GPT-4被曝缓存历史回复 一个笑话讲八百遍,让换新的也不听

丰色发自凹非寺
量子位|公众号QbitAI
有网友找到了GPT-4变“笨”的又一证据。
他质疑:
OpenAI会缓存历史回复,让GPT-4直接复述以前生成过的答案。
最明显的例子就是讲笑话。
证据显示,即使他将模型的temperature值调高,GPT-4仍重复同一个“科学家与原子”的回答。
就是那个“为什么科学家不信任原子?因为万物都是由它们编造/构造(make up)出来的”的冷笑话。
在此,按理说temperature值越大,模型越容易生成一些意想不到的词,不该重复同一个笑话了。
不止如此,即使咱们不动参数,换一个措辞,强调让它讲一个新的、不同的笑话,也无济于事。
发现者表示:
这说明GPT-4不仅使用缓存,还是聚类查询而非精准匹配某个提问。
这样的好处不言而喻,回复速度可以更快。
不过既然高价买了会员,享受的只是这样的缓存检索服务,谁心里也不爽。
还有人看完后的心情是:
如果真这样的话,我们一直用GPT-4来评价其他大模型的回答是不是不太公平?
当然,也有人不认为这是外部缓存的结果,可能模型本身答案的重复性就有这么高:
此前已有研究表明ChatGPT在讲笑话时,90%的情况下都会重复同样的25个。
具体怎么说?
证据实锤GPT-4用缓存回复
不仅是忽略temperature值,这位网友还发现:
更改模型的top_p值也没用,GPT-4就跟那一个笑话干上了。
(top_p:用来控制模型返回结果的真实性,想要更准确和基于事实的答案就把值调低,想要多样化的答案就调高)
唯一的破解办法是把随机性参数n拉高,这样我们就可以获得“非缓存”的答案,得到一个新笑话。
不过,它的“代价”是回复速度变慢,毕竟生成新内容会带来一定延迟。
值得一提的是,还有人似乎在本地模型上也发现了类似现象。
有人表示:截图中的“prefix-match hit” (前缀匹配命中)似乎可以证明确实是用的缓存。
那么问题就来了,大模型到底是如何缓存我们的聊天信息的呢?
好问题,从开头展现的第二个例子来看,显然是进行了某种“聚类”操作,但具体如何应用于深度多轮对话咱不知道。
姑且不论这个问题,倒是有人看到这里,想起来ChatGPT那句“您的数据存在我们这儿,但一旦聊天结束对话内容就会被删除”的声明,恍然大悟。
这不禁让一些人开始担忧数据安全问题:
这是否意味着我们发起的聊天内容仍然保存在他们的数据库中?
当然,有人分析这个担忧可能过虑了:
也许只是我们的查询embedding和回答缓存被存下来了。
因此,就像发现者本人说的:
缓存这个操作本身我不太担心。
我担心的是OpenAI这样简单粗暴地汇总我们的问题进行回答,毫不关心temperature等设置,直接聚合明显有不同含义的提示,这样影响很不好,可能“废掉”许多(基于GPT-4的)应用。
当然,并不是所有人都同意以上发现能够证明OpenAI真的就是在用缓存回复。
他们的理由是作者采用的案例恰好是讲笑话。
毕竟就在今年6月,两个德国学者测试发现,。
像“科学家和原子”这个更是尤其出现频率最高,它讲了119次。
因此也就能理解为什么看起来好像是缓存了之前的回答一样。
因此,有网友也提议用其他类型的问题测一测再看。
不过作者坚持认为,不一定非得换问题,光通过测量延迟时间就能很容易地分辨出是不是缓存了。
最后,我们不妨再从“另一个角度”看这个问题:
GPT-4一直讲一个笑话怎么了?
一直以来,咱们不都是强调要让大模型输出一致、可靠的回答吗?这不,它多听话啊(手动狗头)。
所以,GPT-4究竟有没有缓存,你有观察到类似现象吗?

焦裕禄次子焦跃进逝世 享年66岁!

“五线明星还摆什么谱” 王骁路演被骂影院致歉

最高检为《第二十条》连发两篇影评
诬陷中国网攻、给乌克兰F-16,荷兰为啥成了急先锋?

改进型苏-57将服役,或成最快超音速战斗机

全国统一的春节噩梦,两个字

媒体:中东的形势变了

美军方:遭袭基地未能发现来袭无人机,也没有能击落无人机的武器

新姑爷第一次上门 不料压塌老丈人床热 然而,事情并未就此结束

你收到的情人节玫瑰99%是假的!
制造地区紧张气氛?驻日韩美军演练应对“大规模伤亡”

多次“担忧”中国船只研究活动,印度为何力阻中国科考船进印度洋?

日记者观摩日美大规模海上军演,中国侦察舰抵近美航母
最高检为《第二十条》连发两篇影评

五路财神都有谁热 他们分别代表着不同的财运和财富,深受人们的敬仰和崇拜

贾玲雷佳音带爸爸客串热辣滚烫 为故事增添了更多的温情与真实

坎贝尔出任美副国务卿,美媒:主张与华竞争而非对抗

西方对俄罗斯能源制裁到底坑了谁?

