还不如人类五岁小孩,难度为零的视觉测试,GPT-4o却挑战失败了

还不如人类五岁小孩,难度为零的视觉测试,GPT-4o却挑战失败了
近期的研究探讨了GPT-4o、Claude 3.5 Sonnet等视觉语言模型(VLM)在图像理解方面的能力。尽管这些先进的模型在处理人类行为识别、物品识别等复杂场景时表现出色,但在一系列基础视觉任务上的表现却差强人意。研究通过7项涉及基本几何形状的任务测试发现,这些VLM的平均准确率仅有56.2%,显示出它们更像是基于线索推测而非真正“观看”。相关论文以“Vision language models are blind”为标题,已在arXiv网站发布。
研究中,即便是辨认线条交叉点数量、圆圈是否重叠这类对人类来说极为直观的任务,VLM的完成度也并不理想。比如,在识别交叉线数量时,最高准确率不过77.33%,且随着线条间距缩小,其性能下滑。同样,判断圆圈重叠时,没有模型能达到完美,且圆圈间距减小时,错误率增加,表明VLM在捕捉细微差异上存在困难。
此外,VLM在识别被圈定字母、重叠形状数量等任务上的表现亦暴露出不足。它们虽然能够正确拼写被圈字母所在的单词,却难以准确指出被圈的究竟是哪个字母,有时还会错误地生成不存在的字符。在计数重叠或嵌套的几何图形时,模型往往依赖训练数据中的常见模式(如奥运五环标志)进行猜测,导致准确性受限。
值得注意的是,VLM在识别网格的行列数以及计算单色路径数量的任务上也面临挑战,仅在加入辅助信息(如网格内填充文本)后,其表现才有所提升,但仍远未达到完美。这暗示着VLM在无文本辅助的纯粹视觉推理上存在局限。
研究者认为,当前VLM采用的晚期融合方法可能是其视觉理解能力受限的关键因素,未来的研究或许应探索早期融合策略,即在模型处理的更早阶段结合视觉和语言信息,以期提升其图像理解的精准度。此外,针对特定任务对模型进行微调也被视为一个潜在的研究方向,旨在培养出在视觉理解上更为高效的VLM。
还不如人类五岁小孩,难度为零的视觉测试,GPT-4o却挑战失败了。

乃万自曝玩乙游被骂上热搜,本人发长文回怼:我没特权我就是爱玩

现在KTV已经进化到自己演MV了

盲人玩家听声辨位玩黑神话 挑战游戏边界

“不死鸟”的后代:漫谈美海军列装新超远程空空导弹
菲律宾,要为美国两肋插刀了

重返马德里! 前皇马10号回归西甲, 美洲杯1球6助攻, 4年被5队舍弃

应对库尔斯克战局,俄国防部组建三大集团军

以色列代表埃尔丹再出暴论:应把联合国大楼从地球上抹去

英超夏窗最后9天! 4年0进球, 曼联22岁天才离队, 切尔西赶斯特林

2比0!中国金花爆发,75分钟5破发横扫法网八强,首进500赛八强

印度法院裁决汉堡王是一个印度品牌

新建三个集团军巩固防线,正逼近乌东部关键枢纽,俄整合更多部队阻击乌军

曼联官宣两人转会,佩里斯特里800万合同曝光!青训小妖续签长约

联合国称加沙地带仅剩下11%的区域供巴民众生存

布林肯结束中东之行,未能推动加沙停火协议达成

日印“2+2”对话硬扯中国,专家:两国有权深化双边关系,但不应针对第三方

俄海军“瓦良格”号编队返航通过第一岛链,远航已满7个月

杭州警方通报街道强奸案:系已立案侦办的刑事案件

白宫:拜登与内塔尼亚胡通话,强调达成加沙停火和释放人质协议“紧迫性”

