“木头姐”谈DeepSeek启示 创新训练方法启发思考

大家好,我是很帅的狐狸。最近几天DeepSeek的消息引起了广泛关注。这家公司以极低成本训练出一个名为R1的模型,其性能甚至可以媲美OpenAI的顶级推理模型o1。这一消息导致英伟达股价下跌,市场开始质疑训练AI是否真的需要大量资金投入。
让我感到最有趣的是DeepSeek的训练方法。R1不同于普通的大语言模型,它具有一定的推理能力,可以通过增加“思维链”来提高答案质量,特别是在理工科题目上。传统上,要让大语言模型具备这种能力,通常是在基础模型上通过监督微调(SFT)来实现,类似于学生通过大量练习和参考答案学习解题方法。
然而,DeepSeek在训练R1-Zero时采用了强化学习(RL)的方法。这种方法更像婴儿的学习过程:通过不断的互动和反馈,逐渐学会新知识。例如,教婴儿识别颜色时,通过不断提问和反馈,婴儿最终能理解并记住颜色的概念。
强化学习一般用于游戏策略等复杂任务,因为它没有标准答案,有时会产生非常有创意的解决方案。2016年AlphaGo与李世石对战时,就下出了连职业棋手都看不懂的一手棋,这体现了强化学习的创造力。
这对我们有什么启发呢?我们在不熟悉的领域其实也像一张白纸,可以从零开始学习。比如我在麦肯锡做咨询时,发现许多金融行业的常见做法在其他行业却是创新。因此,跨领域的学习和思考可以帮助我们在不同领域找到新的解决方案。
此外,每天花些时间进行思考训练也是一个好方法。可以选择一个从未系统性思考过的问题,不限于工作相关,可以是跨行业的或生活方面的。这样的训练有助于开拓思路,激发创造力。

罗马诺:阿森纳在斯凯利和恩瓦内里的续约上取得不错的进展 图赫尔看好两人未来

18涨停大牛股,停牌核查 股价严重偏离基本面

已查处400余个饺子导演高仿号!片方:只有微博账号是真的

DeepSeek后又一杭州企业被美国盯上 杭州科创企业再遭美国打压!

库尔斯克决战在即,乌军掌握顿巴斯低空优势,欲断俄军前线补给 机械化突击行动升级

辽篮两将离开国家队绝非坏事 杨鸣终于等来他想要的:调整与机遇并存

乌克兰代表团抵达沙特 为泽连斯基访问做准备

缅甸政府军与德昂军进行会谈期间,瑙丘地区战事激烈,会谈期间战火未息
已查处400余个饺子导演高仿号!片方:只有微博账号是真的

马斯克曝光美国公务员薪资细节 引爆“数据核弹”

“重大转变”!俄罗斯与北约演习!外媒:白宫首次明确表态,乌将获准坐在桌旁 乌克兰参与和平谈判

美国务卿改口径 短暂删除“不支持台独”引发争议
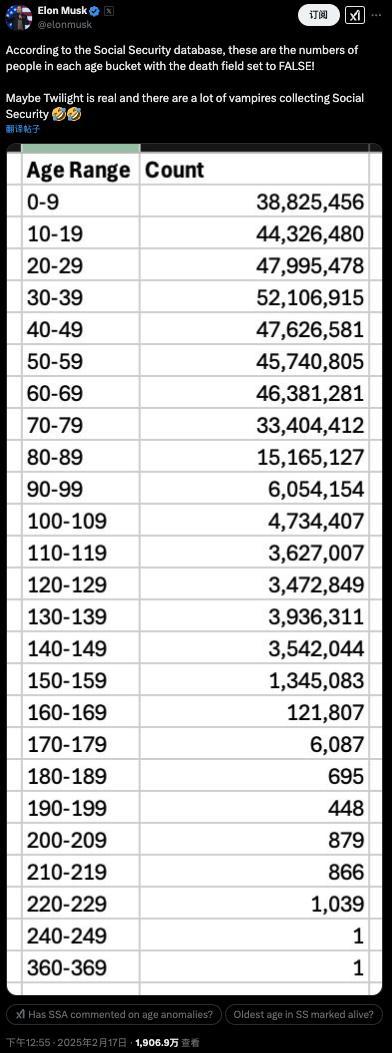
马斯克查账美国社保称发现360岁老人 马斯克曝光美国社保系统惊人漏洞
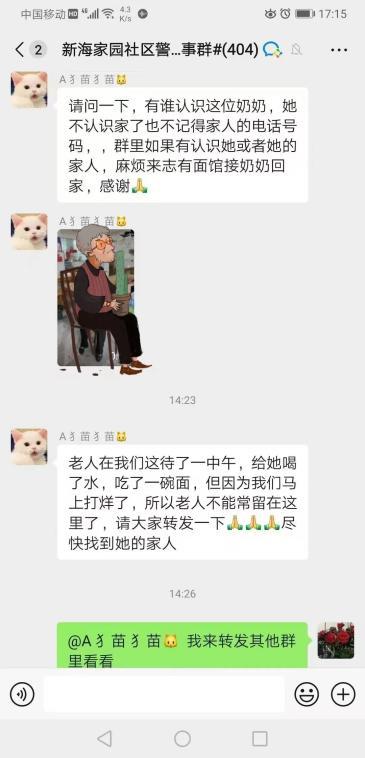
老人迷路后走进面馆 老板娘暖心送热水面条 温情举动获赞