俄军事专家:扎卢日内“颂扬”俄军是“烟幕弹”

《我们一起摇太阳》将退出春节档热 2月15日为该片在春节档上映的最后一天
焦裕禄次子焦跃进逝世 享年66岁!

乌军转向混合战略,拟对俄境内展开大规模无人机攻击
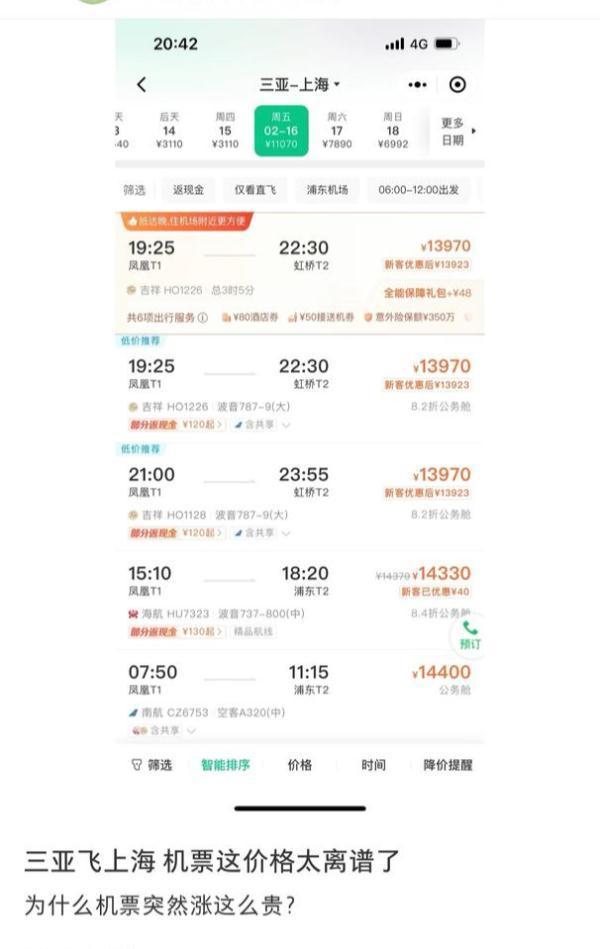
出岛机票紧张票价过万 海南官方回应:建议避免从三亚直飞

五台山景区桶装水是从厕所水管接的?景区:平时也喝这个 将改善相关设施

一觉醒来,巴格达告急

视觉盛宴!八一飞行表演队亮相沙特国际防务展

力阻中国科考船进印度洋,印度到底在怕啥?

日本又搅弄是非!

内塔尼亚胡反对!布林肯与以军参谋长单独会晤被取消

“钱辈”请和我交往热 初五寺庙打卡热,大批年轻人喊话财神爷

“冲突至今最严重!”

张艺谋刘德华都打不过熊出没热 春节档黑马电影征服全年龄段

乌称击沉俄黑海舰队大型登陆舰 “凯撒·库尼科夫”号
“五线明星还摆什么谱” 王骁路演被骂影院致歉

农村老人沉迷刷APP挣钱:一天看七小时才赚两三块
相关新闻
马化腾回应早期微信“偷窥”用户相册:图片缓存加速造成的误会
针对早前微信被爆在后台反复读取用户相册的事件,1月5日,马化腾回应称:“应该是21年10月的事了,图片缓存加速造成的误会,后面应该用iOS新的解决卡顿的API解决了。
2024-01-08 11:23:45马化腾谈早期微信“偷窥”相册苏有朋回复舒淇 妈妈说 美丽的女人都会吓人
苏有朋转发回复舒淇:“妈妈说美丽的女人都会吓人而且很吓” 都给咱有朋哥吓到模糊了
2023-11-23 11:01:19苏有朋回复舒淇民政部回复龙年不宜结婚:荒唐迷信 没有科学依据
原标题:没有立春是“寡妇年”,不宜结婚?官方回应近日,有网友在民政部官网上留言,建议民政部或其他部委联合发文,引导居民不受迷信影响龙年正常结婚。
2024-01-25 08:03:47民政部回复龙年不宜结婚林俊杰回复Angelababy 两人曾合作《可惜没如果》
原标题:林俊杰回复Angelababy引发网友狂欢,两人友情超甜近日,歌手林俊杰在微博上回复了演员Angelababy的一条评论,引发了网友们的热烈讨论和关注。
2023-08-21 13:26:25林俊杰回复Angelababy微视频|铭记历史 吾辈自强
2023-08-15 22:00:45微视频|铭记历史官方回应冰雪大世界主持人疑打广告“会有确切回复”
官方回应冰雪大世界主持人疑打广告1月14日,有网友发布视频称,哈尔滨冰雪大世界大舞台“感觉变味道了”,主持人在节目中疑似多次植入广告,感觉非常影响游玩体验,建议取消。
2024-01-15 15:51:18官方回应冰雪大世界主持人疑打广告








