DeepSeek新模型让硅谷“失眠” 开源阵营的“反击夜”(2)

这背后起决定性作用的,并不是简单地“模型再放大一点”,而是对底层架构的重新动刀。最典型的,就是DeepSeek在V3.2中引入的稀疏注意力机制(DSA)。
传统Transformer里,注意力需要让每个token和前面几乎所有token“打招呼”,计算量随着上下文长度呈平方级攀升,长上下文一上来,推理成本立刻飙升。DSA做的事,说白了就是:“别再对所有人一视同仁,把算力先省出来,只算真正有用的那一部分。”
为此,DeepSeek在注意力模块前加了一层“闪电索引器”(Lightning Indexer)。这个模块本身可以用极少的参数、在FP8这样的低精度下运行,负责在极短时间内做一轮粗筛,先找出与当前token最关键的一小撮上下文位置,再把主算力集中投向这部分核心token。这样一套组合拳打下来,注意力的复杂度从近乎N²,被压缩到了接近线性。
更关键的是,DeepSeek并没有一上来就用稀疏结构“硬替换”。在预训练前期,模型仍然采用标准的密集注意力,而索引器则负责在旁边“学分布”,逐步拟合原有注意力的权重模式;等到后期模型稳定后,再用稀疏结构从密集注意力手中接管大部分工作。这种“先模仿、再接管”的渐进式过渡,使得V3.2在128K甚至更长上下文下,既大幅减轻了计算压力,又没有明显牺牲精度。在Fiction.liveBench、AA-LCR等长文本基准测试中,V3.2在信息召回、上下文一致性以及压缩表达上的表现,均明显好于上一代。
如果说DSA是在“算得更经济”,那么另一个不太容易被外行察觉的关键点,则是在“怎么把每一步思考用得更值”。
在V3.2里,DeepSeek首次系统性提出了“Thinking in Tool-Use”的工具使用范式。以前大多数模型调用工具的流程,是“想一想→调工具→给答案”,调用工具像是插在思维链条中间的一块“硬隔板”。V3.2改造后的执行逻辑,则更像是“边想边调”:模型可以先推一段逻辑,再调一次工具,拿到结果后继续在原来的推理轨迹上接着想,再视情况调下一次工具……整个过程交错前进。
日本网站回应招聘抹黑中国人剧本写手 违规信息已被下架

东南亚的这轮暴雨为何这么“凶”?三百年一遇的暴击

特朗普心腹将会见乌方代表 通报莫斯科会谈情况

中方坚决反对日本挑战战后国际秩序、为军国主义招魂
北京明后两天晴朗气温回升 早晚寒冷注意保暖 午间适宜户外活动

大国五年|澎湃内需,铸就发展主锚 消费引擎强劲驱动

日本着急替马克龙做决定!

小伙埋头吃羊排头发着火还不忘点赞!

高市早苗的玩梗式营销翻车 外交场合失分寸

马克龙访华,为何去成都?:探寻合作新窗口
日本网站回应招聘抹黑中国人剧本写手 违规信息已被下架
台小学校歌唱中国人绿营破防 蒋万安回应台小学校歌唱中国人

日本宫古岛居民担心岛屿变战场 安全与生存的错位

失去亲信的泽连斯基还能坚持多久 生死抉择
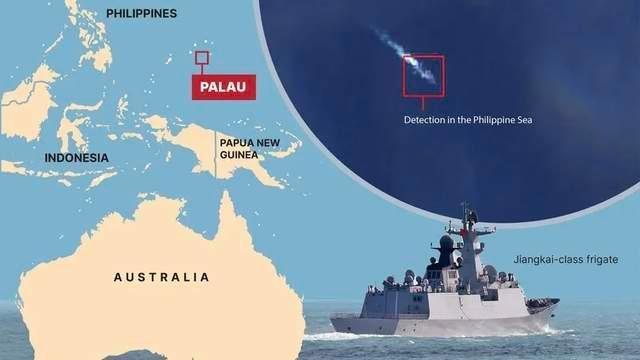
中国准航母舰队或绕澳航行 澳海军无法应对 实力悬殊引发担忧

美媒:美国议员首次公开一批爱泼斯坦私人岛屿的照片与视频

乌狙击手平原上穿着伪装衣一动不动 被俄无人机瞬间发现遭袭身亡

办公电脑里的聊天记录被公司擅自恢复,该由谁做主?

王曼昱采访结束试图钻围栏离场 王曼昱是不是忘了自己的身高
特朗普心腹将会见乌方代表 通报莫斯科会谈情况
钧正平:谁在为日本军国主义“招魂” 复活的幽灵再现

女子跟风做趾压板超慢跑脚底喷血 健身变伤身

美国若对委内瑞拉动武面临哪些问题 师出无名且代价高昂

美飞行表演队F-16坠毁背后有何原因 维护与管理挑战

埃尔多安谴责乌克兰 局势升级威胁黑海安全
我国科学家取得量子研究新进展 实现爱因斯坦思想实验

丈夫被精神病人杀害妻子忆事发过程!

很快开展陆上打击?美威胁加剧,知情人士:马杜罗每夜更换睡觉地点 局势紧张升级

日本学者:高市破坏《中日联合声明》干涉中国内政

日本持续推进核污染水排海!

黄仁勋:华为是强大的科技公司之一 中国AI技术崛起引发关注

专家提醒美国日本能重演珍珠港事件 历史不会重演
东南亚的这轮暴雨为何这么“凶”?三百年一遇的暴击

日本拟打造宇宙作战集团 推进太空军事化

女子收养流浪狗后被领着去见狗宝宝:善意被懂得,信任有了回应
相关新闻
DeepSeek推出金牌级数学模型 开源新AI模型
2025-11-28 15:47:58DeepSeek推出金牌级数学模型DeepSeek新模型有多猛 开源AI的重大突破
DeepSeek最新发布的开源数学模型DeepSeekMath-V2,在全球最难的高中数学竞赛中达到了金牌水平,成为首个实现这一成就的开源模型,标志着开源人工智能在复杂推理能力上的一次重大突破
2025-11-28 15:24:50DeepSeek新模型有多猛DeepSeek推出新模型 数学推理达IMO金牌水平
11月27日晚,DeepSeek在Hugging Face上开源了一个新模型:DeepSeek-Math-V2。这是一个数学模型,也是目前首个达到IMO金牌水平且开源的模型
2025-11-28 10:26:50DeepSeek推出新模型DeepSeek开源新模型DeepSeek-OCR 探索视觉-文本压缩边界
10月20日,人工智能团队DeepSeek AI发布了全新多模态模型 DeepSeek-OCR
2025-10-20 20:33:14DeepSeek开源新模型DeepSeek-OCRDeepSeek使用率暴跌 原因何在?新模型R2缺席影响显著
由于新模型R2迟迟未发布,DeepSeek近期备受关注。国际知名半导体研究机构Semianalysis的报告显示,DeepSeek的用户使用率从年初的7.5%峰值显著下降至3%,官网流量同期下滑近三成
2025-07-10 13:25:04DeepSeek使用率暴跌原因何在DeepSeek为何发表研究成果 揭示AI模型秘密
证券时报的文章内容仅供参考,不构成实质性投资建议,据此操作风险自担。下载“证券时报”官方APP或关注官方微信公众号,可以随时了解股市动态,洞察政策信息,把握财富机会
2025-09-20 12:51:47DeepSeek为何发表研究成果