周鸿祎称大模型不是万能 不要觉得有了GPT就能裁员了(2)

但是,当我们带着通用大模型真正走进政府、城市、行业、企业时就会发现,公有大模型无法直接使用。因为公有大模型存在以下四点不足:
第一,公有大模型虽然是通才,但它缺乏行业深度。我们之前认为GPT什么都会,但如果你是一个行业专家,你会发现GPT在安全、金融这些垂直领域,知识深度是不够的。很多公司自己训大模型都发现了这个特点,想让它能力很均衡,就会牺牲深度。所以未来垂直大模型是重要的发展方向,通用模型和各领域专有的知识数据结合,让大模型从“万事通”变成政府通、行业通和企业通,这才是真正的价值。最新资料表明,GPT4也是由8个垂直模型组成的,从侧面印证了这个观点。
第二,公有大模型容易造成企业内部数据泄露。一方面,公有大模型不是本地部署,它与外部进行信息交流时必然存在数据泄露的风险;另一方面,公有大模型也无法实现组织内部权限的分级管理。因此,政府、企业使用公有大模型必然存在安全风险。
第三,对企业来讲,公有大模型无法保障内容真正可信。这主要包含两个问题:一个是企业在日常生产经营过程中,知识库是实时产生的,并且不断变化。它不像公有大模型的通用知识,是一成不变的“百科全书”。因此,企业使用公有大模型无法满足时效性的需求。另一个是大模型自身的“幻觉”问题,也就是我们常说的一本正经地“胡说八道”。公有大模型经常出现张冠李戴的问题,需要通过企业的内部搜索、内部知识库进行矫正。这些都需要专有大模型才能实现。
第四,也是很多企业级用户关注的,公有大模型无法实现成本可控。举个例子,很多企业其实只需要大模型写代码的能力,这时候公有大模型写诗、写论文的能力就是多余的。也就是说,很多企业只需要百亿级垂直大模型就满足需求,如果使用千亿级大模型就是成本的浪费。这个成本不只是大模型的采购成本,还包括训练成本、部署成本、微调成本。在控制成本方面,垂直大模型将会有很大优势。因此,在一个用公开数据训练的“通识”大模型基础上,训练专有大模型,就能做到“事半功倍”,为企业降本增效。

就是“舔”!张雪峰称所有文科专业都叫服务业 惊爆言论引发网友争议

用人单位倒闭退休怎么办?官方解读

一图读懂 流感流行季来了 现在接种疫苗晚不晚?

广东男篮官宣:易建联9号球衣12月29日退役

美国和台湾地区军事联系加强,中方该如何应对?解放军将领答记者

马克龙:反对“双标”对待巴以
胡锡进:德驻华大使馆爆粗口拉低国格

孙女说抑郁了奶奶回复霸气又暖心:不开心就不出去 奶奶有钱给你花

宁波和爷爷奶奶在车棚住11年的女孩有了自己房间
就是“舔”!张雪峰称所有文科专业都叫服务业 惊爆言论引发网友争议

巴勒斯坦总统阿巴斯:以色列政府越过所有红线,应得到惩罚

货车司机在解清帅寻子海报标注已回家

以色列的“有限地面进攻”包含哪些手段?
一图读懂 流感流行季来了 现在接种疫苗晚不晚?

他成了所有学生的“公敌”,还因此融到了350万美金

台积电放弃进驻桃园,被绿营说成“被市长赶走”,桃园市政府反驳

欧盟外长:不要“双标”,以色列停止向加沙供水违反国际法

马来西亚总理:挺巴勒斯坦会激起西方“反弹风险”,但我别无选择

王健林到底多缺钱?连曾经的首富都吃不消了

郑州最高气温破1991年以来同期纪录!持续强冷空气来袭未来将迎大幅降温

91岁老人生日给5个子女每家5万红包

泰国新任防长:潜艇搁置 改买中国护卫舰

玩脱了!南方女孩在东北舔铁舌头被冻住 朋友边笑边浇热水解救

加沙燃料告急 联合国救济机构或停止运作

崔天凯:美方提出“小院高墙”,让人想起“坐井观天”

