DeepSeek发布V3模型更新 性能再升级

3月24日晚,DeepSeek发布了模型更新——DeepSeek-V3-0324。这次更新是DeepSeek V3模型的小版本升级,并非市场期待的DeepSeek-V4或R2。其开源版本已上线Hugging Face,模型体积为6850亿参数。

同日,DeepSeek在其官方交流群宣布,DeepSeek V3模型已完成小版本升级,欢迎用户前往官方网页、App和小程序试用体验。API接口和使用方式保持不变。

此前于2024年12月发布的DeepSeek-V3模型以“557.6万美金比肩Claude 3.5效果”的高性价比著称,多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上与世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。但截至目前,还没有关于新版DeepSeek-V3的能力基准测试榜单出现。
2025年1月,DeepSeek发布了性能比肩OpenAI o1正式版的DeepSeek-R1模型。该模型在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。
V3是一个拥有6710亿参数的专家混合模型(Moe),其中370亿参数处于激活状态。传统的大模型通常采用密集的神经网络结构,每个输入token都会被激活并参与计算,耗费大量算力。此外,传统的混合专家模型中,不平衡的专家负载是一个很大难题,会导致路由崩溃现象,影响计算效率。
为解决这个问题,DeepSeek对V3进行了大胆创新,提出了辅助损失免费的负载均衡策略,引入“偏差项”。在模型训练过程中,每个专家都被赋予了一个偏差项,它会被添加到相应的亲和力分数上,以此来决定top-K路由。此外,V3还采用了节点受限的路由机制,限制通信成本。通过确保每个输入最多只能被发送到预设数量的节点上,V3能够显著减少跨节点通信的流量,提高训练效率。
根据国外开源评测平台kcores-llm-arena对V3-0324的最新测试数据显示,其代码能力达到了328.3分,超过了普通版的Claude 3.7 Sonnet(322.3),可以比肩334.8分的思维链版本。

姆巴佩在法国队连续7场没能进球 陷入国家队生涯最长进球荒

女子突发脑干出血 儿子守在病床前:小时候你咋照顾我 我就咋照顾你

美军尼米兹号航母已前往西太 填补力量空白

章泽天近照曝光 与梁朝伟夫妇合影 破次元壁合影引热议

被称为“眼泪收割机”的《我会好好的》,让治愈系电影找到了新市场 年度最破防的治愈炸弹

特朗普不满其肖像画难看 要求撤走画像

美俄利雅得会谈结束 超12小时谈判成果待公布

俄军夺取查索夫亚尔西南城区,泽连斯基亲临哈尔科夫前线!乌军士气大振

佛山市场150元售老鼠干,多家商户均在售卖

拉夫罗夫最新涉华表态 中俄关系达前所未有的互信水平

中国球迷:期望在主场“喊赢”国足 近7万人助威声浪

杜特尔特寻求中国庇护?中方回应 私人行程无此事

留给李在明的时间不多了 政治梦悬一线
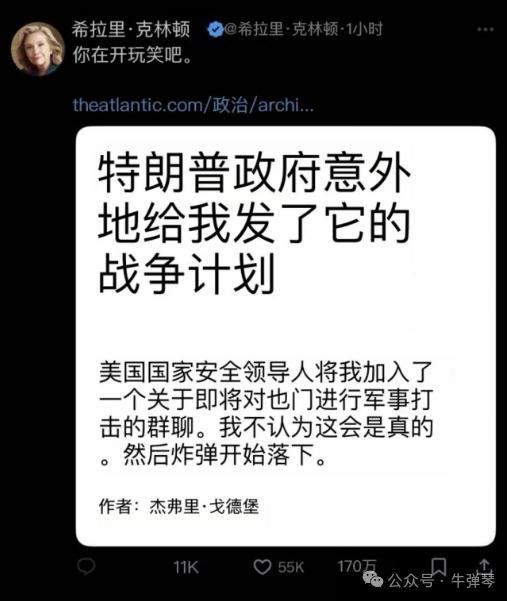
美国绝密战争计划 居然这样泄露了 超级乌龙事件曝光

英媒提醒称马斯克商业帝国危矣 竞争对手正紧追不舍
姆巴佩在法国队连续7场没能进球 陷入国家队生涯最长进球荒

千禧年零点出生的女孩猝死 年轻生命逝去引关注

“零添加” 争议再起!千禾味业接连回应,业绩压力仍是严峻挑战 股价止跌回升

代孕女孩植入胚胎时仅16岁!

