中国AI企业应如何看待英伟达新显卡 算力不再是唯一关键

中国AI企业应如何看待英伟达新显卡!1月7日上午,英伟达总裁黄仁勋在全球最大的消费电子展上发表了演讲。此前有海外科技博主预测,英伟达即将发布的新版显卡GPU性能会有显著提升。在演讲中,黄仁勋发布了英伟达RTX 50系列显卡,并表示RTX 5090的整体性能是上一代RTX 4090的两倍。

这一消息引发了担忧,特别是在美国对华断供高端芯片的背景下,中国人工智能行业可能无法获得最高性能的GPU用于训练,与美国的差距可能会进一步拉大。在人工智能领域,“算力焦虑”一直是一个热门话题。作为全球主导的GPU企业,英伟达的H100 GPU数量一度成为衡量大模型公司算力的标准,黄仁勋曾称:“英伟达是AI世界的引擎”,认为其硬件是发展人工智能大模型的关键。
然而,现场的朋友表示,算力和人工智能大模型不再是多数企业最关心的问题。2024年的重点是如何将人工智能落地应用,这并不一定需要最高性能的GPU芯片。相比之下,黄仁勋在演讲中强调英伟达“Blackwell架构芯片是人类历史上最大的单芯片”,但同时也宣布了消费级产品的降价策略,性能不变但价格降至三分之一,这与之前的涨价预期形成了反差。显然,在面临越来越多挑战的情况下,英伟达也在寻求多元化的发展路径。
实际上,全球几家全力投入人工智能大模型研发的头部企业正在掀起一股“去英伟达”的趋势。例如,Open AI和苹果公司等开始自研芯片和生态系统,以支持自身的大模型训练。这种趋势打破了英伟达宣传的“算力为王”的观念。除了自研AI芯片,这些公司还在更多地关注大模型本身的设计优化。
Mistral AI公司公开引入混合专家模型进行大模型训练,用多个特定领域的“小专家”配合几个“通用专家”,先决定问题类型再处理不同类型的问题。此外,DPO、LoRA等高效微调方法也简化了模型对齐过程,降低了复杂度。在这种趋势下,国产大模型逐渐明确了发展方向。2024年,国产大模型取得了显著进展,有些通过底层优化,仅用2048块GPU就达到了头部公司数万块GPU训练才具备的大模型性能。
在中国工业互联网研究院的数据中,DeepSeek-V3通过采用混合精度方法,有效平衡了训练精度和效率,结合混合专家模型架构,将大模型训练成本降低至500万美元,仅为同性能模型的5%~10%,而性能却与GPT-4o和Claude 3.5 Sonnet相当。目前,国内类似的大模型成本和训练时长都大幅下降。这种新的训练方法不仅降低了大模型行业的门槛,还推动了全球大模型的降价潮,对人工智能技术的应用和转化具有革命性意义。
业内人士指出,在当前全球人工智能大模型的竞争中,算力虽然重要,但不是决定性因素。只有与软件和应用场景结合起来,才能真正赋能行业转型,提高经济效率。部分人工智能项目存在“假智能”的问题,即靠大量数据叠加出答案,缺乏真正的创造力和想象力。尽管一些前沿大模型探索了“思维链”,试图模拟人类思维推导,但在实现“通用人工智能”方面仍有较大障碍。
更大的问题是,仅靠算力的方式迟早会遇到瓶颈。现有大模型已经读完了几乎所有的英文书籍,接下来的发展方向必须回到技术本质,解决更关键的方向性问题。中国企业正通过高效灵活的路径,找到更加“聪明”的人工智能发展方向。人工智能是一场向着未知的探险,中国企业选定的方向不会轻易被各种“焦虑”裹挟。中国AI企业应如何看待英伟达新显卡!

山寨俄罗斯商品馆遍地开花 真假难辨引发关注

专家:特鲁多下台意味着什么 中加关系有望改善

吃人家的嘴短?内马尔也说沙特联强于法甲 认可C罗观点

特朗普就职后改革能成功吗

还能这么玩?巴萨奥尔莫问题有人“全力相助”,规避失去风险 反对派质疑管理
专家:特鲁多下台意味着什么 中加关系有望改善
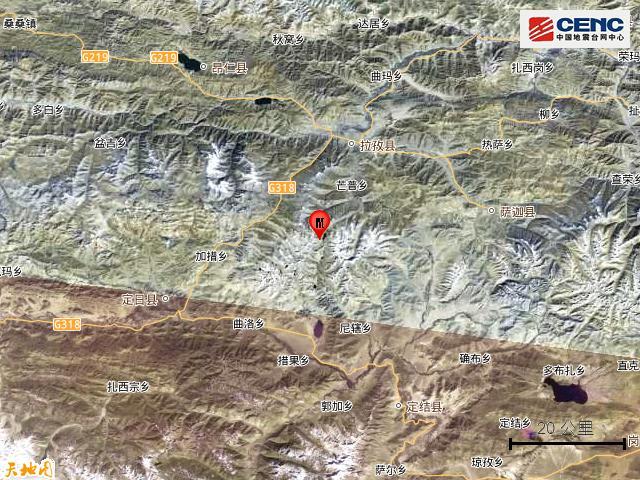
西藏日喀则拉孜县发生3.8级地震 震源深度10千米