“杰森·斯坦森在汽车机盖上贴巴勒斯坦国旗”视频疯传,土媒:说法不实

以色列总理:将全速推进战事

巴以冲突11天逾30万名儿童被迫离开家园 沙地带卫生部门称医疗资源已将枯竭

袁娅维居然免费请粉丝看首唱会,姐是什么神仙

酷炫!电力局用激光炮修剪树枝火遍全网 研发公司回应:视频里加了特效

必须支持联合国在巴以问题上发挥更大作用
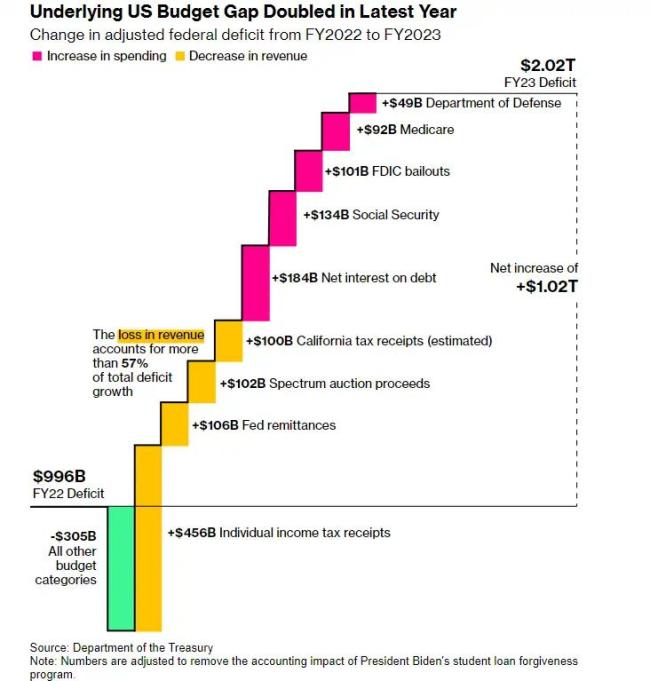
美财政轨迹掀起恐慌潮,2万亿美元的赤字将成新常态?
用人单位倒闭退休怎么办?官方解读

辟谣!大衣哥朱之文否认在北京买豪宅:我没有搬离朱楼村
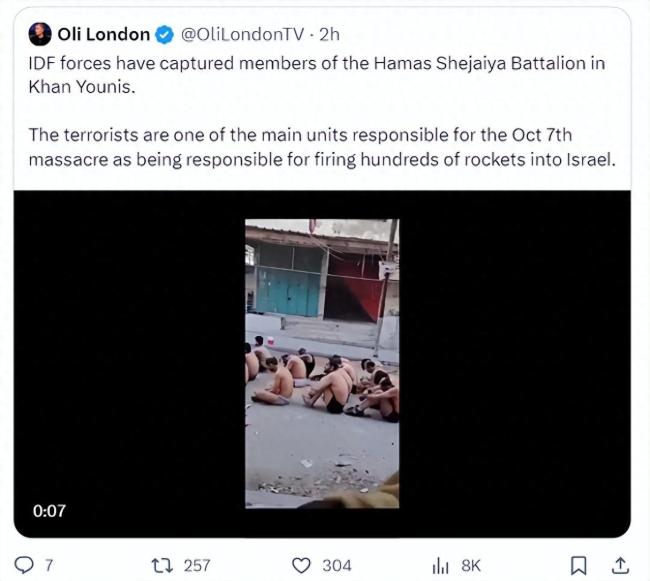
海水漫灌逼出大批哈马斯投降是真吗?视频真实性遭网友质疑
相关新闻
尼山对话聚焦人工智能 周鸿祎:垂直大模型大有可为
中国经济网曲阜6月26日讯(记者李方)6月26日,世界互联网大会数字文明尼山对话在山东济宁曲阜开幕。
2023-06-26 17:50:45尼山对话聚焦人工智能周鸿祎评价ChatGPT 大模型的发展刚刚开始,不会被OpenAI一统江山
“十年前,互联网企业来到乌镇常说的是消费互联网,现在更多谈工业互联网、产业互联网。未来人工智能将大行其道,过去我们谈互联网+,以后应该是AI+。
2023-11-10 11:33:44周鸿祎评价ChatGPT周鸿祎天价离婚案后续:4.47亿股过户 缩水逾20亿
原标题:周鸿祎天价离婚案后续已向前妻胡欢转让4.47亿股财联社6月6日消息,三六零集团创始人、董事长兼CEO周鸿祎离婚案后续又有新进展。
2023-06-07 10:01:08周鸿祎天价离婚案后续周鸿祎回应360广告多:商业模式奇葩只能依赖广告
11月28日,新东方创始人俞敏洪在个人公众号,更新了与360公司创始人、董事长兼CEO周鸿祎的采访对话。
2023-11-29 14:42:13周鸿祎回应360广告多马斯克xAI发布首款大模型:将颠覆社交媒体互动
在人工智能技术不断刷新我们对未来的想象力时,美国科技企业家埃隆·马斯克再次成为焦点。11月5日,他宣布,其引领的创新公司xAI,正式推出了名为Grok的尖端人工智能模型。
2023-11-06 14:51:30马斯克xAI发布首款大模型中国自主研发的人工智能大模型首次向公众开放服务
2023-09-03 16:51:08中国自主研发的人工智能大模型首次向公众开放服务








