DeepSeek为何坚持中文思考 汉字信息密度更高(2)

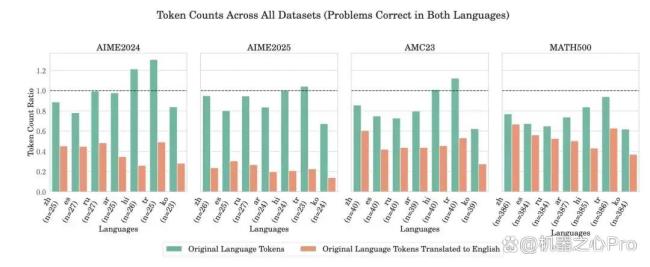
该论文评估了三个最先进的开源推理模型:DeepSeek R1、Qwen 2.5 (32B) 和 Qwen 3 (235B-A22B),问题以英语呈现,但模型被明确指示以七种目标语言中的一种执行其推理步骤。最终答案必须以英语提供,以确保评估的一致性。实验结果显示,与英语相比,使用非英语语言进行推理始终能实现 20-40% 的显著令牌降低,而且通常不影响准确性。DeepSeek R1 的 token 减少量从 14.1%(俄语)到 29.9%(西班牙语)不等,而 Qwen 3 则表现出更显著的节省,韩语的减少量高达 73%。这些效率提升直接转化为推理成本降低、延迟更低和计算资源需求降低。

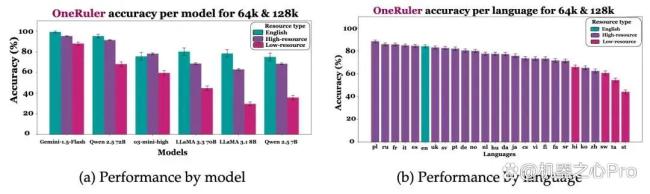
马里兰大学和微软的研究论文《One ruler to measure them all: Benchmarking multilingual long-context language models》提出了包含 26 种语言的多语言基准 OneRuler,用于评估大型语言模型(LLM)在长达 128K 令牌的长上下文理解能力。研究者们通过编写英语指令并将其翻译成另外 25 种语言构建了 OneRuler。实验表明,随着上下文长度从 8K 增加到 128K token,低资源语言与高资源语言之间的性能差距日益扩大。令人惊讶的是,英语并不是长上下文任务中表现最好的语言(在 26 种语言中排名第 6),而波兰语位居榜首。在指令和上下文语言不一致的跨语言场景中,根据指令语言的不同,性能波动幅度可达 20%。
既然中英文都不是具有最佳大模型性能的语言,那大模型选择思考语言的方式并不是完全以效率为先。评论区的第二种观点认为训练数据中包含更多中文内容更为合理。国产大模型采用更多中文训练语料,其思考过程出现中文是正常现象。类似的情况也出现在 AI 编程工具 Cursor 发布的新版本 2.0 核心模型「Composer-1」上,因为其思考过程完全由中文构成。

韩特检组寻求法院判金建希15年 涉嫌多宗罪名

部分门店将老国标电动车转二手卖 潜藏安全与法律风险

日本又玩小动作!日本立场“丝毫没有改变”!

情侣婚前先后坠楼身亡双方家属回应 赔偿争议引发热议
乐视网负债238亿拟花1.8亿炒股 持续亏损下的投资尝试

新国标“小电驴”长啥样?瘦了、贵了 新车数量少选择有限

中方坚决反对日本挑战战后国际秩序、为军国主义招魂
韩特检组寻求法院判金建希15年 涉嫌多宗罪名

被捕涉诈中国公民被分批次遣返!
钧正平:谁在为日本军国主义“招魂” 复活的幽灵再现

高市早苗最新表态还想耍滑头!

朝武装力量工程部队在俄排雷画面曝光
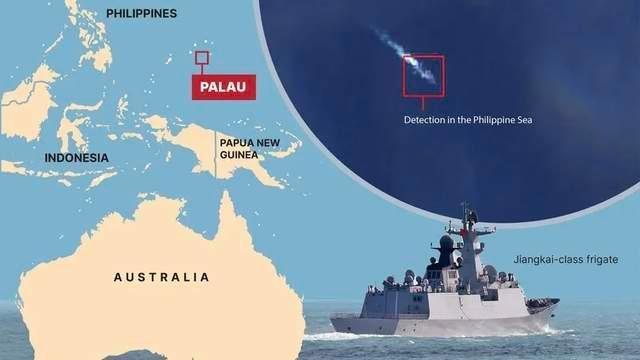
中国准航母舰队或绕澳航行 澳海军无法应对 实力悬殊引发担忧

金建希受审时双腿发软由两人搀扶 面临15年刑期及巨额罚款
日本又玩小动作!日本立场“丝毫没有改变”!

无歼击机护航时我方成功驱离外机

哈登创造生涯单场0罚球最高得分纪录 率队终结5连败

飒!新毕业女飞行员改装首飞 蓝天梦再进一步

失去亲信的泽连斯基还能坚持多久 生死抉择

日本拟打造宇宙作战集团 推进太空军事化

中俄向日本右翼政治势力发出严重警告!

日本自民党,再被告发 违规捐款引争议

日本宫古岛居民担心岛屿变战场 安全与生存的错位

日本学者:高市错误言论破坏《中日联合声明》

爱泼斯坦私人岛屿内景首次曝光 细节令人不寒而栗

日本持续推进核污染水排海!

日本着急替马克龙做决定!

美空军一F16C战机坠毁 飞行员成功逃生
部分门店将老国标电动车转二手卖 潜藏安全与法律风险

幼师“15天虐童上千次”案9日将开庭!

中国应该向巴基斯坦出口歼35吗 引发外界广泛猜测

官方通报水渠石块被指一掰就掉 砂浆强度不足问题待整改

农户用粮食画《疯狂动物城》巨幅海报 创意致敬票房佳绩

美财长拒答“是否保卫台湾” 避谈敏感问题

日本别忘了战败国的义务 正视历史履行承诺
相关新闻
黄仁勋:DeepSeek的革命性成就 开辟了代理型人工智能新领域 高效思考新时代
2025-07-18 11:20:23黄仁勋DeepSeek为何发表研究成果 揭示AI模型秘密
证券时报的文章内容仅供参考,不构成实质性投资建议,据此操作风险自担。下载“证券时报”官方APP或关注官方微信公众号,可以随时了解股市动态,洞察政策信息,把握财富机会
2025-09-20 12:51:47DeepSeek为何发表研究成果习语丨习近平为何强调“坚持正确二战史观”?
“今年是中国人民抗日战争、苏联伟大卫国战争暨世界反法西斯战争胜利80周年,也是联合国成立80周年。
2025-08-13 13:28:21习语丨习近平为何强调“坚持正确二战史观”?西班牙为何拒绝北约“军费摊派” 坚持主权决策
当地时间6月26日,西班牙首相桑切斯表示,西班牙作为一个主权国家,决定不将国防开支提升至国内生产总值的5%。他强调,西班牙会履行北约义务,但同时也保持自主权
2025-06-29 12:29:44西班牙为何拒绝北约军费摊派俞敏洪该思考为何能到南极看企鹅 员工加班困境被忽视
2025年11月16日,新东方32周年庆当天,创始人俞敏洪在南极发来一封992字的全员信,用“冰雪坚守”和“企鹅互助”大谈团队精神
2025-11-18 11:32:47俞敏洪该思考为何能到南极看企鹅霸王茶姬为何不打价格战 坚持高价值品牌战略
2025-12-01 14:25:53霸王茶姬为何不打价格战