显卡可能没那么重要了?中国公司给硅谷好好上了一课 新年惊喜震撼西方(4)

首先,V3通过通信和显存优化,极大幅度
减少了资源空闲率
,提升了利用效率。
而推理专家
(具备推理能力的AI系统或算法,能够通过数据分析得出结论)
的负载均衡就更巧妙了,一般的大模型,每次启动,必须把所有专家都等比例放进工位
(显存)
,但真正回答用户问题时,十几个专家里面只用到一两个,剩下的专家占着工位
(显存)
摸鱼,也干不了别的事情。
而DeepSeek把专家分成热门和冷门两种,
热门的专家,复制一份放进显存,处理热门问题;冷门的专家也不摸鱼,总是能被分配到问题
。
FP8混合精度训练则是在之前被很多团队尝试无果的方向上拓展了新的一步,通过降低训练精度以降低训练时算力开销,但却神奇地保持了回答质量基本不变。
也正是这些技术上的革新,才得到了大模型圈的一致好评。

通过一直以来的技术更新迭代,DeepSeek收获的回报也是相当惊人的。
他们V3版本推出后,他们的价格已经是
低到百万tokens几毛钱、几块钱
。
他们甚至还在搞了个新品促销活动,到明年2月8号之前,在原来低价的基础上再打折。
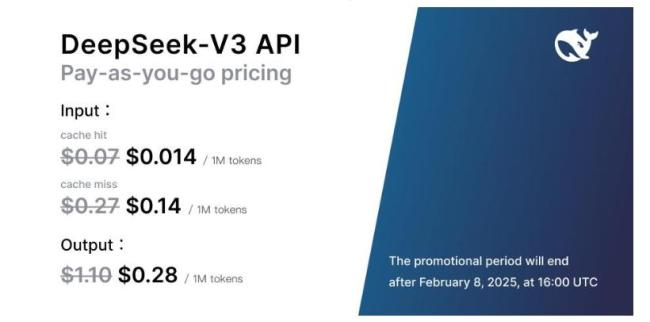
而一开始提到同样开源的 Claude 3.5 Sonnet ,每百万tokens,至少都得要几十块以上。。。
更要命的是,这对DeepSeek来说已经是常规套路了。
早在去年初,
DeepSeek V2 模型发布后,就靠着一手低价,被大家叫做了AI 界拼多多。
他们还进一步
引发了国内大模型公司的价格战,
诸如智谱、字节、阿里、百度、腾讯等大厂纷纷降价。
池光耀也告诉我们,他们公司早在去年6、7月份就开始用上了DeepSeek,当时也有国内其他一些大模型厂商来找过他们。
但和DeepSeek价格差不多的,模型
“又太笨了
,
跟DeepSeek不在一个维度
”;如果模型能力和DeepSeek差不多,那个价格“
基本都是10倍以上
”。
更夸张的是,由于技术“遥遥领先”带来的降本增效,哪怕DeepSeek卖得这么便宜,根据他们创始人梁文峰所说,
他们公司还是赚钱的
。。。是不是有种隔壁比亚迪搞998,照样财报飘红的味道了。
不过对于我们普通用户来说,DeepSeek似乎也有点偏门了。
因为他的强项主要是在推理、数学、代码方向,而多模态和一些娱乐化的领域不是他们的长处。

而且眼下,尽管DeepSeek说自己还是赚钱的,但他们团队上上下下都有股极客味,所以他们的商业化比起其他厂商就有点弱了。
但不管怎么说,DeepSeek的成功也证明了,在AI这个赛道还存在的更多的可能。
按以前的理解,想玩转AI后面没有个金主爸爸砸钱买显卡,压根就玩不转。
但现在看起来,掌握了算力并不一定就是掌握了一切。
我们不妨期待下未来,更多的优化出现,让更多的小公司、初创企业都能进入AI领域,差评君总感觉,那才是真正的AI浪潮才对。

