警惕AI数据污染冲击安全防线 筑牢数据安全底座

警惕AI数据污染冲击安全防线 筑牢数据安全底座。国家安全部发布安全提示,指出人工智能训练数据存在良莠不齐的问题,其中包括虚假信息、虚构内容和偏见性观点,这导致数据源污染,给人工智能安全带来新的挑战。
数据是人工智能的基础,与算法和算力一起构成其三大核心要素。海量数据为AI模型提供了充足的训练素材,使其能够学习内在规律和模式,实现语义理解、智能决策和内容生成。高质量的数据还能驱动人工智能性能和精度的持续优化,促进模型迭代升级以适应新需求。
数据的数量、质量及多样性对AI模型至关重要。充足的数据量是充分训练大规模模型的前提;高准确性、完整性和一致性的数据能有效避免误导模型;多样化数据则能提升模型应对实际复杂场景的能力。随着数据资源日益丰富,“人工智能+”行动加速落地,促进了人工智能与经济社会各领域的深度融合,推动科技跨越式发展、产业优化升级以及生产力整体跃升。
然而,数据一旦受到污染,可能导致模型决策失误甚至系统失效,存在安全隐患。通过篡改、虚构和重复等“数据投毒”行为产生的污染数据,会干扰模型在训练阶段的参数调整,削弱模型性能并降低其准确性,甚至诱发有害输出。研究表明,即使少量虚假文本也会显著增加有害内容的比例。受污染的人工智能生成的虚假内容还可能成为后续模型训练的数据源,形成递归污染效应。互联网上的大量低质量及非客观数据导致AI训练数据集中的错误信息逐代累积,最终扭曲模型的认知能力。
数据污染还可能引发一系列现实风险,尤其在金融市场、公共安全和医疗健康等领域。在金融领域,不法分子利用AI炮制虚假信息,可能引发股价异常波动,构成新型市场操纵风险;在公共安全领域,数据污染容易扰动公众认知、误导社会舆论,诱发社会恐慌情绪;在医疗健康领域,数据污染可能导致模型生成错误诊疗建议,危及患者生命安全并加剧伪科学传播。
为筑牢人工智能数据底座,需加强源头监管,防范污染生成。依据相关法律法规,建立AI数据分类分级保护制度,从根本上防范污染数据的产生。同时,强化风险评估,确保数据在全生命周期环节的安全,并构建人工智能安全风险分类管理体系,提高数据安全综合保障能力。定期依据法规标准清洗修复受污数据,制定具体规则,逐步构建模块化、可监测、可扩展的数据治理框架,实现持续管理和质量把控。

90后女子1880公里划船去上海 勇气与毅力的见证!

不想写作业被妈妈打,男孩报警求助

一纸铁证!湘雅老病历揭露侵华日军长沙暴行

印度总理莫迪访问日本,加强双边合作 推进特别战略伙伴关系

乌克兰开放18至22岁男性离境 政策首次调整

神兽归笼,开学季学校围墙上“长满了”家长

媒体强调日本是投降而并非“终战” 历史铁证不容抹去

曝莫迪与特朗普关系恶化原因 停火声明引发外交风波

新疆小伙跨越4000公里到山东上学:一下车就感受到了德州的热情

成都蓉城登顶中超 主场大胜锁定榜首
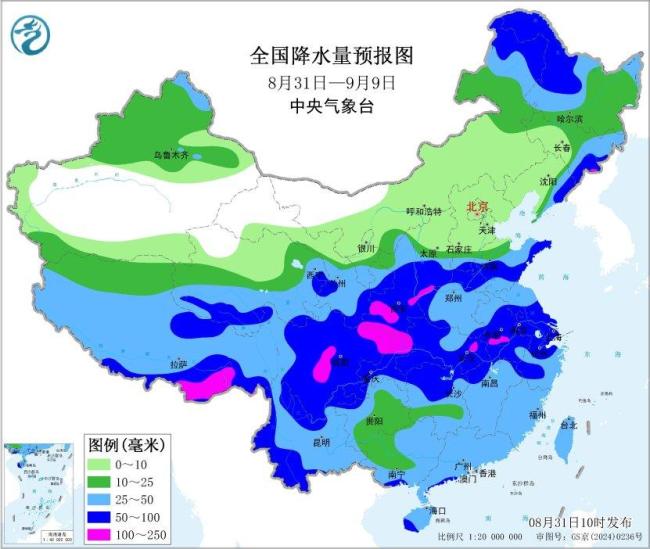
未来10天西北地区东南部黄淮多降雨 江南等地持续高温

