全球掀DeepSeek复现狂潮 硅谷巨头神话崩塌!

硅谷正经历由中国公司引发的重大变革。全美都在担忧全球人工智能的中心是否已经转向中国。此时,全球范围内掀起了复现DeepSeek模型的热潮。正如LeCun所说:“这是开源对闭源的一次胜利。”这些讨论引发了人们对数百亿美元支出必要性的质疑,甚至有人预测中国量化基金可能会导致纳斯达克崩盘。
未来,大模型时代可能进入一个分水岭:高性能模型不再仅限于算力巨头,而是每个人都能拥有。UC伯克利博士生潘家怡及其团队在CountDown游戏中复现了DeepSeek R1-Zero,结果令人满意。实验表明,通过强化学习,3B的基础语言模型也能自我验证和搜索,成本不到30美元即可见证“啊哈”时刻。该项目名为TinyZero,采用R1-Zero算法,给定基础语言模型、提示和真实奖励信号后运行强化学习。模型从简单输出开始,逐步进化出自我纠正和搜索策略。
消融实验中,研究人员使用了Qwen-2.5-Base的不同参数规模(0.5B、1.5B、3B、7B)。结果显示,0.5B模型只能猜测解决方案,而从1.5B开始,模型学会了搜索、自我验证和修正解决方案,从而获得更高分数。研究还发现,额外的指令微调并非必要,这支持了R1-Zero的设计决策。此外,具体的RL算法并不重要,PPO、GRPO、PRIME等算法都能带来不错的性能表现。
港科大助理教授何俊贤的团队仅用8K样本,在7B模型上复现了DeepSeek-R1-Zero和DeepSeek-R1的训练,取得了显著成果。他们在AIME基准上实现了33.3%的准确率,在AMC上为62.5%,在MATH上为77.2%。这一表现不仅超越了Qwen2.5-Math-7B-Instruct,还能与使用更多数据和复杂组件的PRIME和rStar-MATH相媲美。他们使用纯PPO方法训练Qwen2.5-7B-SimpleRL-Zero,并采用MATH数据集中的8K样本。Qwen2.5-7B-SimpleRL则先进行Long CoT监督微调,再进行强化学习。两种方法都只使用相同的8K MATH样本。在第44步时,模型出现了自我反思能力,并表现出更长的CoT推理能力。
HuggingFace团队也宣布复刻DeepSeek R1的所有流程,并将所有训练数据和脚本开源。项目命名为Open R1,发布一天内获得了超过1.9k星标和142个fork。DeepSeek的成功使其成为美国顶尖高校研究人员的首选模型,甚至取代了一些人对ChatGPT的需求。这次,中国AI确实震撼了世界。

爱德华兹:我是文班亚马的忠实粉丝 NBA新门面闪耀全明星

央视直播乒乓球亚洲杯2月19日至23日赛程 国乒12人出战力争双冠
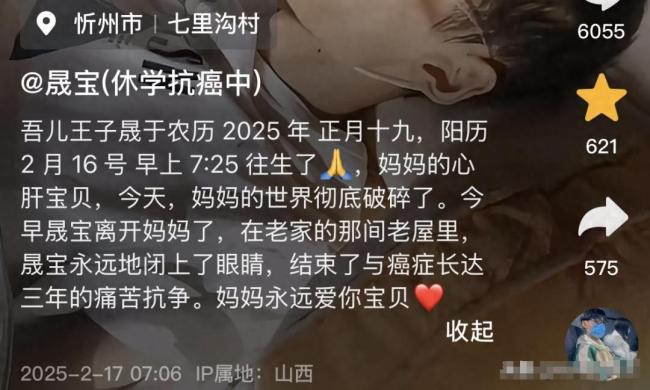
18岁抗癌博主晟宝去世 三年抗争终落幕