巴萨引进奥尔莫,放弃京多安,又让球迷想起了格里兹曼

魏牌全新蓝山正式上市 智驭未来,全家尽享科技豪华
现在KTV已经进化到自己演MV了

中国残奥代表团今日出征 Kimi助我准时下班

人山人海热烈欢迎!孙颖莎回河北老家曝光,打卡正定古城好热闹

中方驳斥美翻炒“中国核威胁论”:美国才是全球最大的核威胁、战略风险的制造者

俄军新建三个集团军,准备怎么用?
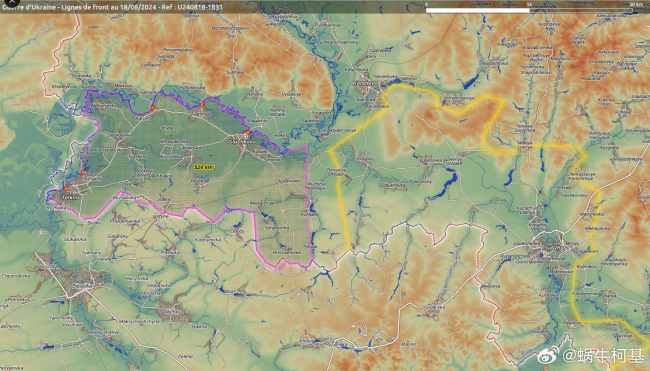
乌军进攻库尔斯克 让俄军加速进攻顿涅茨克

俄乌就谈判问题激烈交锋:俄外长称目前不可能恢复对话,乌总统称正在实现战略目标

记者: 曼联小将菲什接近转会卡迪夫城, 奥耶德莱接近转会华沙军团

乌军又发视频称摧毁俄军在塞姆河修建的浮桥,美媒:是个强烈信号
乃万自曝玩乙游被骂上热搜,本人发长文回怼:我没特权我就是爱玩
盲人玩家听声辨位玩黑神话 挑战游戏边界

机器鹰、机器鱼……军用仿生机器人崭露头角

处暑亦为出暑,是秋季的第二个节气

外媒:曼联最初对佩利斯特里要价1500万欧,如今仅为600万欧
相关新闻
张远挑战孙楠难度颇高引热议 他挑战孙楠失败了
张远是本期节目的冲榜歌手,作为出道多年的歌手,他终于登上了梦寐以求的舞台。他也挺敢的,直接向孙楠发起挑战,一首《说谎》满满的感情。
2024-06-21 22:29:41张远挑战孙楠GPT-4o深夜炸场!AI实时视频通话丝滑如人类!
OpenAI在5月14日凌晨发布了其最新的旗舰AI模型GPT-4o,该模型标志着AI技术的一个重要里程碑,并计划推出PC桌面版ChatGPT
2024-05-14 09:22:27GPT-4o深夜炸场!AI实时视频通话丝滑如人类为什么说GPT-4o并不惊艳? 多维度测试揭示局限性
5月14日凌晨,OpenAI推出了GPT-4o,这款新模型集成了听觉、视觉与语言处理能力,能够实时分析音频、视觉及文本信息,并以任意组合方式输出文本、音频或图像内容
2024-05-16 15:57:44为什么说GPT-4o并不惊艳?Open新模型:丝滑如真人,GPT-4o引领交互革命
在5月14日的线上“春季更新”活动中,美国OpenAI公司揭晓了其新旗舰模型——GPT-4o,标志着在人机交互领域的重要进展
2024-05-14 08:06:10Open新模型:丝滑如真人又一次失败!无冠魔咒继续困扰凯恩,还不如西班牙队17岁的小孩 凯恩冠军梦碎
2024-07-15 11:53:54又一次失败!无冠魔咒继续困扰凯恩OpenAI新模型:丝滑如真人,GPT-4o引领交互新时代
5月14日深夜,美国OpenAI公司举办线上“春季更新”活动,揭晓两大核心内容:发布最新旗舰模型GPT-4o及在ChatGPT服务中增添多项免费功能
2024-05-14 07:49:16OpenAI新模型:丝滑如真人