华尔街研究:DeepSeek是AI末日吗 市场恐慌被指过度

春节期间,DeepSeek新一代开源模型以低成本和高性能引发热议,在全球投资界引起广泛关注。市场上甚至有说法称DeepSeek仅用500万美元就复制了OpenAI,认为这将给整个AI基础设施产业带来重大影响。
对此,华尔街知名投行伯恩斯坦在详细研究DeepSeek的技术文档后发布报告称,这种市场恐慌情绪明显过度。“500万美元复制OpenAI”的说法是市场误读。实际上,这500万美元仅仅是基于每GPU小时2美元的租赁价格估算的V3模型训练成本,并未包括前期研发投入、数据成本以及其他相关费用。
伯恩斯坦认为,虽然DeepSeek的效率提升显著,但从技术角度看并非奇迹。即便DeepSeek确实实现了10倍的效率提升,这也仅相当于当前AI模型每年的成本增长幅度。目前AI计算需求远未触及天花板,新增算力很可能会被不断增长的使用需求吸收,因此对AI板块保持乐观。
关于DeepSeek发布的两大模型V3和R1,伯恩斯坦进行了详细分析。V3模型采用专家混合架构,用2048块NVIDIA H800 GPU、约270万GPU小时达到了可与主流大模型媲美的性能。V3模型结合了多头潜在注意力技术和FP8混合精度训练,使得其在训练时仅需同等规模开源模型约9%的算力,便能达到甚至超越其性能。例如,V3预训练仅需约270万GPU小时,而同样规模的开源LLaMA模型则需要约3000万GPU小时。
MoE架构每次只激活部分参数,减少计算量;MHLA技术降低内存占用,提升效率;FP8混合精度训练在保证性能的同时,进一步提升计算效率。伯恩斯坦认为,与业界3-7倍的常见效率提升相比,V3模型的效率提升并非颠覆性突破。
DeepSeek的R1模型通过强化学习等创新技术,显著提升了推理能力,使其能够与OpenAI的o1模型相媲美。此外,DeepSeek还采用了“模型蒸馏”策略,利用R1模型作为“教师”,生成数据来微调更小的模型,这些小模型在性能上可以与OpenAI的o1-mini等竞争模型相媲美。这种策略不仅降低了成本,也为AI技术的普及提供了新的思路。
伯恩斯坦认为,即便DeepSeek确实实现了10倍的效率提升,这也仅相当于当前AI模型每年的成本增长幅度。在“模型规模定律”不断推动成本上升的背景下,像MoE、模型蒸馏、混合精度计算等创新对AI发展至关重要。根据杰文斯悖论,效率提升通常会带来更大的需求,而非削减开支。该行认为,目前AI计算需求远未触及天花板,新增算力很可能会被不断增长的使用需求吸收。基于以上分析,伯恩斯坦对AI板块保持乐观。