俄代表:欧盟英国“完全不守信用” 质疑其未来协议参与资格
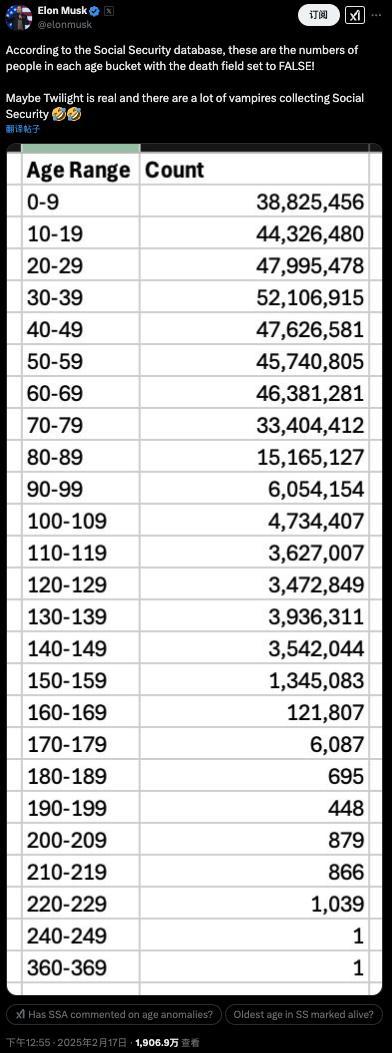
马斯克查账“美国社保”,称发现360岁老人?
央视直播乒乓球亚洲杯2月19日至23日赛程 国乒12人出战力争双冠

美国新版“空军一号”再度延期交付 供应链问题拖累进度

“东数西算”发挥了怎样的关键作用 助力影视渲染革新

为了增加军费,英国公共服务部门被曝准备削减11%的预算,欧洲派兵计划陷入僵局

周深佩戴珠宝细节 舞台形象引热议

尹锡悦被弹劾或板上钉钉 政坛风云再起

伊朗:反对外国势力干涉叙利亚 支持叙人民自决权

欧洲的安全,还是美国的利益?美俄谈判前夕,欧洲被边缘化引发担忧

台北市议员:特朗普想要台积电的命 担忧核心技术外流

12.4亿美元买“酒”!巴菲特,释放了什么信号? 加码消费股布局
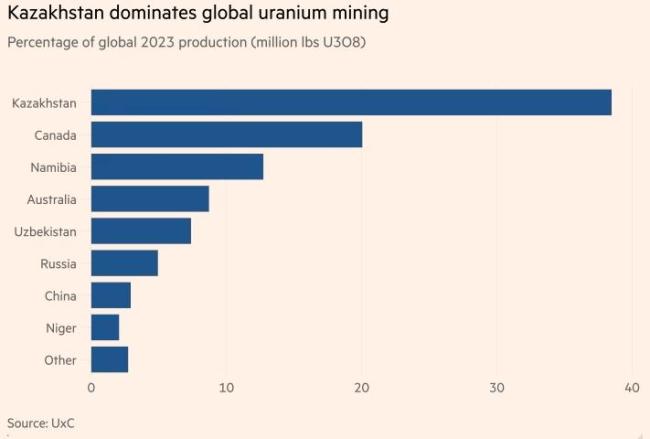
哈萨克斯坦铀出口重心东移 哈铀售中俄后致欧美快断供了

小车溜车小伙飞奔帮忙拽车 网友:这一幕真的很帅
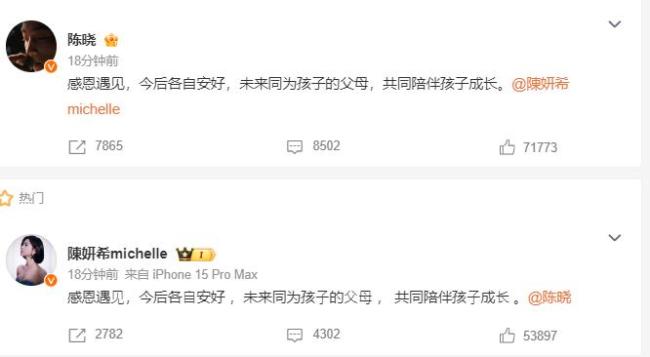
陈晓陈妍希头纱吻已成过去 九年婚姻终落幕

