DeepSeek突围奥秘曝光,一招MLA让全世界抄作业!150 天才集结,开出千万年薪 5万块GPU助力创新

DeepSeek近期的一系列动作,尤其是其模型的发布,迫使OpenAI在深夜紧急推出了o3-mini。过去半个月里,中国AI公司在国内外媒体上频频亮相,影响力持续上升。关于DeepSeek的模型训练数据、GPU用量、成员构成以及强化学习算法等细节,成为了公众关注的焦点。
SemiAnalysis的一篇深度报道对这些方面进行了详细推测。报道指出,DeepSeek不是简单的副业项目,其在硬件上的支出远超5亿美元。论文中提到的600万美元仅是预训练阶段的GPU成本,而研发和硬件总拥有成本并未计算在内。据估计,DeepSeek拥有约5万块Hopper GPU,包括特供版H800和H20,并且有150名员工,其中不乏来自北大、浙大的顶尖人才,优秀候选人的年薪可高达934万元人民币。
DeepSeek的一个关键创新是多头潜注意力机制(MLA),这一技术显著降低了推理成本。V3模型性能超越了R1和o1,而谷歌的Gemini 2.0 Flash Thinking与R1不相上下。此外,H100的价格因V3和R1的发布而猛涨,体现了杰文斯悖论的作用。
幻方量化作为DeepSeek的主要投资者,早期就看到了AI在金融领域之外的巨大潜力。2021年,他们购入了1万块A100 GPU,随后在2023年成立了DeepSeek,专注于推进AI技术发展。目前,两家公司在人力资源和计算资源方面保持密切合作。
DeepSeek在人才招聘上注重实际能力和求知欲望,经常在北京大学和浙江大学举办招聘活动。公司提供极具竞争力的薪酬待遇,优秀候选人年薪可达130万美元以上。这种灵活的人才战略使得DeepSeek能够快速扩张。
DeepSeek的成功不仅在于资金充足,还在于高效的运营模式。相较于大公司的繁琐决策流程,DeepSeek能更快地将创新理念付诸实践。他们主要依靠自建数据中心进行技术创新,这为他们在整个技术栈上提供了更大的实验空间。

加拿大客机翻转落地内部一片狼藉 恶劣天气或成因

罗马诺:阿森纳尚未决定是否永久签下斯特林 枪手正专注于剩余比赛 未来仍不确定

罗马诺:阿森纳在斯凯利和恩瓦内里的续约上取得不错的进展 图赫尔看好两人未来

18涨停大牛股,停牌核查 股价严重偏离基本面
罗马诺:阿森纳尚未决定是否永久签下斯特林 枪手正专注于剩余比赛 未来仍不确定

专家:泽连斯基欲铲除波罗申科 为选举清除障碍

台名嘴:特朗普面对中国无计可施

“一年雨水看雨水”今年雨水多不多?春雨贵如油

记者买7件100%羊绒衫 实际1根羊绒都没有

记者应该怎么用DeepSeek 真帮手还是挖坑侠?

缅甸政府军与德昂军进行会谈期间,瑙丘地区战事激烈,会谈期间战火未息

美国务卿改口径 短暂删除“不支持台独”引发争议

又被刘晓庆圈粉了!