暴雪《守望先锋》国服明日回归!中国主题四大天王皮肤来了 国服专属福利揭晓

章昊直播时模仿徐冬冬姿势

波兰外长:在黄油和枪炮间很难选择 欧洲需加强国防开支
媒体批特朗普又一次“抢劫”台湾 美国的真实意图暴露

杨丞琳晒婚纱照 低调婚礼一周年

邻居直播大衣哥唱歌涨粉三百多万 大衣哥为躲网暴者爬梯子翻墙见儿子

中国男篮与日本男篮比赛前瞻 关键一战牵动人心

广西首个第四代住宅亮相南宁 户户有私家园林

伊朗:反对外国势力干涉叙利亚 支持叙人民自决权

特朗普批波音:总统专机怎么还没造好 项目拖延引不满

宇树科技创始人王兴兴曾差点没考上高中 从内向少年到科技领军人物
马斯克坐实AI游戏工作室计划 让游戏再次伟大

外媒:以色列内阁投票确认扎米尔为下任以军总参谋长 即将于3月5日就职

陈晓陈妍希将共同抚养孩子 和平分手引热议

美国翻脸后,欧洲从“夸夸其谈的少年”走向独立成熟要做三件事 应对三大危机
美俄谈判今日开始 泽连斯基:不承认 乌克兰缺席引发争议

泽连斯基将到访沙特 不参与美俄会谈

卡塞米罗:必须继续欣赏C罗或者梅西和内马尔 他们在另一个世界 足球传奇永不落幕

曾被雷军千万年薪挖角!亲属称罗福莉与丈夫研究领域相同
波兰外长:在黄油和枪炮间很难选择 欧洲需加强国防开支

美客机翻覆现场视频曝光 恶劣天气或成事故主因
暴雪《守望先锋》国服明日回归!中国主题四大天王皮肤来了 国服专属福利揭晓

中医劝你春季养好脾胃 调养脾胃祛风除湿

合作导演称饺子上下班照常骑自行车 低调健康生活典范

美为何提议从中国向乌派遣维和人员 美国的奇葩主意

美方:乌克兰能“上桌”谈判 欧洲被排除引发争议

22日起哪吒2港澳地区全面上映 两地首映仪式相继举行

网传小学老师因末位淘汰轻生 真相尚在调查中
章昊直播时模仿徐冬冬姿势
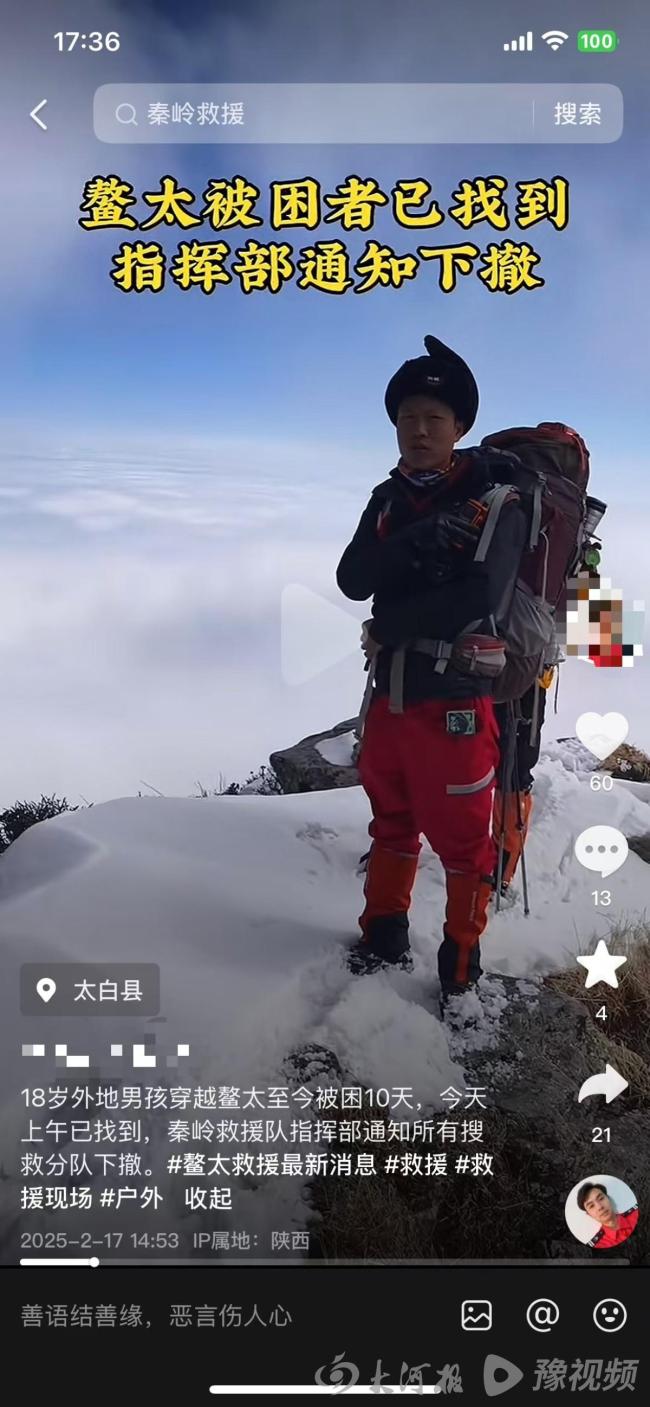
18岁男孩非法穿越鳌太线获救 救援行动再启

沪指半日涨0.29% 四大行再创新高 银行股逆势走强
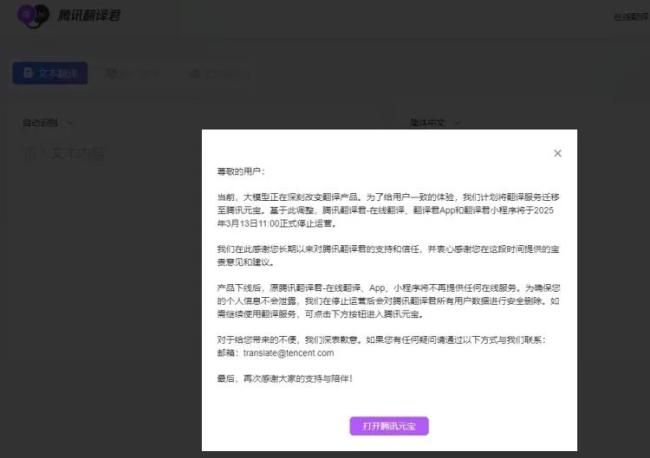
突然宣布:腾讯一产品即将停止运营 服务迁移至腾讯元宝

拉夫罗夫抵达沙特 单手揣兜下飞机 谈判桌上的博弈

大V:欧洲和乌克兰遭受三次沉重打击 西方暴露三大问题

特朗普批波音总统专机还没造好 项目拖延引不满
相关新闻
华尔街交易商大量囤金 华尔街交易商争相将黄金运往纽约
2025-02-07 11:37:30华尔街交易商大量囤金实习生,月薪14w 了 华尔街新宠儿
好消息往往来自别人家公司。去年年初,一家名为Jane Street的量化交易机构给实习生开出了1.6万美元(约合人民币11万元)的月薪。那时,这家公司在华尔街还未声名鹊起
2024-11-07 09:43:11实习生月薪14w了华尔街缘何开始上调美股预期
华尔街缘何开始上调美股预期当下,美股开启了一轮“特朗普行情”,营商环境的改善及盈利扩张预期下,标普500指数一度突破6000点重要心理关口。
2024-11-19 13:42:30华尔街缘何开始上调美股预期美元升至两年高位 华尔街一致看涨
2024-11-13 13:50:53美元升至两年高位DeepSeek冲击华尔街 引发投资界重估
过去一周,DeepSeek R1、字节跳动的豆包1.5 Pro以及月之暗面的Kimi k1.5模型相继推出,引起了全球投资者的高度关注
2025-02-01 13:18:44DeepSeek冲击华尔街DeepSeek冲击 华尔街连夜变阵 引发科技股震荡
2025-02-01 10:46:48DeepSeek冲击华尔街连夜变阵