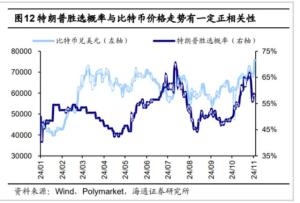
李彦宏戳破大模型跑分假象 真能力在于用户价值增益

李彦宏戳破大模型跑分假象
新版本大模型的问世常伴随着与GPT-4的性能对比热潮,企业热衷于展示自家模型在第三方榜单上的亮眼成绩,强调在特定指标上已实现赶超,意在彰显其技术实力的飞跃。然而,百度董事长李彦宏近期在内部交流中揭示了这一现象背后的真相。他指出,尽管某些模型在部分单项上得分超越GPT-4,但这并不意味着它们与最前沿技术的差距已消失。李彦宏强调,模型间的差异是多方面的,涵盖基础能力如理解、生成、逻辑推理及记忆等多个层面,同时也涉及成本效率,即某些模型虽效能相似,但高昂成本和较慢的推理速度使其总体上仍逊色于先进模型。
李彦宏还提到了测试集中常见的“过拟合”问题,即模型过度适应训练数据,导致在未见过的数据上表现欠佳。这种现象反映出模型可能过于复杂,以至于捕捉到了训练数据中的非普遍性特征,从而限制了其泛化能力。尽管如此,跑分榜单仍具有一定的参考价值,它不仅提供了量化评估模型性能的快捷方式,也促进了技术竞争与进步,激发了模型优化的动力。
李彦宏提醒,自媒体的炒作和新模型发布时的宣传倾向,可能会误导公众认为各模型间的能力差距正日益缩小,实际情况却并非如此。他主张,真正检验大模型能力的标准应在于其能否在具体场景下满足用户需求并创造价值,而非简单的排名比拼。对于业界常说的“领先12个月或落后18个月”的时间差,李彦宏认为其重要性被高估,强调持续创新与市场需求响应速度才是决定市场份额的关键。
展望未来,李彦宏预测大模型间的性能差距或将扩大,因大模型的发展空间广阔,且需持续迭代升级以降低成本、提高效率。此外,他还就开源与闭源模型、AI代理等议题分享了见解,认为在商业领域,闭源模型凭借高效的资源利用和成本分摊机制,较开源模型更具优势。至于大模型的应用进展,李彦宏描绘了一条从辅助工具到具备自主性乃至独立工作能力的AI工作者的发展路径,并指出当前智能体虽受关注但尚未成为普遍共识,尽管其低门槛特性使其成为模型应用的一种简便途径。

NBA季前赛:公牛16分逆转骑士拉文复出仅7分 吉迪加盟首秀11 7 - 公牛末节锁定胜局

不足30天,美国大选进入冲刺阶段:“十月惊奇”会否再现?摇摆之地选情胶着

2024武网开幕 郑钦文亮相 网球盛宴再度开启
NBA季前赛:公牛16分逆转骑士拉文复出仅7分 吉迪加盟首秀11 7 - 公牛末节锁定胜局

尹锡悦初会石破茂 穿梭外交谱新篇

以色列空袭叙利亚首都居民楼 造成7死11伤

伊朗外长敏感时刻访问沙特,将讨论地区问题并制止以色列“罪行”

山东一景区“跟着团长打县城”项目爆火

美军MQ-9“死神”无人机为什么接连被胡塞武装击落?

黄晓明女友叶珂:爸爸不让我信男人,#婚姻情感记#下的选择

战火下,近10万黎巴嫩人逃到叙利亚
不足30天,美国大选进入冲刺阶段:“十月惊奇”会否再现?摇摆之地选情胶着
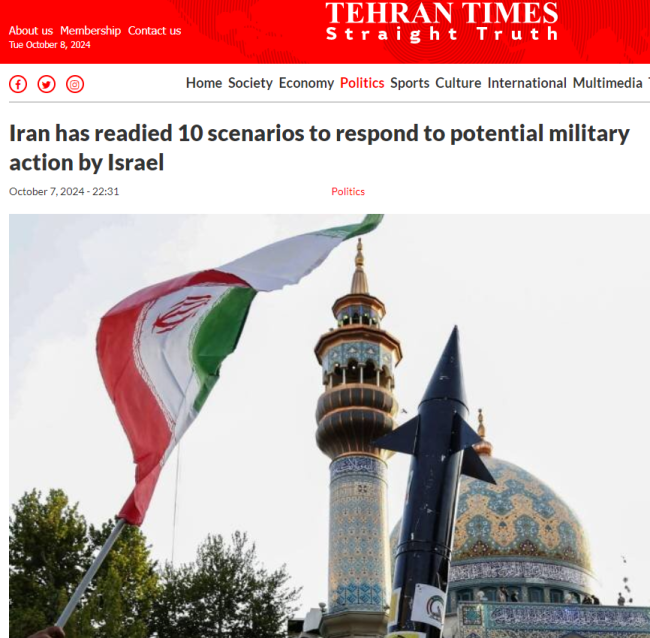
“已制定至少10种方案”,伊朗应对以色列袭击,可能怎么办?

