按摩肩颈后急性脑梗死进了ICU

《仁心俱乐部》,笑着笑着就默泪了 医生的笑与泪

意甲:尤文2-0完胜维罗纳 图拉姆破门 库普梅纳斯建功 尤文豪取5连胜

特朗普再言“忍不了”泽连斯基 争执未停歇

村民家中煤气罐泄漏喷火 消防出手 厨房用火需谨慎

泰国政府研究建隔离墙 探讨边境管控新措施

没等大陆动手,马斯克先收了“台独”分子的饭碗

泽连斯基10年间从意气风发到憔悴 命运巨变

赖因德斯:能在来到米兰一年半之后续约 我真的很自豪 感激与期待未来

中方谈美国鼓动他国对华加税 贸易战无赢家

美再次对华加征10%关税 中方坚决反对 强烈不满美方威胁
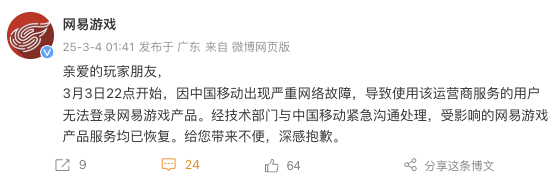
网易游戏发文致歉 网络故障已解决

阿诺拉奥斯卡最佳原创剧本 五项大奖闪耀颁奖夜

特朗普:对泽连斯基不会再忍了 美乌关系紧张升级

大V:乌克兰将面临三大严峻情况 盟友或成幕后推手
女子按摩肩颈后急性脑梗死进了ICU

巴菲特罕见发声 关税或引发通胀

陈晓离婚后状态 首次公开露面精神饱满

外媒称特朗普上任后欧盟和中国走近 大国博弈新篇章

外卖员雪天路边睡着 误会解开身体无恙
《仁心俱乐部》,笑着笑着就默泪了 医生的笑与泪

外交部驳斥鲁比奥涉华言论 回击冷战思维

专家:美加征汽车关税想“一石三鸟” 盟友反弹强烈
意甲:尤文2-0完胜维罗纳 图拉姆破门 库普梅纳斯建功 尤文豪取5连胜

中国空军赴哈瓦那看望古巴飞行员老爷爷 温暖的双向奔赴

泽连斯基发视频感谢美国 白宫会晤风波后示好

是否会向乌克兰派遣维和部队?中方回应 支持和平解决危机

阚清子被曝怀孕后现身机场 孕后状态成焦点

金价大跳水入手即亏 金饰价格断崖式下调

特朗普确认对加墨征收关税 美股重挫 市场恐慌情绪升高

巴格拉姆空军基地被中国接管?阿富汗驳斥美方 情绪化言论遭批

美乌谈崩 北约或成最大输家 美国两党内斗外溢

欧洲提出的俄乌和平方案能实现吗 欧洲挺身而出争夺主导权
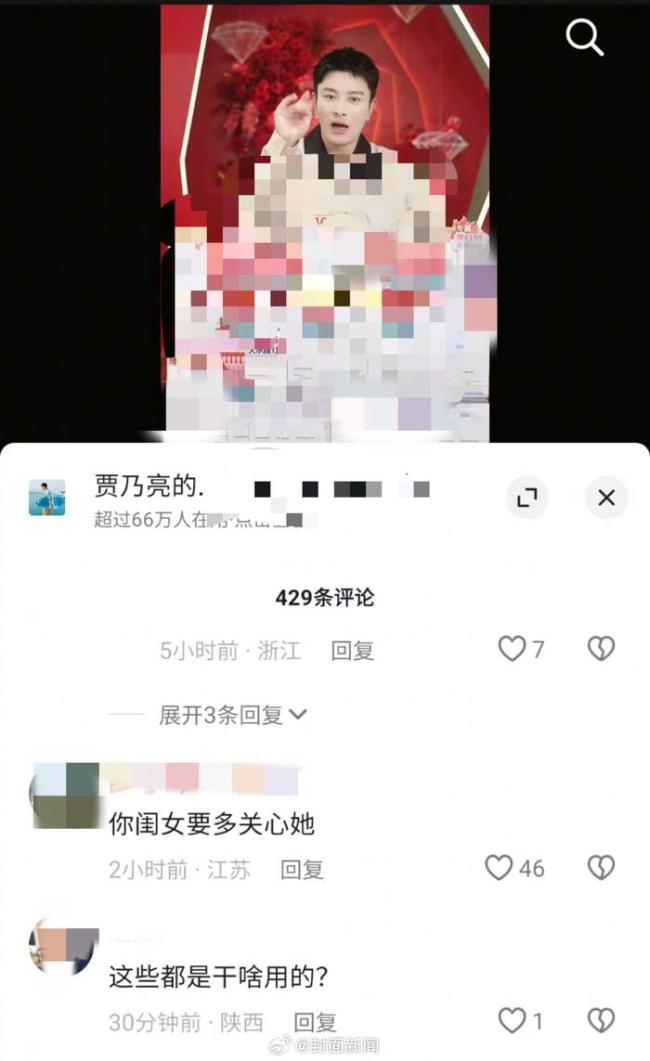
网友留言贾乃亮多关心甜馨 重视女儿心理健康
一男子全家六人患肠癌:兄妹7人5人确诊肠癌
相关新闻
广东省委书记盛赞DeepSeek 边缘AI迎来新机遇
2025-02-05 21:50:33广东省委书记盛赞DeepSeekDeepSeek爆火的启示 AI算命成新宠
最近,社交平台上涌现出大量关于AI算命的讨论。以DeepSeek为代表的AI算命在年轻人中掀起了一股热潮,成为他们在应对婚恋、职场等压力时的“救命稻草”
2025-02-16 19:52:04DeepSeek爆火的启示分析:DeepSeek开启AI的iPhone4时刻 智能手机AI大战升级
2025年将是AI商业化落地的重要一年,智能手机行业的竞争尤为激烈。苹果CEO库克曾表示,在已开放使用Apple Intelligence技术的国家内,iPhone 16系列销量更高
2025-02-25 21:09:04分析DeepSeek爆火:AI正在“杀死”公司 改变全球AI竞赛格局
我们需要更多的DeepSeek。过去几年里,中国大模型从业者们经常被问及中国距离追上ChatGPT还有多远。2025年初,这个问题有了新的答案
2025-02-21 17:49:36DeepSeek爆火DeepSeek时代的“生存指南” 正视AI的力量
十年后,当人们回望2025年时,或许会感慨这一年是时代的转折点。宇树科技的机器人在春晚上惊艳亮相,随后国产AI大模型DeepSeek诞生,并迅速应用于深圳福田区政务系统,提升了公文处理效率和准确率
2025-02-22 00:15:12DeepSeek时代的生存指南DeepSeek启动“开源周” 推动AI技术革新
DeepSeek今日宣布启动“开源周”,首个开源的代码库为Flash MLA,这是针对Hopper GPU优化的高效MLA解码内核,专门对可变长度序列进行了优化,目前已投入生产
2025-02-24 18:17:43DeepSeek启动开源周







