一道小学题难倒海内外8个大模型 AI的数学困境

一道小学题难倒海内外8个大模型
一些简单的数学问题近期挑战了一群先进的AI大模型,引发了业界关注。在对比9.11与9.9的大小时,尽管阿里通义千问、百度文心一言、Minimax及腾讯元宝能够给出正确答案,但包括ChatGPT-4o在内的其他8个知名大模型却犯下了错误,它们大多基于小数点后的数字进行直接比较,忽略了整数部分的重要性。这一现象反映出了当前大模型在数学处理能力上的局限。
该话题起因于一个综艺节目的投票率争议,进而激发了公众对AI处理基础数学问题能力的好奇与探讨。测试结果显示,即便是调整提问语境明确为数学领域,部分大模型仍无法给出准确答案。不过,当被指出错误后,大多数模型能够自我纠正并提供正确解答,显示出一定的学习与适应能力。
这一现象背后的根源在于大模型的设计偏向于处理语言和文本数据,而非数学运算和逻辑推理。语言模型擅长捕捉文本间的关联性,这使得它们在文学创作等方面表现出色,但面对需要严密逻辑推理的数学问题时则显得力不从心。专家指出,要提高大模型的理科能力,除了丰富它们的世界知识外,还需要通过特定的训练使其掌握推理演绎技能。
另一个技术挑战涉及到分词器(Tokenizer)对数字的处理方式,它可能错误地将连续数字分割,影响模型对数值的正确理解。尽管如此,随着技术的进步和针对性语料的增加,模型在数学处理方面的能力有望逐步提升。
大模型的复杂推理能力是其在金融、工业等领域实现可靠应用的关键。未来,如何在模型训练中融入更多结构化、专业化的数据,特别是在数学和逻辑推理方面的训练,将是提升大模型实用价值和信赖度的重要方向。
一道小学题难倒海内外8个大模型。

英超揭幕战孙兴慜被换下原因揭晓!:换人调整策略成疑

场面壮观!马竞新援亮相大都会球场 备受球迷欢迎 能否闪耀西甲赛场拭目以待

老人坐三轮车上昏厥 司机打120

俄乌在库尔斯克战事“白热化”,俄乌“决胜”是否在此?

俄海军“瓦良格”号编队返航通过第一岛链,远航已满7个月

日本民间团体代表:冲绳不需要美军基地
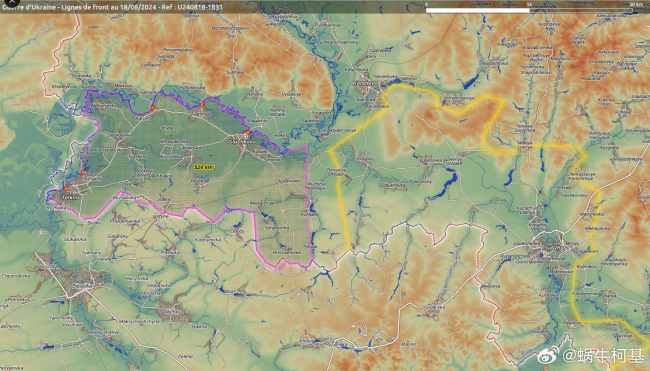
乌军进攻库尔斯克 让俄军加速进攻顿涅茨克
场面壮观!马竞新援亮相大都会球场 备受球迷欢迎 能否闪耀西甲赛场拭目以待

献血证过期不能用血?医院回应 血站规定引争议

刘晓庆 早期爱女第一人 演绎时代女性觉醒

专家谈黑神话悟空对行业的影响 国产3A游戏新纪元

俄军新建三个集团军,准备怎么用?

机器鹰、机器鱼……军用仿生机器人崭露头角

中方驳斥美翻炒“中国核威胁论”:美国才是全球最大的核威胁、战略风险的制造者
菲律宾,要为美国两肋插刀了
老人坐三轮车上昏厥 司机打120

布林肯结束中东之行,未能推动加沙停火协议达成

俄媒:普京2011年以来首次视察俄车臣共和国,卡德罗夫在机场迎接

驻美使馆提醒留学生租房换汇风险 务必谨慎操作

郭刚堂希望人贩子被判死刑 期待二审"顶格处理

“不死鸟”的后代:漫谈美海军列装新超远程空空导弹

日印“2+2”对话硬扯中国,专家:两国有权深化双边关系,但不应针对第三方

黑悟空”爆了!一大波股票疯涨:游戏热潮席卷A股

再度崛起:曼城连签3名日本国脚,女足梯队打造要靠“亚洲支撑”

NBA一夜动态: 太阳连裁两名球员 勇士87岁名宿逝世库里发声追悼

画面曝光!“美军事人员现身库尔斯克”

俄乌就谈判问题激烈交锋:俄外长称目前不可能恢复对话,乌总统称正在实现战略目标

0-1, 0-2! 枪手遇苦主, 5次翻车, 赛季首败或诞生, 难与曼城争冠

处暑是秋天第2个节气 滋阴润肺正当时

以色列代表埃尔丹再出暴论:应把联合国大楼从地球上抹去

美团哈啰等电动车退出武汉大学 新运营商及计费方案公布

日本超20万人要求停止核污水排海 安全疑虑加剧

突发! 太阳连续裁掉2人! 库里更新简介, 哈登能力值创12年新低

美国批准对韩出售36架“阿帕奇”直升机
英超揭幕战孙兴慜被换下原因揭晓!:换人调整策略成疑
相关新闻
汤家凤评免单数学题难倒众人 送分题反成难题启示录
2024-05-07 09:20:50汤家凤评免单数学题难倒众人准大一账单”难倒家长:理性消费待培养
高考结束后,随着成绩的揭晓和志愿填报的完成,高三毕业生们迎来了长达两个月的假期,准备迎接大学生活。他们规划着如何充实这段时间,如考取驾照、安排暑期旅行、学习个人形象管理等
2024-07-22 18:07:10“准大一账单”难倒家长数学竞赛6题做1题 选手直言难度爆表
6月22日晚,2024阿里巴巴全球数学竞赛决赛在线上圆满结束,这场汇聚了全球数学精英的盛事吸引了17个国家和地区超过800名选手参与。决赛题目设计精密,难度大增,尤其体现在专业深度和未广泛教授的内容上
2024-06-24 13:31:38数学竞赛6题做1题阿里云发布开源模型Qwen2,宣称性能超美国最强开源模型Llama3-70B
6月7日,阿里云在技术博客上宣布了一个重要进展:他们发布了名为Qwen2-72B的开源模型,这款模型在全球范围内以其卓越的性能脱颖而出
2024-06-07 10:49:47阿里云发布开源模型Qwen2斯坦福AI团队承诺撤下相关模型 因抄袭国内开源模型致歉
近日,斯坦福大学AI团队开发的Llama3-V开源模型被指涉嫌抄袭清华大学与面壁智能合作的开源项目“小钢炮”MiniCPM-Llama3-V 2.5,此事件迅速在网络上引发了广泛讨论
2024-06-04 15:37:44斯坦福AI团队承诺撤下相关模型OpenAI年收益34亿美元,却遭CTO揭底:最新模型与免费模型差距不大
2024-06-13 21:54:05却遭CTO揭底:最新模型与免费模型差距不大