Nature连发三篇文章聚焦DeepSeek 低成本高性能引关注

最近,来自中国杭州的初创公司深度求索(DeepSeek)发布了两款大语言模型,在全球科技界引起广泛关注。这两款模型性能可与美国科技巨头开发的主流工具相媲美,但研发成本和所需算力却大大降低。
2025年1月20日,DeepSeek发布了部分开源的“推理”模型DeepSeek-R1,该模型能够解决一些科学问题,水平接近OpenAI于2024年底发布的GPT-o1。几天后的1月28日,DeepSeek又推出了Janus-Pro-7B,这是一款根据文本提示生成图像的模型,其性能与OpenAI的DALL-E 3以及Stability AI的Stable Diffusion相当。
国际顶尖学术期刊Nature在其官网连续发布了三篇关于DeepSeek的文章。1月29日的文章提到,科学家们纷纷涌入DeepSeek,从AI专家到数学家再到认知神经学家,他们对DeepSeek-R1的高性能和低成本感到惊叹。次日的文章则强调,DeepSeek-R1执行推理任务的水平与OpenAI的GPT o1相当,并且向研究人员开源,相比之下,OpenAI推出的GPT o1及最新成果o3基本上都是黑匣子。
DeepSeek-R1的成本也令人印象深刻。尽管DeepSeek尚未公布训练DeepSeek-R1的全部成本,但据估计,其算力租赁费用约为600万美元,而Meta公司训练Llama 3.1 405B的算力是其11倍,训练成本超过6000万美元。此外,使用DeepSeek-R1界面的用户只需支付运行ChatGPT o1费用的不到三十分之一。DeepSeek还创建了DeepSeek-R1的迷你“蒸馏”版本,以便算力有限的研究人员也能使用该模型。
另一篇文章分析了中国如何创造出震惊世界的AI模型DeepSeek,指出政策支持、大量资金以及众多AI专业人才帮助中国企业建立了先进的大语言模型。国内研究人员表示,这家初创企业的成功在意料之中,符合政府成为全球人工智能领导者的雄心。中国科学院计算技术研究所副所长陈云霁研究员指出,鉴于中国在开发大语言模型上的巨额投资和大量博士人才,像DeepSeek这样的公司在中国出现是不可避免的。
事实上,阿里巴巴也在1月29日发布了迄今为止最先进的大语言模型Qwen2.5-Max,称其性能优于GPT-4o、DeepSeek-V3以及Llama-3.1-405B。上周,月之暗面联合字节跳动发布了新的推理模型Kimi 1.5和Kimi 1.5 1.5-pro,在某些基准测试中的表现优于GPT-o1。

罗马诺:阿森纳尚未决定是否永久签下斯特林 枪手正专注于剩余比赛 未来仍不确定

罗马诺:阿森纳在斯凯利和恩瓦内里的续约上取得不错的进展 图赫尔看好两人未来

18涨停大牛股,停牌核查 股价严重偏离基本面
罗马诺:阿森纳尚未决定是否永久签下斯特林 枪手正专注于剩余比赛 未来仍不确定

库尔斯克决战在即,乌军掌握顿巴斯低空优势,欲断俄军前线补给 机械化突击行动升级

缅甸政府军与德昂军进行会谈期间,瑙丘地区战事激烈,会谈期间战火未息

辽篮两将离开国家队绝非坏事 杨鸣终于等来他想要的:调整与机遇并存

记者应该怎么用DeepSeek 真帮手还是挖坑侠?

乌方不承认美俄谈判达成协议,强调自身主权立场

DeepSeek后又一杭州企业被美国盯上 杭州科创企业再遭美国打压!