以总理提议将以军“铁剑”行动改名为“复兴战争”

健康三球太强势:24 6 5还献两记超远三分 豪言成攻防一体PG 剑指全明星

市监局回应外卖肉夹馍中吃到针头 源头调查进行中

他救人拦下的救护车救了自己 爱心传递,民警获救

黎真主党警告以色列:若继续袭击黎巴嫩,将加强对以打击
2024武网开幕 郑钦文亮相 网球盛宴再度开启

《七夜雪》今晚开播 邵羽柒化身秋水音诠释别样情感江湖

美媒曝:黎巴嫩大量通讯设备爆炸前,受害者被引导“用两只手同时操作设备以读取信息”

台媒爆料:台军“导弹发射筒”流入黑帮

测试投弹出现故障?防止泄密主动击落?俄神秘无人机坠毁乌克兰引猜测
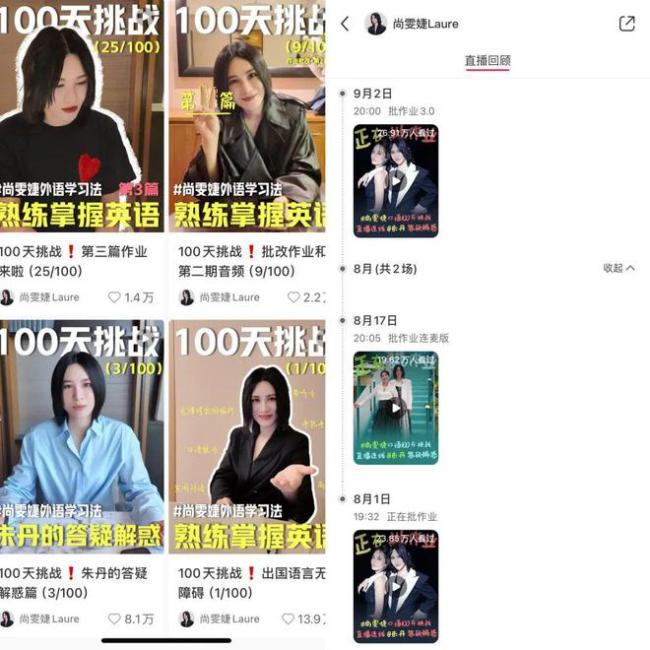
5篇笔记涨粉35万,“劝学”成小红书新流量密码

美军火商虚报对台军售费用,台当局回应
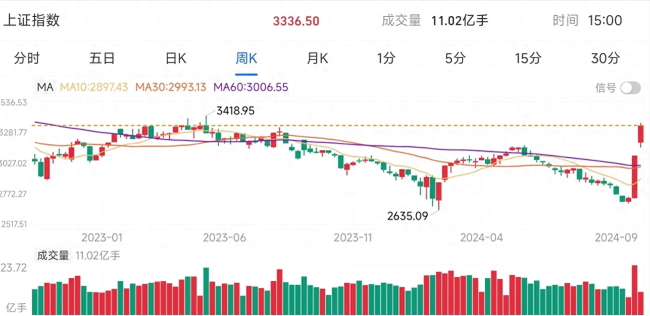
A股大跌预警:但斌警示市场 或迎剧烈调整

上海马路股市沙龙又热闹了!

以媒:自新一轮巴以冲突爆发以来,以色列共有728名军事安全人员在冲突中死亡

美媒:美官员透露,近几周拜登政府愈加不信任以方涉军事和外交计划言论

陈乔恩回应被催生:生孩子很重要吗 个人选择受尊重

美媒:内塔尼亚胡“最后一刻”否决以防长访美行程,再次表明“双方关系紧张”
这下奇怪了,俄军为何要……

假期出游易丢手机 广州一游乐场已捡15部手机

以色列总理称:已打死纳斯鲁拉的继任者、他的继任者的继任者

女子回应收了巨额礼物拉黑追求者被指玩弄感情:我和他说了无数次“你养不起我”
相关新闻
李彦宏:大模型百度走在最前面,我们要去勇闯无人区
5月11日,百度举行了一场内部颁奖活动。其间,公司创始人、董事长兼首席执行官李彦宏表达了对技术创新的坚定信念。他提到,百度在探索大型模型领域处于领先地位,正勇敢踏入无人区,敢于承担前所未有的风险
2024-05-11 09:03:42李彦宏:大模型百度走在最前面李彦宏妻子套现2241万美元 百度股价波动引关注
2024-08-01 08:06:42李彦宏妻子套现2241万美元李彦宏内部评璩静风波 百度价值观坚守与革新
2024-05-10 10:02:59李彦宏内部评璩静风波李彦宏点评璩静事件:优秀员工才代表真实的百度!
2024-05-10 10:01:06李彦宏:优秀员工才代表真实的百度李彦宏和雷军的殊途同归 智驭未来汽车变革
2024-07-23 06:14:36李彦宏和雷军的殊途同归李彦宏内部评璩静风波:优秀员工才代表真实的百度
2024-05-10 10:19:41李彦宏内部评璩静风波