小米发布机器人基座模型 刷新多项SOTA

2月12日,小米发布了开源VLA模型Xiaomi-Robotics-0。该模型拥有47亿参数,具备视觉语言理解和高性能实时执行能力,在多项仿真测试中取得了优异成绩,并在真实任务中展示了动作连贯、反应灵敏的特点,能在消费级显卡上实现实时推理。
物理智能的核心在于“感知-决策-执行”的闭环质量。为兼顾通用理解和精细控制,Xiaomi-Robotics-0采用了主流的Mixture-of-Transformers (MoT) 架构。其视觉语言大脑(VLM)负责理解人类模糊指令并从高清视觉输入中捕捉空间关系。动作执行小脑(Action Expert)则通过多层Diffusion Transformer (DiT)生成高频平滑的动作块,并利用流匹配技术确保动作精准度。
大部分VLA模型在学习动作时会失去原有的理解能力。通过多模态与动作数据混合训练,Xiaomi-Robotics-0在学会操作的同时保持了强大的物体检测、视觉问答和逻辑推理能力。VLM协同训练引入了Action Proposal机制,使VLM特征空间与动作空间对齐。随后冻结VLM,专注于训练DiT,使其能够从噪声中恢复出精准的动作序列。
针对推理延迟导致的真机“动作断层”问题,团队采用异步推理模式,让模型推理与机器人运行异步执行,确保动作连贯流畅。为进一步增强响应敏捷性和运行稳定性,引入了Clean Action Prefix和Λ-shape Attention Mask。前者将前一时刻预测的动作作为输入,保证动作轨迹连续不抖动;后者通过特殊注意力掩码,使模型更关注当前视觉反馈,提高对环境变化的反应性。
在多维度测试中,Xiaomi-Robotics-0表现出色。在LIBERO、CALVIN和SimplerEnv测试中,该模型在所有Benchmark和30种模型对比中均取得最优结果。实际应用方面,双臂机器人平台上的部署显示,无论是在积木拆解还是叠毛巾等长周期高难度任务中,机器人都能处理得游刃有余,展现出极高的手眼协调性。此外,模型还保留了VLM本身的多模态理解能力,在具身相关的Benchmark中表现尤为突出。

斯塔默:允许美国使用英方军事基地应对伊朗威胁

美军F-15战机在科威特坠毁 飞行员弹射逃生

开学啦!机器人、醒狮、英歌舞……迎生仪式花样百出,开学典礼别出心裁
开学啦!机器人、醒狮、英歌舞……迎生仪式花样百出,开学典礼别出心裁

军车鸣笛回应敬礼男孩 纯粹敬意感动网友

万斯曾说美国卷入中东纷争是因总统太蠢 乐观预测遭质疑

中国海军丝路方舟号医院船访问智利!

乌克兰真能拿到核弹吗 英法秘密援助?

黑旗升起战争升级!卫星视角看美伊开战第二日:哈梅内伊殒命,美军多个基地被袭击!

一架美军战机在科威特坠毁 飞行员弹射逃生

特朗普说伊朗许多人打电话投降 美以协同打击伊朗

至少31名伊朗运动员丧生:17岁球员遭枪击 15岁少年被狙击手杀害

朱婷狂砍20分 打出最好季后赛表现 助力球队先拔头筹
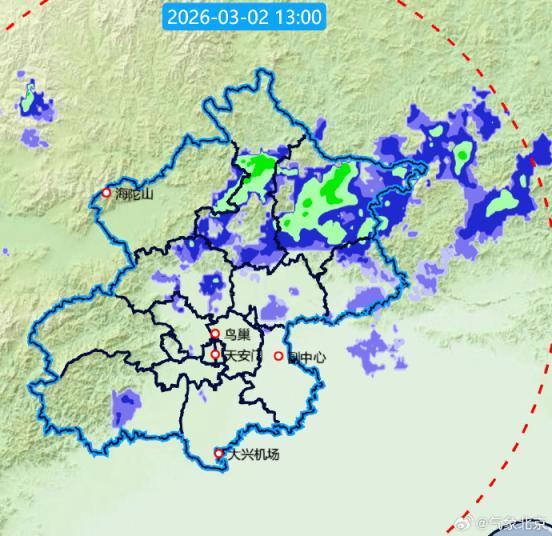
近1小时北京最大降水量在延庆区三岔口和密云区雾灵山 北部地区仍有雨夹雪

新人结婚突降大雪 亲友冒雪打伞吃席
美军F-15战机在科威特坠毁 飞行员弹射逃生

伊朗之战给世界的5个深刻教训 内奸与误判的代价

豆瓣发致歉信 运营失误致巨额损失
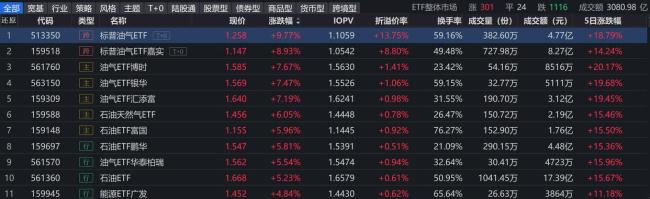
原油类ETF全线大涨 地缘冲突推高油价

男子帮朋友抓羊时猝死 家属索赔62万 善意背后的法理拷问

美中央司令部:伊方的美军伤亡数字不实 伊朗声明遭驳斥

人民币史诗级大涨背后藏着哪些机会 数据与逻辑解析

伊朗高官:绝不允许国家被分裂 团结抵御外部威胁

严惩侵害妇女权益犯罪 最高检:去年前11月起诉强奸犯罪嫌疑人2.8万人

美媒都看不下去:先开战再编理由,谁像你这样?美军基地真有那么强?

伊朗为何竟无法保护最高领袖?中东会大乱吗? 反情报与防空能力薄弱

中俄外长通话讨论伊朗局势 共商中东和平稳定之道

以军袭击黎巴嫩已致31死149伤 冲突升级引发关注

女单颁奖典礼全收录:王曼昱亚军孙颖莎卫冕夺冠 两姐妹有爱合影

马克龙翻脸如翻书!法国派遣航母赴中东

特朗普称伊军若不投降必死无疑 美以联合行动升级

大V:宗馥莉的刀刃持续向内 娃哈哈系企业大清洗

中国女排颜值女神,面对网暴不低头,父亲离世仍坚守赛场

在媒婆的帮助下相亲有了退展
斯塔默:允许美国使用英方军事基地应对伊朗威胁
相关新闻
小米发布MiMo-V2-Flash模型!
2025-12-17 13:21:17小米发布MiMo-V2-Flash模型智元机器人发布SOP模型 助力真实场景学习
2026-01-07 16:13:38智元机器人发布SOP模型黄仁勋:机器人领域迎来ChatGPT时刻 英伟达发布物理AI模型
2026-01-06 08:28:10黄仁勋机器人首次拥有时空记忆 阿里达摩院开源RynnBrain模型
阿里巴巴达摩院发布了具身智能大脑基础模型RynnBrain,并一次性开源了包括30B MoE在内的7个全系列模型
2026-02-11 09:42:50机器人首次拥有时空记忆小米入股人形机器人公司 加码智能机器人领域
2025-11-13 09:30:47小米入股人形机器人公司黄仁勋:机器人领域迎ChatGPT时刻 开源模型引领未来
2026-01-07 15:16:55黄仁勋