新一轮以旧换新多地多重buff拉满 消费热潮再起

“一年雨水看雨水”今年雨水多不多?春雨贵如油

前马竞青训教练:巴里奥斯被罚下是因为犯错,但我们应保护他 支持年轻模范球员
18涨停大牛股,停牌核查 股价严重偏离基本面

美国客机机身翻覆已造成15人受伤 恶劣天气成事故主因

美国为何盯上乌克兰稀土资源 地缘博弈与资源攫取

记者买7件100%羊绒衫 实际1根羊绒都没有

95岁爷爷拄着拐杖给孙女送菜

马斯克为何敢整治美政府部门 AI引领政府效率革命

男性1.5米就能参军,色盲也能报名,台军新征兵标准有多离谱

外电:欧洲人“只是自己命运的旁观者” 无力参与谈判决策

乌方不承认美俄谈判达成协议,强调自身主权立场

巴萨重回西甲榜首 莱万点射助力登顶

专家:泽连斯基欲铲除波罗申科 为选举清除障碍

记者应该怎么用DeepSeek 真帮手还是挖坑侠?

巴尔德:对伊尼戈的犯规明显是点球 裁判争议再现
罗马诺:阿森纳在斯凯利和恩瓦内里的续约上取得不错的进展 图赫尔看好两人未来
迪丽热巴旗袍造型好清新 绿意盎然显气质

未来驰援国足 国青?17岁华裔新星世界波斩澳超首球!本人愿归化 潜力无限待绽放

又被刘晓庆圈粉了!

台名嘴:特朗普面对中国无计可施
相关新闻
DeepSeek爆火的启示 AI算命成新宠
最近,社交平台上涌现出大量关于AI算命的讨论。以DeepSeek为代表的AI算命在年轻人中掀起了一股热潮,成为他们在应对婚恋、职场等压力时的“救命稻草”
2025-02-16 19:52:04DeepSeek爆火的启示冯骥谈DeepSeek 国运级科技成果
1月26日晚,游戏科学创始人、CEO冯骥发文谈到了DeepSeek,称其可能是一个国运级别的科技成果。他认为,如果有一个AI大模型能做到以下任何一条,都是了不起的突破,而DeepSeek全部实现了
2025-01-27 09:45:58冯骥谈DeepSeekDeepSeek爆火的启示:中国如何培植创新基因? 市场化创新的成功案例
2024年1月20日,中国量化基金公司幻方发布的人工智能大模型DeepSeek-R1在全球科技界引起轰动
2025-02-18 05:39:09DeepSeek爆火的启示木头姐:比特币2030年将破100万美元 长期看好不变
2024-12-20 20:27:30木头姐简讯|习近平谈中美关系四年来的经验与启示
新华社利马11月16日电 当地时间11月16日下午,国家主席习近平在利马同美国总统拜登举行会晤。习近平说:过去4年的经验值得总结、启示需要记取,我认为至少有以下几条。
2024-11-17 09:48:35简讯|习近平谈中美关系四年来的经验与启示特朗普就职典礼伴奏故障 木头姐救场 乡村歌手带头清唱
特朗普就职典礼上出现意外,乡村女歌手凯莉·安德伍德在准备演唱美国著名爱国歌曲《美丽的阿美利加》时,伴奏突然故障无法播放。在等待了近1分半钟后,安德伍德决定直接清唱,并带领全场一同歌唱,成功救场
2025-01-22 01:18:33特朗普就职典礼伴奏故障木头姐救场