重磅!世界首富马斯克有意收购利物浦 Grok建议引援方向

蓝营青年谈柯建铭为何突喊“双罢” 绿营内斗外溢

中国人也参与了“黑洞”的命名,但最终“灵魂画手”是惠勒
山寨俄罗斯商品馆遍地开花 真假难辨引发关注

历史上首次!拜登被日本知名企业正式起诉 指控非法干涉收购案

神奇!屏幕能拉长,伸手就收回 联想CES发布卷轴屏电脑 创新显示技术引领未来

比亚迪向西藏捐赠1000万 助力灾后重建
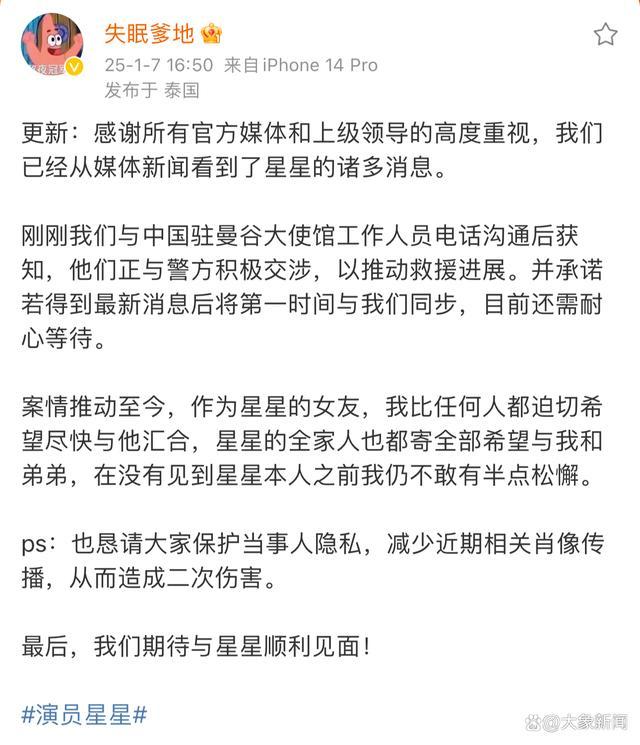
女友发文恳请保护王星隐私 减少肖像传播避免二次伤害