普京访华4天两地十多场会晤 史上最强访华团

安徽首富又去IPO敲钟了 新能源赴港上市潮

麻辣女兵已上线?长春师范大学新生军训服引发网友热议 投票结果引关注

暑假作业被狗撕碎 男孩边哭边揍 孩子内心强大迅速调整

开学季包书皮打扫教室的还是那批人,80后的我们主打一个吃苦耐劳

白宫石材现"裂缝"特朗普宣布"破案" 监控揭露真相

一等功臣带着孙子到国防科大报到 薪火相传续写传奇

香港用无人机重现“日本投降矣” 光影再现历史瞬间

普京新闻秘书称赞中国菜:非常美味 上合组织峰会宴会上的亮点

菲新军事基地距台湾岛仅百余公里 巴士海峡封锁威胁

巴基斯坦总理在华表态 深化中巴全天候战略合作
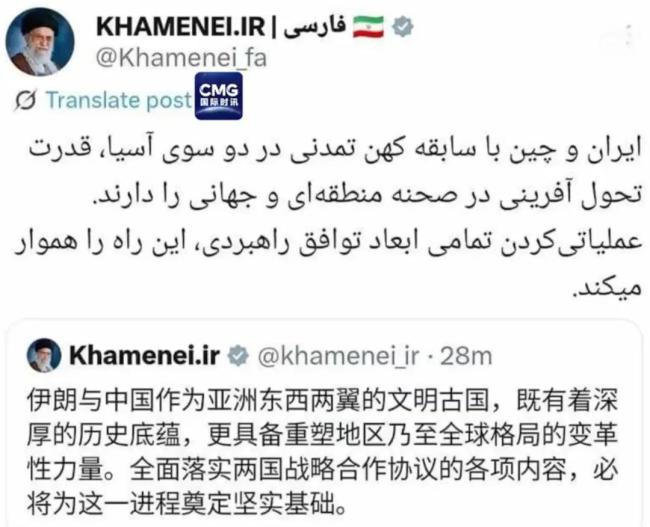
哈梅内伊中文发文谈中伊关系 重塑全球格局

特朗普宣布白宫玫瑰园裂缝“破案” 监控视频揭露真相

高校迎新有多卷 机器人当“迎宾” 科技改变迎新现场
不想写作业被妈妈打,男孩报警求助
一纸铁证!湘雅老病历揭露侵华日军长沙暴行
90后女子1880公里划船去上海 勇气与毅力的见证!

以色列“斩首”胡塞面临挑战 反击能力惊人

李在明访美 140分钟谈成了什么 一场外交冷遇

莫迪拉着普京的手进入上合峰会大厅 地缘政治赛点显现

两名外卖小哥挡下偷车贼 正义不会缺席
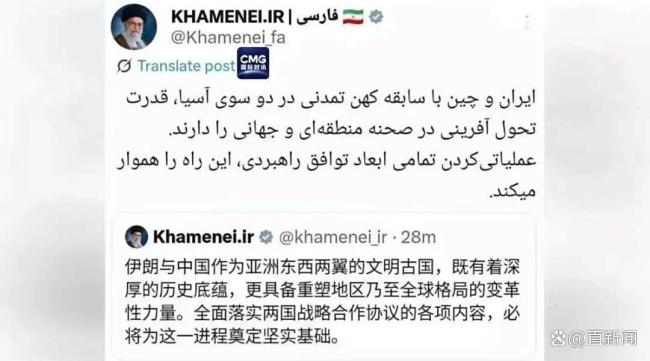
哈梅内伊为什么罕见用中文发帖 强调中伊合作重要性

湖北两车疑斗气导致车祸,警方通报

普京今天至少有五场双边会见 代表团阵容庞大
相关新闻
警惕AI数据污染引发现实风险 信息真伪难辨
2025-08-17 08:47:31警惕AI数据污染引发现实风险国安部:警惕人工智能“数据投毒” 筑牢数据安全防线
2025-08-05 10:27:13国安部警惕零日漏洞“定时炸弹” 数字安全防线告急
2025-08-25 09:02:58护网|警惕零日漏洞定时炸弹刘庆峰谈“AI幻觉”带来的数据污染 大模型胡编乱造引担忧
AI幻觉是指大模型在生成内容时容易胡编乱造,有时甚至足以以假乱真,或者出现“AI运算偏差”,产生与现实不符的内容。科技博主阑夕的一篇文章《DeepSeek的胡编乱造,正在淹没中文互联网》引起了广泛关注
2025-03-07 06:36:37刘庆峰谈AI幻觉带来的数据污染顶流AI,人设崩了,6小时被攻破,泄露高危品指南,惨遭网友举报 安全防线形同虚设
2025-06-10 08:56:53顶流AI媒体:别被你的AI忽悠了 警惕AI幻觉陷阱
我国AI大模型应用正在快速增长。QuestMobile最新数据显示,DeepSeek上线次月(2025年2月),活跃用户规模突破1.8亿。然而,随着AI应用的普及,一些问题也逐渐浮现
2025-04-13 13:35:13媒体