李开复谈很多公司烧钱训练超大模型 应聚焦客户需求

DeepSeek的出现引发了全球热潮。在短短两个月内,一方面,许多公司如阿里巴巴和百度纷纷推出自己的AI大模型产品,有些甚至是开源的;另一方面,各行业都在寻找应用场景,希望利用DeepSeek以低成本、高效率的方式参与竞争。
在《金石财经》节目中,零一万物创始人李开复与主持人曾瀞漪讨论了企业如何有效利用大模型的问题。李开复表示,尽管DeepSeek表现出色且高效,但通用大模型虽然知识广泛却不够深入。它像一个聪明的大学毕业生,对特定公司的内部细节缺乏了解。例如,在进行战略分析或扮演公司角色时,如果未读取企业数据库或不了解企业文化,其表现可能不尽如人意。此外,DeepSeek丰富的想象力也可能导致产生较多幻觉。
为解决这些问题,需要增强模型对企业内部情况的理解,并减少其产生的幻觉。对于个人用户来说,DeepSeek已经非常好用,但在企业应用中仍需进一步优化。另外,企业往往重视数据安全,倾向于本地部署,避免敏感信息泄露给竞争对手。
蔡崇信提到当前AI产业存在泡沫现象,许多公司在没有明确方向的情况下投入大量资金。相比之下,接入成熟的模型并专注于满足客户需求可能是更明智的选择。李开复赞同这一观点,认为应将投资用于开发符合用户需求的功能而非盲目训练新模型。
面对AI带来的机遇,李开复建议企业CEO首先要认识到AI的重要性,思考错过技术革命的历史教训。其次,根据自身情况选择激进或保守策略,将核心业务引入AI领域或从人力资源等易于实施的环节入手。对于尚未完成数字化转型的企业,则需加快步伐,以便更好地融入大模型技术。

2026冬奥会火炬设计即将揭晓 经典瞬间预热体育盛事

40多年保护让朱鹮从7只到过万只 生态守护见证奇迹

神十九乘组即时反馈太空之家舒适度 问卷视频记录体验

美脱口秀告诫特朗普不要惹恼中国 提及《孙子兵法》警告

乌称俄袭击苏梅市 已致34人死亡 救援行动持续进行
神十九乘组即时反馈太空之家舒适度 问卷视频记录体验

聊城教师被指诱骗多名女生恋爱 发生性关系 涉事教师遭严肃处理

接亲玩跳绳游戏,调皮伴郎忽悠伴娘,虚晃一枪!
40多年保护让朱鹮从7只到过万只 生态守护见证奇迹

清华博士在中山造“脑机” 梦想走进现实
迈阿密0-0芝加哥集锦:梅西任意球两度中楣 苏牙痛失单刀 双方互交白卷

美防长威胁:如果谈判失败,美军已准备好确保伊朗永远不会拥有核武器 展示军事打击能力
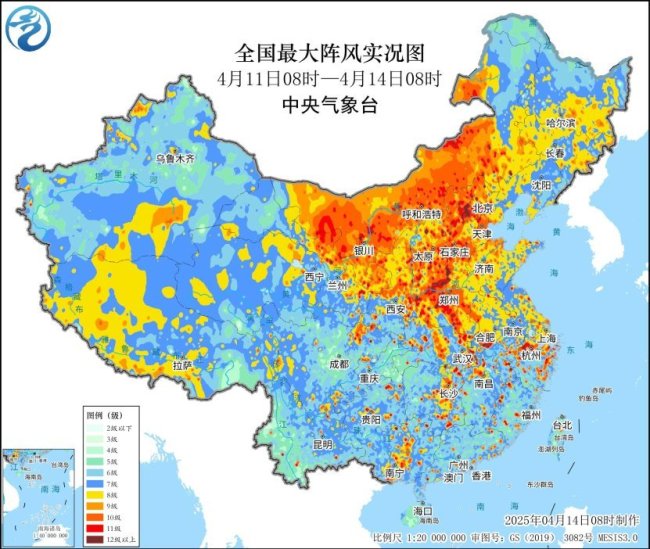
冷空气什么时候离开?接下来气温如何变化?

毛宁转发王毅霸气言论 彰显中国决心

台湾加权指数涨幅扩大至2% 盘初表现强劲

中国锻压协会发布关于加征关税声明 坚决反对贸易保护主义

乌克兰基辅市遭俄军无人机袭击:致3人受伤并引发火灾

美军将重返巴拿马前美军基地?巴反对派指责美方发动“伪装入侵” 引发民众反感与抗议

中越将开展第38次北部湾联合巡逻 增进两军合作

小心异常春困!多种疾病的前期症状与春困很像

大V:为防乌闪击布良斯克俄率先发难

美专家:特朗普关税损害美国际信誉 政策变化加剧不确定性

告别雪球,“中国巴菲特”暂停投资布道的秘密 长镜头

玉树地震15周年祭 铭记那场伤痛

如何看待乌军F-16战机被俄击落 神话破灭引发热议

乌方证实一飞行员已死亡 F-16战机被击落

A股三大指数齐上涨 创业板指领涨1.44%

哈登:季后赛就是要毫无保留 拼尽一切手段

美国对中国威胁最大的核潜艇力量信誉一落千丈,到底发生了什么?

租户没关窗隔断墙被吹倒 河南极端大风刮走整片落地窗
2026冬奥会火炬设计即将揭晓 经典瞬间预热体育盛事

美称中美已通过中间人就关税初步接触 中方坚决反对美方霸凌行径

18岁脑瘫少年坚持跑完10公里马拉松,跑到终点的那一刻他就赢了!

黄智贤:台湾唯一出路是统一

杨紫《家业》逛街路透,和美女们说说笑笑…
相关新闻
字节或损失千万美元 实习生恶意破坏模型训练
2024-10-21 08:23:46字节或损失千万美元马斯克谈DeepSeek xAI即将发布更强模型
2025-02-09 22:13:58马斯克谈DeepSeek布登谈比尔:他做了很多康复类的训练,听说他表现得非常好 恢复进展积极
2024-12-19 08:02:36布登谈比尔蚂蚁回应新模型训练降本 成本降低20%进展显著
3月24日,据知情人士透露,蚂蚁集团使用中国制造的半导体开发训练人工智能模型的技术,可将成本降低20%。对于这一消息,蚂蚁集团回应称,公司一直在针对不同芯片进行优化,以降低AI应用的成本
2025-03-25 07:59:34蚂蚁回应新模型训练降本Meta首席科学家谈DeepSeek爆火 开源模型胜出
本周,中国人工智能公司DeepSeek发布了其R1模型,这一消息在硅谷引起了广泛关注。第三方基准测试表明,该模型的表现超过了包括OpenAI、Meta和Anthropic在内的美国主要人工智能企业
2025-01-28 12:43:42Meta首席科学家谈DeepSeek爆火李开复谈企业如何把握AI带来的机遇 AI赋能传统企业转型
2025-03-26 10:00:21李开复谈企业如何把握AI带来的机遇