新一轮以旧换新多地多重buff拉满 消费热潮再起

DeepSeek后又一杭州企业被美国盯上 杭州科创企业再遭美国打压!
罗马诺:阿森纳在斯凯利和恩瓦内里的续约上取得不错的进展 图赫尔看好两人未来

男性1.5米就能参军,色盲也能报名,台军新征兵标准有多离谱

库尔斯克决战在即,乌军掌握顿巴斯低空优势,欲断俄军前线补给 机械化突击行动升级
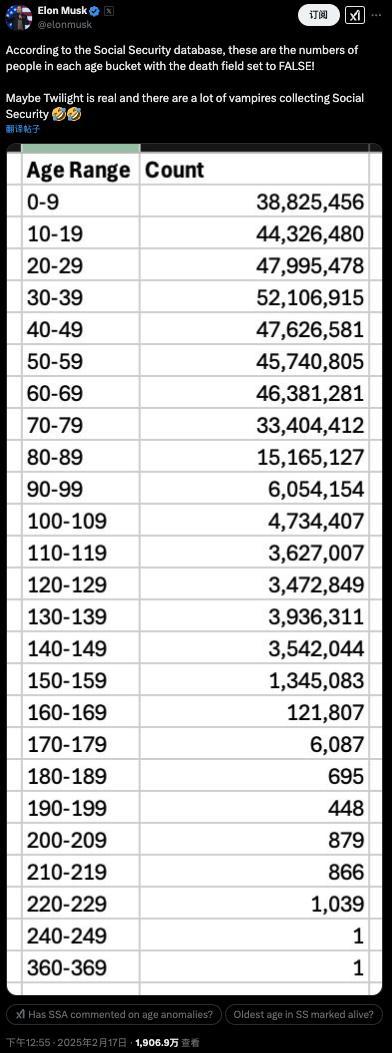
马斯克查账美国社保称发现360岁老人 马斯克曝光美国社保系统惊人漏洞

95岁爷爷拄着拐杖给孙女送菜

已查处400余个饺子导演高仿号!片方:只有微博账号是真的

外电:欧洲人“只是自己命运的旁观者” 无力参与谈判决策

马斯克曝光美国公务员薪资细节 引爆“数据核弹”

美国客机机身翻覆已造成15人受伤 恶劣天气成事故主因

前马竞青训教练:巴里奥斯被罚下是因为犯错,但我们应保护他 支持年轻模范球员

未来驰援国足 国青?17岁华裔新星世界波斩澳超首球!本人愿归化 潜力无限待绽放

美国为何盯上乌克兰稀土资源 地缘博弈与资源攫取
迪丽热巴旗袍造型好清新 绿意盎然显气质

乌克兰代表团抵达沙特 为泽连斯基访问做准备
加拿大客机翻转落地内部一片狼藉 恶劣天气或成因

乌方不承认美俄谈判达成协议,强调自身主权立场

马斯克为何敢整治美政府部门 AI引领政府效率革命

“重大转变”!俄罗斯与北约演习!外媒:白宫首次明确表态,乌将获准坐在桌旁 乌克兰参与和平谈判

巴萨重回西甲榜首 莱万点射助力登顶

巴尔德:对伊尼戈的犯规明显是点球 裁判争议再现
相关新闻
DeepSeek出圈 概念股曝光 AI大模型引爆市场
数据是宝贵的资源,能够帮助投资者减少烦恼。中国AI大模型市场正快速发展。近日,量化巨头幻方量化旗下公司DeepSeek发布了推理大模型DeepSeek-R1
2025-01-27 09:33:36DeepSeek出圈概念股曝光DeepSeek梁文锋实习往事曝光!浙大校友高薪特聘
日前,“今日闵行”公众号发布了一篇文章,提到DeepSeek创始人梁文锋2009年曾在位于上海闵行的上海艾麒信息科技股份有限公司实习,负责的内容与人工智能相关
2025-02-11 12:38:48DeepSeek梁文锋实习往事曝光震动科技界!AI领域“黑马”,DeepSeek出圈,概念股曝光 性能比肩顶尖模型
中国AI大模型市场规模正在快速发展。近日,量化巨头幻方量化旗下公司DeepSeek发布了推理大模型DeepSeek-R1
2025-01-27 08:58:14震动科技界实测DeepSeek做奥数题写作文 DeepSeek火爆全球
2025-01-27 20:13:31实测DeepSeek做奥数题写作文DeepSeek在自动驾驶中有何优势 车圈刮起“DeepSeek风”
2025-02-18 06:34:40DeepSeek在自动驾驶中有何优势地下700米粒子捕手 探索中微子奥秘
工人正在安装中心探测器的不锈钢网架网壳部分。建设中的江门中微子实验中心探测器展示了其壮观景象,工人们在不锈钢网架上进行施工。中微子是构成物质世界的基本粒子之一,也是宇宙中最常见的粒子
2024-10-25 10:34:19地下700米粒子捕手