泰警察总署署长搭特快专机接星星 确认找到并接回

成飞沈飞的六代机动力是什么?
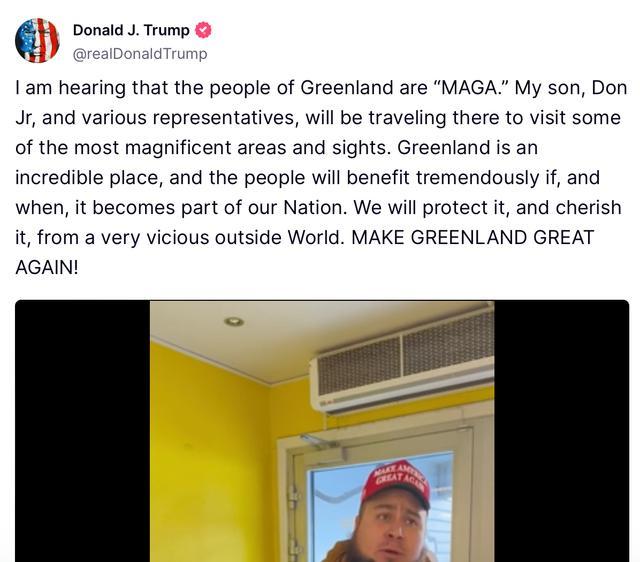
特朗普称要让格陵兰岛再次伟大 购岛意愿再起

中国船员被绑至缅甸 家属遭勒索10万元 家属焦急寻人

泰国总理确认王星已找到 泰方谨慎处理减少影响

静态体验领克900 豪华配置尽享科技

美媒:2025年五角大楼瞄准15个关键技术,包括航天器、生物化学等领域 战略资本助力国防科技

中国科技巨头被美列“军工名单” 中方回应 坚决反对美方制裁举措
吃人家的嘴短?内马尔也说沙特联强于法甲 认可C罗观点

王星称被关在有50个中国人的建筑内 机智勇敢获救

西藏地震已致126人遇难188人受伤 救援行动紧急展开

中国船员疑赴泰国后失联被绑至缅甸 家属急寻线索
高通宣布近十项新合作 拓展汽车科技布局

运20飞往西藏日喀则地震灾区 抗震救灾进行时

黄仁勋:Blackwell已全面投入生产,性能提升四倍
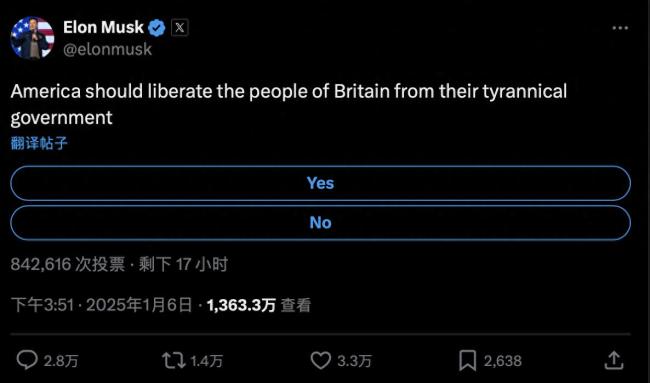
马斯克民调:美应解放英吗
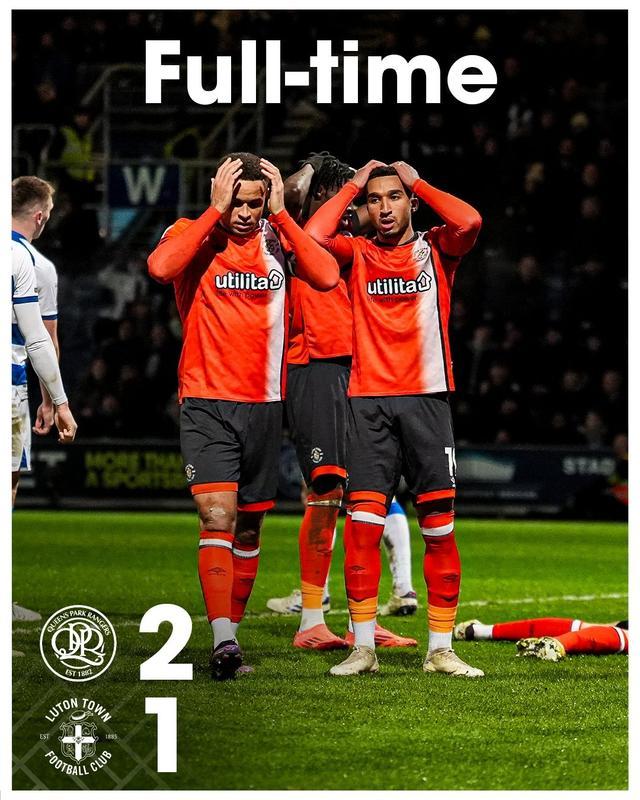
踢完英超晕了!卢顿全队身价1亿英冠第5,6轮5负仅高降级区2分 保级警报再响
贾玲以李焕英名义向西藏灾区捐款 明星齐心援助

林允儿去年停止活动的原因 身体需要调整休息

退休教授将生前积蓄捐给母校 一生为教育
相关新闻
英伟达市值一夜蒸发2万亿元 分析师仍乐观看待AI前景
2024-09-04 08:08:12英伟达市值一夜蒸发2万亿元英伟达将被纳入道指 AI重要性增强
标普道琼斯指数公司宣布将英伟达纳入道琼斯工业平均指数,取代英特尔。同时,Sherwin-Williams Co. 将取代陶氏化学。分析人士指出,这一调整反映了人工智能和高性能计算的重要性日益增强
2024-11-02 10:43:00英伟达将被纳入道指黄仁勋:英伟达正在打造“AI大脑” 引领新工业革命
英伟达首席执行官黄仁勋表示,我们正经历一场新的工业革命,这场革命的动力是人工智能。在美国奥兰多高德纳IT展览会上,他对数千名企业技术领导者强调,公司必须转型为人工智能驱动的组织,以应对这场变革
2024-10-24 14:51:00黄仁勋:英伟达正在打造“AI大脑”英伟达RTX 5090显卡功耗被曝为600W 性能飞跃代价高昂
2024-09-04 12:09:55英伟达RTX英伟达或正酝酿中国特供版AI芯片 "B20"问世在即?
2024-07-24 13:16:36英伟达或正酝酿中国特供版AI芯片英伟达宣布与软银合作 共建日本AI基础设施
11月13日,英伟达创始人兼CEO黄仁勋在英伟达日本AI峰会上宣布,将与软银合作在日本建设AI基础设施,以加速机器人、汽车、医疗保健和电信行业的发展
2024-11-14 09:05:37英伟达宣布与软银合作