美国翻脸后,欧洲从“夸夸其谈的少年”走向独立成熟要做三件事 应对三大危机

特朗普批波音总统专机还没造好 项目拖延引不满

多名官员被解雇后起诉美政府 裁员争议升级

直播间卖仿品11名被告人受惩 售假产业链曝光
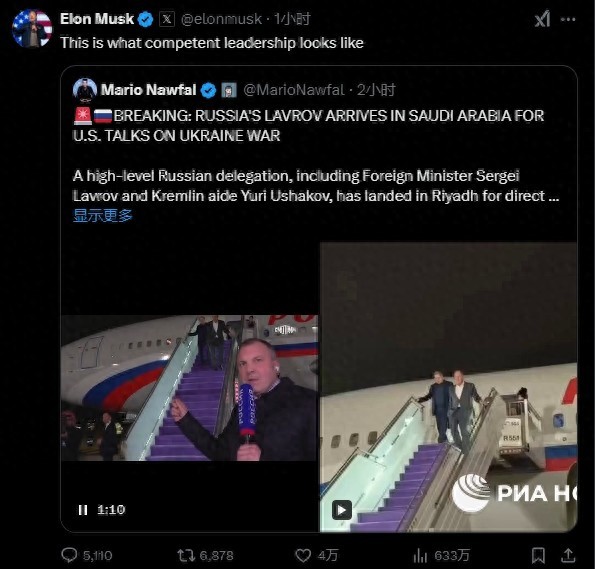
美俄谈判今日开始 泽连斯基:不承认 乌克兰缺席引发争议

泽连斯基将到访沙特 不参与美俄会谈
18岁抗癌博主晟宝去世 三年抗争终落幕

美国顶尖高校宣布暂停招聘 财政压力下的断臂求生

陈晓陈妍希上次同框已是近2年前 官宣离婚引发关注
爱德华兹:我是文班亚马的忠实粉丝 NBA新门面闪耀全明星

野猪频频“撒野”遇到了怎么办 应对策略与法律边界

泰22岁女模特疑遭男子强迫吸毒致死 涉事中国顾客试图私了

马斯克发布智能搜索引擎 开启全民智能问答新时代

日本侵华照片让马库斯震惊气愤 家族见证历史伤痛
谢霆锋演唱会门票被黄牛炒至17万 一票难求引发热议

血液病学专家吴谨绪教授离世 医界巨星陨落

被颖儿在《六姊妹》里的何家艺圈粉啦!颖儿新剧不是恋爱脑是搞钱脑
相关新闻
DeepSeek 引发全球热议的神秘力量
2025-02-02 11:56:34DeepSeekDeepSeek掀算力革命 推动国产AI芯片发展
幻方量化旗下的人工智能公司深度求索(DeepSeek)于2025年1月20日发布了DeepSeek-R1,该模型性能对标OpenAI的o1正式版,引发了全球关注
2025-02-07 12:10:50DeepSeek掀算力革命实测DeepSeek做奥数题写作文 DeepSeek火爆全球
2025-01-27 20:13:31实测DeepSeek做奥数题写作文DeepSeek掀起算力新范式 低成本训练引领变革
2025-01-27 19:43:28DeepSeek掀起算力新范式DeepSeek刷屏全球 现象级产品崛起
今年春节,国产大模型DeepSeek在全球范围内迅速走红。短短一周内,该应用不仅登上了美国和中国区App Store免费榜的榜首,还成为首个超越OpenAI ChatGPT的AI助手类应用
2025-02-12 15:41:17DeepSeek刷屏全球多国给DeepSeek使用设限 数据安全引发全球关注
2025-01-30 19:34:04多国给DeepSeek使用设限