泽连斯基办公室挂“克宫陷入火海”画作 俄外交部回应 引发激烈反应

女子称在北医三院遭医生猥亵 就医过程她感到强烈不适

外交部回应杜特尔特赴港传闻 私人度假行程
美军尼米兹号航母已前往西太 填补力量空白

叙利亚大马士革传出强烈爆炸声 原因不明震动城市

俄称马克龙的言论极其危险 核保护伞争议升温

你相信可以用吃减肥吗?答案来了

美国官员群聊袭击也门拉错了人 敏感信息外泄引发批评

特朗普宣布美新一代战机命名为F-47 接棒F-22成主力
女子突发脑干出血 儿子守在病床前:小时候你咋照顾我 我就咋照顾你
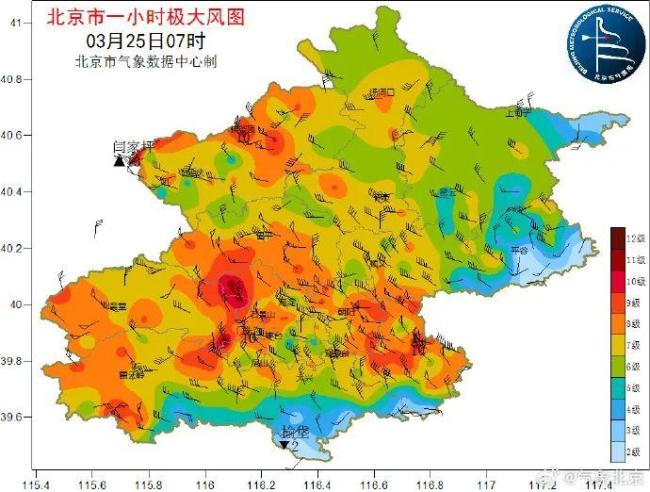
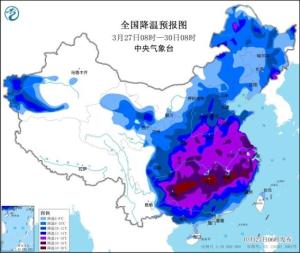
阵风10级以上,局地有扬沙!北京大风,傍晚减弱 早高峰注意防风安全

大V:泽连斯基或被迫接受国土沦丧 美俄谈判决定乌克兰命运

韩德洙复职 尹锡悦呢? 弹劾案宣判引焦虑

惠英红弹唱为谢霆锋宣传演唱会

青岛一饮品店推出蛤蜊奶茶 创意引发热议

国足上次主场赢澳大利亚是41年前 历史战绩回顾
相关新闻
马斯克谈DeepSeek xAI即将发布更强模型
2025-02-09 22:13:58马斯克谈DeepSeekDeepSeek发布新模型 Janus-Pro超越DALL-E 3
DeepSeek发布了新款开源多模态AI模型Janus-Pro。该模型在GenEval和DPG-Bench基准测试中表现优异,超越了OpenAI的DALL-E 3和Stable Diffusion
2025-01-28 09:17:49DeepSeek发布新模型英伟达平台上线DeepSeek 先进模型预览发布
2025-01-31 20:32:36英伟达平台上线DeepSeekDeepSeek上线国家超算互联网平台 多版本模型陆续更新
国家超算互联网平台已上线DeepSeek-R1、V3、Coder等系列模型。目前,DeepSeek-R1模型的1.5B、7B、8B、14B版本已经正式推出,预计近期还将更新32B和70B版本
2025-02-06 08:45:33DeepSeek上线国家超算互联网平台DeepSeek 模型需求更高算力
2025-03-20 14:24:42DeepSeek马斯克发布新模型 称能力超DeepSeek Grok 3亮相引发关注
2025-02-18 13:56:45马斯克发布新模型称能力超DeepSeek