专家称未来十年提高居民收入只有靠服务业

篮网GM:DFS的交易不到半天就达成了 湖人积极促成

王慧玲为什么被封号

俄乌士兵近身肉搏画面罕见曝光 匕首牙齿齐上阵
一个人值几十万!中国人在缅北被“交易” 电诈园区的黑暗真相

小麦“疯”涨!1月3日最新行情! 涨价空间有限

WTT官方致敬马龙:当之无愧的GOAT!奥运6金王 生涯35冠 传奇永续新章

工作人员回应十二生肖图有猫无蛇 古代习俗差异引发热议

除了戴头盔,2025年1月起,电动车、三轮车上路迎来“7个新要求” 新规全面升级

男子自编自演5元卖地铁座位被行拘 虚假信息博关注

乌称首次用海上无人艇击落俄直升机 开创海空作战新方式

5个关键词直击尹锡悦逮捕令执行全程 宪政史首次对峙

“海洋侦探”号,交付! 新年开门红

韩国空难遇难机长哥哥的亲笔信
专家称未来十年提高居民收入只有靠服务业
篮网GM:DFS的交易不到半天就达成了 湖人积极促成

尹锡悦写信感谢总统府外的支持者

韩国对总统警卫处长等人立案调查 因妨碍公务执行

一名前俄罗斯国脚死在乌克兰的故事 从球场到战场的悲剧转变

博主:塞尔吉尼奥乘坐的航班已抵京,一名00后中卫接近加盟国安 新援助力阵容升级

普京低调访问华盛顿?俄方辟谣

赵明剑谈当年离开泰山队原因 1.6亿转会费揭秘
王慧玲为什么被封号

马斯克震怒:开特斯拉炸特朗普酒店的居然是特种兵 疑为恐怖袭击事件

全红婵希望大家多关注跳水 感谢支持与认可

石破茂做了一个反常选择,日本对中国拿出诚意,中方会给这个面子 中日互信与合作前景

曝赵薇从未和黄有龙回湖南老家 离婚消息引发热议

美媒曝光:特朗普通话记录被窃取 美军士兵涉嫌参与黑客攻击

张一山发自拍疑回应暴瘦传闻 敷面膜翻白眼逗乐网友

中国篮协发布2025年竞赛日历 优化赛事安排

青岛皇家美孚辟谣“倒闭” 紧急回应澄清传闻

俄乌士兵近身肉搏画面罕见曝光!
美一飞机与鹰相撞 鹰受伤被安乐死 航班因鸟击返航

尹锡悦律师团进入总统官邸 调查合法性受质疑

波音当下困境比911时刻还要黑暗!
相关新闻
美国的一场飓风 可能要把显卡干涨价了
国庆假期结束后,人们或许还未从休假状态中完全恢复,而此时美国正遭受飓风“海伦”的严重影响。这场飓风横扫多个州,导致大面积停电、洪水泛滥,据报道,伤亡人数已达到数百
2024-10-09 10:02:29美国的一场飓风全红婵说这届金牌没那么重了 心态更成熟
8月6日,巴黎奥运会跳水赛场传来喜讯,中国选手全红婵在女子10米台决赛中成功卫冕,为中国队摘得该项目连续第五块奥运金牌。比赛结束后,全红婵接受了总台记者的现场采访
2024-08-07 10:46:29全红婵说这届金牌没那么重了女生在森林公园上班工作是巡山:很满意,班味没那么重
00后女孩谦谦在云南普洱太阳河森林公园工作,她在网上发布了与白眉长臂猿的日常互动,引发众多网友点赞。
2024-07-12 10:39:07女生在森林公园上班工作是巡山首款国产游戏显卡!摩尔线程MTT S80显卡降至1299元
6月17日,正值618购物节的高潮阶段,国产游戏显卡MTT S80在促销活动中推出了特别优惠。这款由摩尔线程推出的产品,成为了零售市场上首个国产游戏显卡的代表
2024-06-20 14:04:59首款国产游戏显卡!摩尔线程MTT显卡说涨价就涨价!英伟达全球GPU市场占比90%:AMD、英特尔没存在感 垄断地位愈发稳固
英伟达在GPU市场的主导地位持续增强,人们期望AMD和Intel能展现出更强的竞争力
2024-12-13 15:38:56英伟达全球GPU市场占比90%英特尔预告 12 月 3 日公布“显卡大消息”,预计发布锐炫 B 系列独立显卡 公版显卡即将亮相
英特尔官方X平台账户Intel Gaming于11月30日发布动态,预告将在12月3日公布一些关于显卡的重要消息。预计届时将发布锐炫B系列"Battlemage"独立显卡
2024-12-02 10:07:02英特尔预告 12 月 3 日公布“显卡大消息”