马斯克曝光美国公务员薪资细节 引爆“数据核弹”
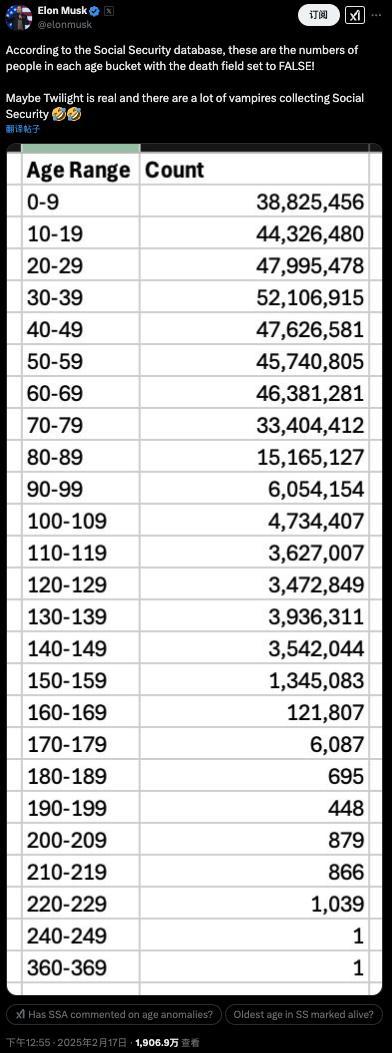
马斯克查账美国社保称发现360岁老人 马斯克曝光美国社保系统惊人漏洞

马斯克为何敢整治美政府部门 AI引领政府效率革命

95岁爷爷拄着拐杖给孙女送菜

“重大转变”!俄罗斯与北约演习!外媒:白宫首次明确表态,乌将获准坐在桌旁 乌克兰参与和平谈判

乌克兰代表团抵达沙特 为泽连斯基访问做准备

专家:泽连斯基欲铲除波罗申科 为选举清除障碍

美国务卿改口径 短暂删除“不支持台独”引发争议
迪丽热巴旗袍造型好清新 绿意盎然显气质

美国客机机身翻覆已造成15人受伤 恶劣天气成事故主因
18涨停大牛股,停牌核查 股价严重偏离基本面

又被刘晓庆圈粉了!
罗马诺:阿森纳在斯凯利和恩瓦内里的续约上取得不错的进展 图赫尔看好两人未来

台名嘴:特朗普面对中国无计可施

前马竞青训教练:巴里奥斯被罚下是因为犯错,但我们应保护他 支持年轻模范球员

“一年雨水看雨水”今年雨水多不多?春雨贵如油

未来驰援国足 国青?17岁华裔新星世界波斩澳超首球!本人愿归化 潜力无限待绽放

巴尔德:对伊尼戈的犯规明显是点球 裁判争议再现

男性1.5米就能参军,色盲也能报名,台军新征兵标准有多离谱

已查处400余个饺子导演高仿号!片方:只有微博账号是真的

美国为何盯上乌克兰稀土资源 地缘博弈与资源攫取

巴萨重回西甲榜首 莱万点射助力登顶

记者买7件100%羊绒衫 实际1根羊绒都没有

外电:欧洲人“只是自己命运的旁观者” 无力参与谈判决策

新一轮以旧换新多地多重buff拉满 消费热潮再起
相关新闻
Nature:世界科学家涌向DeepSeek 廉价强大模型引关注
2025-01-31 11:45:58NatureDeepSeek梁文锋谈选人标准 聚焦年轻高潜人才
最近,DeepSeek在全球范围内引起了广泛关注。这家公司成立于2023年5月,尽管员工规模仅一百多人,却成功开发出了备受瞩目的DeepSeek-R1模型。这一成就与创始人梁文锋的人才策略密切相关
2025-02-17 17:19:36DeepSeek梁文锋谈选人标准中国科学家当选Nature年度十大人物 CAR-T疗法突破
2024年12月9日,《自然》公布了2024年度十大人物,其中包括两位中国科学家:海军军医大学第二附属医院风湿免疫科主任医师徐沪济和中国科学院国家天文台研究员、嫦娥六号任务工程副总设计师李春来
2024-12-11 23:05:06中国科学家当选Nature年度十大人物实测DeepSeek做奥数题写作文 DeepSeek火爆全球
2025-01-27 20:13:31实测DeepSeek做奥数题写作文DeepSeek在自动驾驶中有何优势 车圈刮起“DeepSeek风”
2025-02-18 06:34:40DeepSeek在自动驾驶中有何优势专家在Nature发文揭示葛根素减肥原理 脑肠轴的秘密
2024-09-13 11:35:08专家在Nature发文揭示葛根素减肥原理








